
LRU(Least Recently Used) 是一种使用广泛的缓存数据替换策略,目的是在有限的内存空间中尽可能保留最有价值的缓存数据;其核心本意是,在资源出现不足时,剔除掉最近最少使用的数据,为新数据提供存放空间;
本文首先讲解了LRU算法,随后给出了LruCache的Rust实现;
源代码:
- https://github.com/JasonkayZK/boost-rs/blob/main/boost-rs/src/collection/linkedlist.rs
- https://github.com/JasonkayZK/boost-rs/tree/main/boost-rs/src/collection/cache
关联文章:
使用Rust实现链表LruCache
LRU算法
算法概述
在缓存容量有限的场景下,如果缓存满了就要删除一些内容,给新内容腾位置;但问题是,如何决定删除哪些内容呢?
LRU 的理念就是剔除掉最近使用最少使用的数据。 如果某份数据刚被使用,那么就认为它近期还可能被使用,且使用概率大于相对旧的数据,这和计算机的时间局部性内涵一致;最近最少使用的数据,应该为最近较多使用的数据让出空间;
概括来讲,LRU 是在资源有限的情况下,高效使用资源的一种策略,而这个策略的根基就是局部性原理;
LRU 的使用场景非常之多,以最为常见的 MySQL 为例:由于磁盘 IO 的读取效率远远低于内存操作,这使得数据库倾向于将大量数据直接加载在内存中进行操作,极力减少磁盘读取的次数;
算法实现
LRU 基于时间局部性进行数据淘汰,它用一个链表来追踪数据的时间局部性:
- 当一份数据当下被访问了,就将该数据移动到链表的头部,链表从头到尾的顺序,相当于按照最近的访问时间对数据排序;
- 当需要淘汰数据时,就将链表尾部的数据直接剔除,将需要新加入的数据插入链表的头部;
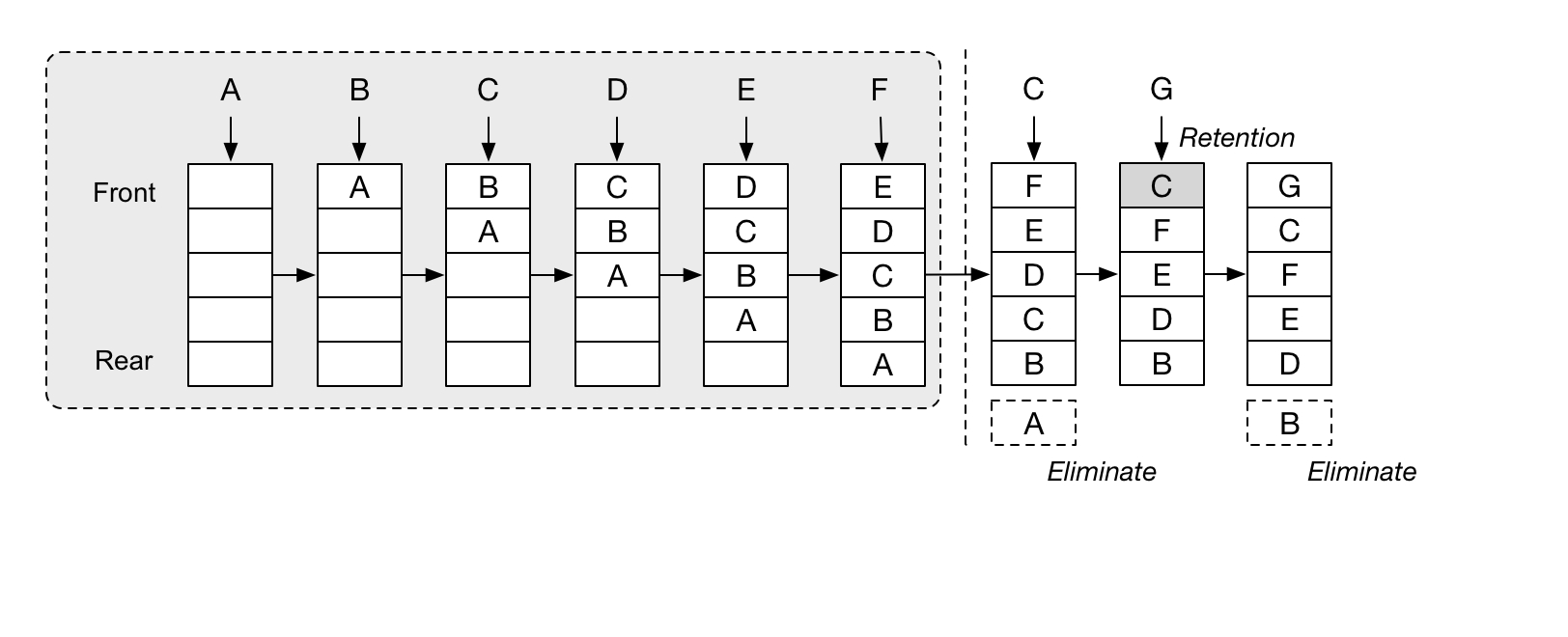
一个双向链表+HashMap 就可以让 LRU 算法只有 O(1) 的时间复杂度,非常简单粗暴,下面来看实现;
LruCache实现
由于Skiplist的实现依赖双向链表,而在Rust中实现双向链表并非一个简单的内容;
因此在阅读下面的实现前,强烈建议先阅读我的这篇文章:
Cache Trait定义
整体 Cache 的实现如下:
boost-rs/src/collection/cache/mod.rs
pub trait Cache<K: Eq, V> {
fn get(&mut self, key: &K) -> Option<&V>;
fn put(&mut self, key: K, value: V) -> Option<V>;
fn capacity(&self) -> usize;
}主要是三个方法:get、put、capacity,非常简单;
结构定义
数据条目LruEntry
存储的数据条目 LruEntry 结构定义:
struct LruEntry<K: Eq + Hash + Clone, V> {
key: K,
value: V,
}
impl<K: Eq + Hash + Clone, V> PartialEq<Self> for LruEntry<K, V> {
fn eq(&self, other: &Self) -> bool {
self.key.eq(&other.key)
}
}
impl<K: Eq + Hash + Clone, V> Eq for LruEntry<K, V> {}
impl<K: Eq + Hash + Clone, V> LruEntry<K, V> {
pub fn new(key: K, value: V) -> Self {
Self { key, value }
}
}缓存中的数据为 K、V 对,同时我们要求 K 实现了 Eq、Hash、Clone Trait:
- Eq:用于比较对应的 key 进行查找比较;
- Hash:用于将 key 生成对应的 hash;
- Clone:使用 clone 方法将 key 的值在 HashMap 中也存一份(当然,有更好的实现方法);
同时,我们重新为 LruEntry 定义了 Eq Trait,认为 K 相同就是相同的条目(这样我们存储的结构就满足了 Eq Trait、同时 V 不需要满足 Eq Trait);
缓存LruCache结构
LruCache 的定义如下:
const DEFAULT_CAPACITY: usize = 1024;
