
本文是Java面试总结中数据库的第一篇
一. 触发器与存储过程
存储过程
存储过程(Stored Procedure)是一组为了完成特定功能的SQL 语句集,经编译后存储在数据库。用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它相对于直接使用SQL 语句,在应用程序中直接调用存储过程有以下好处:数据库总结之一
- (1)减少网络通信量
- (2)执行速度更快
- (3)更强的适应性
- (4) 分布式工作
缺点:
- 扩展性差: 如果更改范围大到需要对输入存储过程的参数进行更改,或者要更改由其返回的数据,则需要更新程序集中的代码以添加参数、更新, 调用,等等
- 可移植性差: 由于存储过程将应用程序绑定到 MySQL,因此使用存储过程封装业务逻辑将限制应用程序的可移植性
例: 创建对表t_student的存储过程,实现查询指定id值的ccname功能
use mybatis;
delimiter $$
create procedure date_pre(in cid INT, out ccname char (20))
begin
select cnname from t_student where id = cid into ccname;
end$$
delimiter ;
call date_pre(1, @name1);
select @name1;
触发器
触发器是一种用来保障参照完整性的特殊的存储过程,它维护不同表中数据间关系的有关规则。当对指定的表进行某种特定操作(如:Insert,Delete或Update)时,触发器产生作用。触发器可以调用存储过程
触发器是一种特殊的存储过程
创建对表t_student的触发器,实现在表t_student中更新数据时,会自动将操作保存在日志表t_log中
use mybatis;
delimiter $$
create trigger trg_student_update after update on t_student for each row
begin
insert into t_log(log_time) values (NOW());
end$$
delimiter ;
-- drop trigger trg_student_update;
update t_student
set cnname = 'Mouse'
where id = 1;二. 数据库三范式是什么?
第一范式(1NF):字段具有原子性,不可再分。所有关系型数据库系统都满足第一范式
例如,姓名字段,其中的姓和名若作为一个整体,则无法区分哪部分是姓,哪部分是名
如果要区分出姓和名,必须设计成两个独立的字段
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)
第二范式: 要求数据库表中的每个实例或行必须可以被惟一地区分
通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主关键字或主键。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识
简而言之,第二范式就是非主属性非部分依赖于主关键字
满足第三范式(3NF)必须先满足第二范式(2NF)
第三范式(3NF)要求: 一个数据库表中不包含已在其它表中已包含的非主关键字信息
所以第三范式具有如下特征:
- 每一列只有一个值
- 每一行都能区分
- 每一个表都不包含其他表已经包含的非主关键字信息
例如,帖子表中只能出现发帖人的id,而不能出现发帖人的id,还同时出现发帖人姓名,否则,只要出现同一发帖人id的所有记录,它们中的姓名部分都必须严格保持一致,这就是数据冗余
三. 说出一些数据库优化方面的经验?
代码优化
- 程序优化,用PrepareedStatement进行增删改查
- 程序优化,尽量批量处理,避免逐条处理,减小IO数
查询优化
- 查询结果不要用*来查询所有字段,要明确指明结果字段
- 减少多表连接数,尽量少的表进行连接
SQL语句优化
- SQL的条件表达式,在Oracle中,是按倒序使用索引的
- 如果用DDL改动了数据库表字段,需要重建索引,不然索引失效
- SQL尽量不要有多余的空格和换行
索引优化
- 表连接时,尽量用主键进行连接或用唯一索引
- 表的查询多时,一定建立索引
- 根据查询条件,建立索引,如果查询条件不止一个时,使用组合索引
- 在查询条件表达式的左侧尽量不要使用函数,否则索引失效
- 如果不得不用函数,则建立函数索引
- 使用合适的索引,例如时间索引、哈希索引、聚簇索引
- 如果有like话,尽量避免%xxx%两侧都有%的条件,单侧%可以使用索引,多侧不可以
- 表结构改动时索引全部失效
- 条件中与null比较索引无效: 建立索引时字段不能有null值
其他优化
- 尽量不用数据库,使用缓存
- 可以考虑用nosql数据库提高效率
- 使用分布式数据库
- 合理创建表分区表空间
- 使用数据库连接池
四. union和union all有什么不同?
假设我们有一个表Student,包括以下字段与数据:
drop table student;
create table student (
id int primary key,
name varchar(50) not null,
score int(3) not null
);
insert into student values(1,'Aaron',78);
insert into student values(2,'Bill',76);
insert into student values(3,'Cindy',89);
insert into student values(4,'Damon',90);
insert into student values(5,'Ella',73);
insert into student values(6,'Frado',61);
insert into student values(7,'Gill',99);
insert into student values(8,'Hellen',56);
insert into student values(9,'Ivan',93);
insert into student values(10,'Jay',90);
commit;Union和Union All的区别:
select * from student
where id < 4
union
select * from student
where id > 2 and id < 6结果将是
1 Aaron 78
2 Bill 76
3 Cindy 89
4 Damon 90
5 Ella 73如果换成Union All连接两个结果集,则返回结果是:
1 Aaron 78
2 Bill 76
3 Cindy 89
3 Cindy 89 -- 重复
4 Damon 90
5 Ella 73可以看到,Union和Union All的区别之一在于对重复结果的处理
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果
实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。如:
select * from gc_dfys
union
select * from ls_jg_dfys这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序
而UNION ALL只是简单的将两个结果合并后就返回
这样,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了
从效率上说,UNION ALL要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就使用UNION ALL
五. 分页语句
① Oracle数据库分页
select * from
(select 表名 .*, rownum rc from 表名 where rownum <= endrow) a
where a.rc >= startrow;② MySQL数据库分页
Select * from 表名 limit startrow, pagesize; (Pagesize为每页显示的记录条数)③ 通用模式
select * from (
select * from student where sid not in (
select sid from student where rownum <= (currentPage-1)*pageSize
)
) where rownum <=pageSize;六. 注册Jdbc驱动程序的三种方式
Class.forName("com.mysql.jdbc.Driver"); // 常用, 不需要导包, 不依赖于特定的JDBC Driver库
DriverManager.registerDriver(new com.mysql.jdbc.Driver()) // 一定要有jdbc的驱动才可以通过编译
System.setProperty("jdbc.drivers","com.mysql.jdbc.Driver");
注释:
第一种方法是通过Class把类先装载到java的虚拟机中,并没有创建Driver类的实例:
第一种的好处在于能够在编译时不依赖于特定的JDBC Driver库,也就是减少了项目代码的依赖性,而且也很容易改造成从配置文件读取JDBC配置,从而可以在运行时动态更换数据库连接驱动
第三种与第一种方法可以脱离jdbc的驱动进行编译
第二种方法不可以的,它一定要有jdbc的驱动才可以通过编译,这样对我们的程序就有很多的不好之处,为程序换数据库会带来麻烦
七. 用JDBC如何调用存储过程
存储过程是指在数据库系统中,一组为了完成特定功能的SQL语句集,存储在数据库中,经过第一次编译后以后再调用任意次都不需要重新编译了: 说白了就是一堆SQL语句的合并,中间加了点逻辑控制,俗称为数据库中的函数。在一些金融等大型企业中,基本都是由内部人员编写好存储过程,然后由外部程序员调用存储过程,因为内部数据逻辑处理方式涉及商业机密等等
也就是说我们现在有两种方式来处理数据库中的数据:
- 一. 通过JDBC从数据库中取出数据然后通过业务层编写处理数据的逻辑代码;
- 二. 通过在数据库中定义数据的存储过程,在这个存储过程中完成对数据的逻辑操作,就好比数据库中的函数,而我们在Java程序中只要调用数据库中的这个存储过程即可
操作:
在MySQL数据库中确定要调用哪个存储过程,包括确定该存储过程的参数列表为哪些SQL类型:
JDBC中通过链接Connection对象,调用prepareCall(…)方法,在prepareCall方法中的参数为字符串,内容应该为{call 存储过程名(?(占位符,个数根据存储过程参数来定)...)},调用这个方法后返回CallableStatement对象
通过返回的CallableStatement对象对于传入类型的参数(IN),如PreparedStatement对象一样设置占位符的替代参数: 对于占位符对应的参数是输出类型(INOUT),调用CallableStatement对象的registerOutParameter(…)方法,该方法第一个参数指明替代第几个占位符,第二个参数指明该存储过程的输出参数在数据库中的SQL类型,在Java程序中可以使用Types类的字段指定
最后通过CallableStatement对象的execute()方法执行存储过程,即可通过getXXX方法获取prepareCall方法参数中占位符类型为输出的参数值
下面通过一个例子来说明:
我们现在数据库中自定义一个存储过程,这个存储过程的功能是在我们传入的每一个字符串参数面前加上一段字符串,即将两端字符串连接,最后返回:
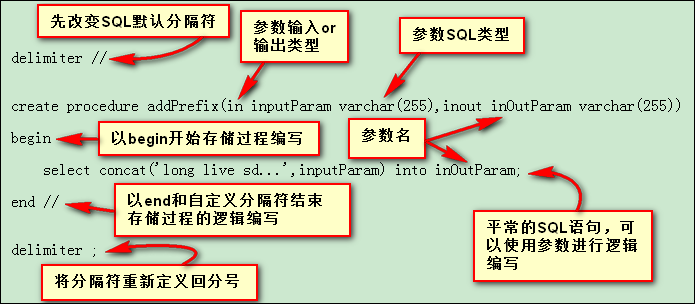