pub struct LruCache<K: Eq + Hash + Clone, V, S: BuildHasher = RandomState> {
map: HashMap<K, NonNull<Node<LruEntry<K, V>>>, S>,
cache: LinkedList<LruEntry<K, V>>,
cap: usize,
}包括了一个双向链表 LinkedList 和一个 Value 为指向链表 Node 节点指针的 HashMap;
Node 节点定义就是双向链表中的定义:
boost-rs/src/collection/linkedlist.rs
pub(crate) struct Node<T> {
val: T,
next: Option<NonNull<Node<T>>>,
prev: Option<NonNull<Node<T>>>,
}双向链表的对应实现见:
LruCache 初始化方法也是非常简单:
impl<K: Eq + Hash + Clone, V> LruCache<K, V, RandomState> {
pub fn with_capacity(cap: usize) -> Self {
LruCache {
map: HashMap::with_capacity(cap),
cache: LinkedList::new(),
cap,
}
}
}
impl<K: Eq + Hash + Clone, V, S: BuildHasher> LruCache<K, V, S> {
pub fn with_hasher(hasher: S) -> Self {
LruCache {
map: HashMap::with_capacity_and_hasher(DEFAULT_CAPACITY, hasher),
cache: Default::default(),
cap: DEFAULT_CAPACITY,
}
}
pub fn with_capacity_and_hasher(cap: usize, hasher: S) -> Self {
LruCache {
map: HashMap::with_capacity_and_hasher(cap, hasher),
cache: Default::default(),
cap,
}
}
}
impl<K: Eq + Hash + Clone, V> Default for LruCache<K, V, RandomState> {
fn default() -> Self {
LruCache {
map: HashMap::default(),
cache: LinkedList::default(),
cap: DEFAULT_CAPACITY,
}
}
}和标准库中的 HashMap 类似,也可以自定义 Hash 函数;
并且默认使用 HashMap 中的实现:RandomState;
Get方法
Get 方法实现:
fn get(&mut self, key: &K) -> Option<&V> {
let node = self.map.get(key)?;
let val = unsafe { &node.as_ref().val().value };
self.cache.move_raw_node_to_head(*node);
Some(val)
}逻辑如下:
首先,在 HashMap 中查找:
- 如果找到了 key 对应的 Node 说明缓存命中,取出对应节点;
- 否则,直接返回 None;
随后,取出对应节点的值,并将当前节点移到表头;
最后,返回数据引用;
链表的 move_raw_node_to_head 方法负责将当前节点移动到链表头,实现也非常简单:
/// Move the raw node pointer to the head of the list.
///
/// Warning: this will not check that the provided node belongs to the current list.
pub(crate) fn move_raw_node_to_head(&mut self, node: NonNull<Node<T>>) {
self.unlink_node(node);
self._push_front_raw(node);
}
/// Unlinks the specified node from the current list.