delimiter //
create procedure addPrefix(in inputParam varchar(255), inout inOutParam varchar(255))
begin
select concat('long live sd...', inputParam) into inOutParam;
end //
delimiter ;
分析:
第一行我们将MySQL中的分隔符先定义为
//,因为等会在存储过程的逻辑代码中会使用到;,不先定义别的分隔符的话逻辑代码还没写完数据库就执行了第二行定义存储过程的名称,同时在参数列表中定义参数输入输出类型(IN,OUT,INOUT),参数名称,参数类型(SQL数据类型)
第三行开始以关键字“BEGIN”开始,以“END”和刚才定义的分隔符结束,在这两个中间就是平常的SQL语句了,也就是在这个部分编写我们处理参数的逻辑
最后,我们将MySQL数据库的分隔符重新定义回分号
;
注:在数据库中定义存储过程时,应先选择使用的库,这里我使用exam库
这里顺便一说在MySQL中如何使用SQL命令来调用存储过程,对于我们上面刚刚创建的存储过程,可以使用如下SQL命令语句来调用和查看结果:
set @inputParam = 'LRR';
call addPrefix(@inputParam, @result);
select @result;因为我们使用到了输入参数,因此在调用存储过程之前需要先设置好输入类型In的参数,在MySQL中,使用“@”代表该参数是一个用户变量,而对于输出类型out或inout也需要一个自定义用户变量,最后由select将结果显示
注:用户变量在退出MySQL命令行窗口后会自动释放资源
下面开始介绍在Java中如何调用数据库中的存储过程
创建Java工程,在工程中导入数据库连接驱动的jar包
在【src】目录下新建一个database.properties文件,内容如下:
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/exam
username=root
password=root构建JDBC的工具类,包括注册驱动,获取连接,释放资源和连接等
接着,我们将使用JDBC来调用上面刚刚定义的存储过程:
import java.io.IOException;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
public class JdbcTest {
private static Properties config = new Properties();
static {
InputStream in = null;
try {
in = JdbcTest.class.getClassLoader().getResourceAsStream("jdbc.properties");
if (in != null) {
config.load(in);
}
Class.forName(config.getProperty("driver"));
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public static Connection getConnection() throws SQLException {
String url = config.getProperty("url");
String username = config.getProperty("username");
String password = config.getProperty("password");
Connection conn = DriverManager.getConnection(url, username, password);
return conn;
}
public static void release(Connection conn, Statement st, ResultSet rs) {
if (rs != null) {
try {
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
if (st != null) {
try {
st.close();
} catch (Exception e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws SQLException {
Connection conn = null;
CallableStatement st = null;
ResultSet rs = null;
try {
conn = getConnection();
st = conn.prepareCall("{call addPrefix(?, ?)}");
st.setString(1, "love LRR");
st.registerOutParameter(2, Types.VARCHAR);
st.execute();
String contactPrefix = st.getString(2);
System.out.println(contactPrefix); // long live sd...love LRR
} finally {
release(conn, st, rs);
}
}
}
CallableStatement对象是Statement对象的子类,因此在调用JdbcUtils.release方法时使用了多态
在prepareCall方法中的参数是指定调用哪个存储过程的字符串,同时使用到了占位符,那么通过CallableStatement对象对传入类型的参数设置要替代占位符的数据
对于输出类型的参数则调用registerOutParameter方法替代占位符并指定SQL类型
在Java中Types类封装了各种SQL类型的字段
八. JDBC中的PreparedStatement相比Statement的好处
Statement对象:用于执行不带参数的简单SQL语句
特点:
- a. 只执行单条的sql语句;
- b. 只能执行不带参数的sql语句;
- c.运行原理的角度,数据库接收到sql语句后需要对该条sql语句进行编译后才执行;
- d.与其它接口对比,适合执行单条且不带参数的sql语句,这种情况执行效率相对较高
PreparedStatement对象: 执行带或不带 IN 参数的预编译 SQL 语句
特点:
- a. 继承自Statement接口(意味着功能相对更加全面);
- b. 带有预编译的特性;
- c. 批量处理sql语句;
- d. 处理带未知参数的sql语句;
- e. 具有安全性,即可以防止恶意的sql语句注入攻击;
- f. 在处理单条语句上,执行效率没有Statement快;
- g. 提高程序的可读性和可维护性
九. 说出数据连接池的工作机制是什么?
J2EE服务器启动时会建立一定数量的池连接,并一直维持不少于此数目的池连接
客户端程序需要连接时,池驱动程序会返回一个未使用的池连接并将其标记为忙, 如果当前没有空闲连接,池驱动程序就新建一定数量的连接,新建连接的数量有配置参数决定
当使用的池连接调用完成后,池驱动程序将此连接表记为空闲,其他调用就可以使用这个连接
实现方式: 返回的Connection是原始Connection的代理,代理Connection的close方法不是真正关连接,而是把它代理的Connection对象还回到连接池中
十. 为什么要用 ORM? 和 JDBC有何不一样?
1、繁琐的代码问题
用JDBC的API编程访问数据库,代码量较大,特别是访问字段较多的表的时候,代码显得繁琐、累赘,容易出错,例如:
public void addAccount(final Account account) throws DAOException {
final Connection conn=getConnection();
PreparedStatement pstmt=con.prepareStatment("insert into account value(?,?,?,?,?,?,?,?,?)");
pstmt.setString(1,account.getUserName());
pstmt.setInt(2,account.getPassWord());
pstmt.setString(3,account.getSex());
pstmt.setString(4,account.getQq());
......
pstmt.execute();
conn.Close();
}可见,程序员需要耗费大量的时间、精力去编写具体的数据库访问的SQL语句,还要十分小心其中大量重复的源代码是否有疏漏,并不能集中精力于业务逻辑开发上面
ORM则建立了Java对象与数据库对象之间的映射关系,程序员不需要编写复杂的SQL语句,直接操作Java对象即可,从而大大降低了代码量,也使程序员更加专注于业务逻辑的实现
2、数据库对象连接问题
关系数据对象之间,存在各种关系,包括1对1、1对多、多对1、多对多、级联等
在数据库对象更新的时候,如果采用JDBC编程,程序员必须十分小心处理这些关系,以保证维持这些关系不会出现错误,而这个过程是一个很痛苦的过程
ORM建立Java对象与数据库对象关系影射的同时,也自动根据数据库对象之间的关系创建Java对象的关系,并且提供了维持这些关系完整、有效的机制
3、系统架构问题
现在的应用系统,一般由展示层、业务逻辑层、数据访问层、数据库层等组成,各层次功能划分非常清晰
JDBC属于数据访问层,但是使用JDBC编程时,程序员必须知道后台是用什么数据库、有哪些表、各个表有有哪些字段、各个字段的类型是什么、表与表之间什么关系、创建了什么索引等等与后台数据库相关的详细信息, 相当于软件程序员兼职数据库DBA
使用ORM技术,可以将数据库层完全隐蔽,呈献给程序员的只有Java的对象,程序员只需要根据业务逻辑的需要调用Java对象的Getter和 Setter方法,即可实现对后台数据库的操作,程序员不必知道后台采用什么数据库、有哪些表、有什么字段、表与表之间有什么关系
于是,系统设计人员把ORM搭建好后,把Java对象交给程序员去实现业务逻辑,使数据访问层与数据库层清晰分界
4、性能问题
采用JDBC编程,在很多时候存在效率低下的问题,如:
pstmt =conn.prepareStatement("insert into user_info values(?,?)");
for (int i=0; i<1000; i++) {
pstmt.setInt(1,i);
pstmt.setString(2,"User"+i.toString());
pstmt.executeUpdate();
}
}以上程序将向后台数据库发送1000次SQL语句执行请求,运行效率较低
如果采用ORM技术,ORM框架将根据具体数据库操作需要,会自动延迟向后台数据库发送SQL请求,如上面的程序,只会在循环完成后,一次向数据库发送操作请求,从而大大降低通讯量,提高运行效率;ORM也可以根据实际情况,将数据库访问操作合成,尽量减少不必要的数据库操作请求