#[inline]
fn unlink_node(&mut self, mut node: NonNull<Node<T>>) {
let node = unsafe { node.as_mut() }; // this one is ours now, we can create an &mut.
// Not creating new mutable (unique!) references overlapping `element`.
match node.prev {
Some(prev) => unsafe { (*prev.as_ptr()).next = node.next },
// this node is the head node
None => self.head = node.next,
};
match node.next {
Some(next) => unsafe { (*next.as_ptr()).prev = node.prev },
// this node is the tail node
None => self.tail = node.prev,
};
self.length -= 1;
}move_raw_node_to_head 方法:
首先通过内部方法 unlink_node 将当前节点移出链表,然后通过 _push_front_raw 方法插回头部即可!
Put方法
Put 方法实现如下:
fn put(&mut self, key: K, value: V) -> Option<V> {
let new_key = key.clone();
let new_node = LruEntry::new(key, value);
let new_node = Box::new(Node::new(new_node));
let new_node = NonNull::new(Box::into_raw(new_node)).unwrap();
match self.map.get(&new_key) {
Some(val) => unsafe {
let removed = self.cache.remove_by_val(val.as_ref().val())?;
self.cache._push_front_raw(new_node);
self.map.insert(new_key, new_node);
Some(removed.value)
},
None => {
// Not found
let mut val = None;
if self.cache.length() >= self.cap {
// Cache is full, remove
if let Some(entry) = self.cache.pop_back() {
self.map.remove(&entry.key);
val = Some(entry.value);
}
}
self.cache._push_front_raw(new_node);
self.map.insert(new_key, new_node);
val
}
}
}在 put 方法中:
首先,使用传入的 k、v 创建 LruEntry 对象,并转为裸指针;
随后,通过在 HashMap 中寻找对应的缓存节点:
- 如果找到了已缓存的节点:将原节点移除,并向 HashMap 和链表中插入新的节点即可(因为此时只是替换节点,不涉及长度变化);
- 如果不存在已缓存的节点:此时如果长度超过了缓存的容量,则需要将链表尾节点、以及对应的 HashMap 中的数据都移除;随后和上面一样,插入数据即可!
- 最后,返回可能被移除的 val;
测试
对应的测试用例如下:
#[cfg(test)]
mod tests {
use std::collections::hash_map::RandomState;
use crate::collection::cache::{Cache, LruCache};
#[test]
fn test_new() {
let _l: LruCache<i32, String> = LruCache::default();
let _l: LruCache<i32, String> = LruCache::with_capacity(10);
let _l: LruCache<i32, String> = LruCache::with_hasher(RandomState::new());
let _l: LruCache<i32, String> = LruCache::with_capacity_and_hasher(10, RandomState::new());
}
#[test]
fn test_cache() {
let mut l = LruCache::with_capacity(4);
l.put("1".to_string(), 1);
l.put("2".to_string(), 2);
l.put("3".to_string(), 3);
l.put("4".to_string(), 4);
l.traverse();
assert_eq!(l.get(&"1".to_string()), Some(&1));
assert_eq!(l.get(&"2".to_string()), Some(&2));
assert_eq!(l.get(&"3".to_string()), Some(&3));
assert_eq!(l.get(&"4".to_string()), Some(&4));
assert_eq!(l.get(&"5".to_string()), None);
l.traverse();
l.put("5".to_string(), 5);
assert_eq!(l.get(&"5".to_string()), Some(&5));
assert_eq!(l.get(&"1".to_string()), None); // Cache cleaned
l.traverse();
}
#[test]
fn test_cache2() {
let mut l = LruCache::with_capacity(4);
l.put("1".to_string(), 1);
l.put("2".to_string(), 2);
l.put("3".to_string(), 3);
l.traverse();
l.put("4".to_string(), 4);
l.put("5".to_string(), 5);
l.traverse();
l.put("6".to_string(), 6);
l.put("7".to_string(), 7);
l.put("8".to_string(), 8);
l.traverse();
}
}
在 test_cache 测试中,我们首先初始化了一个容量为 4 的 LruCache,随后插入 1、2、3、4 四个数据;
随后,按顺序进行 get、此时最后一个访问的数据是 4,缓存中的数据为:4、3、2、1;
然后再插入数据 5,则会将 最不经常访问的数据 1 剔除掉!
附录
源代码:
- https://github.com/JasonkayZK/boost-rs/blob/main/boost-rs/src/collection/linkedlist.rs
- https://github.com/JasonkayZK/boost-rs/tree/main/boost-rs/src/collection/cache
参考文章:
- https://zhuanlan.zhihu.com/p/85846117
- https://github.com/jeromefroe/lru-rs/blob/master/src/lib.rs
- https://halfrost.com/lru_lfu_interview/
- https://ruby-china.org/topics/38516