
一直想要有那种开箱即用的大数据Docker镜像,但是找了很久感觉使用体验都不好;
最近又搞起了大数据,感觉还是自己搞一个大数据的镜像组集群比较好;
软件来源:
Github地址:
DockerHub镜像:
- https://hub.docker.com/u/jasonkay
- https://hub.docker.com/r/jasonkay/big-data-1
- https://hub.docker.com/r/jasonkay/big-data-2
- https://hub.docker.com/r/jasonkay/big-data-3
系列文章:
前言
本系列会从最开始构建Hadoop开始,逐步添加大数据组件,来构建一个大数据集群;
整个集群共分为三个节点(后面可能会根据情况增加);
本篇作为最开始,先来构建了三节点的Hadoop集群;
最基础的镜像使用的是:
- centos:centos7.9.2009
软件压缩包存放在:
- /opt/software
软件放在:
- /opt/module
工具放在:
- /root/bin
废话不多说,直接开始吧!
网络规划
保证大数据中各个节点的网络互通是非常重要的!
因此我们首先来创建一个专属于这个大数据集群的子网:
# 大数据子网
docker network create --subnet 172.30.0.0/24 --gateway 172.30.0.1 big-data我们选择了172.30.0.0/24作为子网,172.30.0.1为对应网关;
对于不同节点规划如下:
| 节点 | IP | 说明 |
|---|---|---|
| big-data-model | 172.30.0.10 | 大数据基础镜像 |
| big-data-1 | 172.30.0.11 | 节点1 |
| big-data-2 | 172.30.0.12 | 节点2 |
| big-data-3 | 172.30.0.13 | 节点3 |
下面构建基础镜像;
构建基础镜像
使用下面的命令创建基础镜像容器:
# 最基础镜像
docker run -itd --name big-data-model --net big-data --ip 172.30.0.10 --hostname big-data-model --privileged centos:centos7.9.2009 /usr/sbin/init
docker exec -it big-data-model /bin/bash注:
--privileged和/usr/sbin/init是必须的,否则会存在容器权限不足的问题!
进入镜像后执行:
# 更新软件源
yum install -y epel-release
yum update -y
# 安装和配置SSH
yum install -y openssh-server
systemctl start sshd
systemctl enable sshd
## 增加配置内容
vi /etc/ssh/sshd_config
UseDNS no
PermitRootLogin yes #允许root登录
PermitEmptyPasswords no #不允许空密码登录
PasswordAuthentication yes # 设置是否使用口令验证
systemctl restart sshd
# 安装SSH客户端
yum -y install openssh-clients
# 安装Vim
yum install -y vim
# 安装网络工具
yum install -y net-tools
# 修改hosts,增加节点内容
vi /etc/hosts
172.30.0.11 big-data-1
172.30.0.12 big-data-2
172.30.0.13 big-data-3上面的内容执行完后,执行docker commit将容器保存为镜像:
docker commit --message "基本镜像:添加ssh、net-tools等工具" big-data-model jasonkay/big-data-model:v0.1
# 向DockerHub推送镜像(可选)
docker push jasonkay/big-data-model:v0.1下面测试基础镜像:
# 基础镜像测试
docker run -itd --name big-data-1 --net big-data --ip 172.30.0.11 --hostname big-data-1 --privileged jasonkay/big-data-model:v0.1 /usr/sbin/init
docker run -itd --name big-data-2 --net big-data --ip 172.30.0.12 --hostname big-data-2 --privileged jasonkay/big-data-model:v0.1 /usr/sbin/init
docker run -itd --name big-data-3 --net big-data --ip 172.30.0.13 --hostname big-data-3 --privileged jasonkay/big-data-model:v0.1 /usr/sbin/init使用基础镜像创建三个大数据容器:
- big-data-1
- big-data-2
- big-data-3
进入容器1:
docker exec -it big-data-1 /bin/bashPing其他容器:
[root@big-data-1 software]# ping big-data-2
PING big-data-2 (172.30.0.12) 56(84) bytes of data.
64 bytes from big-data-2.big-data (172.30.0.12): icmp_seq=1 ttl=64 time=0.054 ms
64 bytes from big-data-2.big-data (172.30.0.12): icmp_seq=2 ttl=64 time=0.056 ms
64 bytes from big-data-2.big-data (172.30.0.12): icmp_seq=3 ttl=64 time=0.063 ms
^C
--- big-data-2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 0.054/0.057/0.063/0.009 ms
[root@big-data-1 software]# ping big-data-3
PING big-data-3 (172.30.0.13) 56(84) bytes of data.
64 bytes from big-data-3.big-data (172.30.0.13): icmp_seq=1 ttl=64 time=0.067 ms
64 bytes from big-data-3.big-data (172.30.0.13): icmp_seq=2 ttl=64 time=0.091 ms
64 bytes from big-data-3.big-data (172.30.0.13): icmp_seq=3 ttl=64 time=0.063 ms
^C
--- big-data-3 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.063/0.073/0.091/0.015 ms网络畅通!
安装和配置软件及脚本
配置SSH
每个容器执行,生成SSH Key:
ssh-keygen -t rsa将各个容器SSH公钥放在其他容器中:
cat ~/.ssh/id_rsa.pub >> authorized_keys测试:
[root@big-data-1 software]# ssh big-data-2
Last login: Wed Aug 18 06:48:24 2021
[root@big-data-2 ~]# exit
logout
Connection to big-data-2 closed.
[root@big-data-1 software]# ssh big-data-3
Last login: Wed Aug 18 01:41:21 2021 from 172.30.0.10
[root@big-data-3 ~]# exit
logout
Connection to big-data-3 closed.容器集群内同步文件脚本xsync
首先安装rsync:
yum install -y rsync编辑创建xsync文件:
cd ~
mkdir bin
cd ~/bin
vim xsync
#!/bin/bash
# 1. check param num
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
# 2.traverse all mechine
for host in "big-data-1" "big-data-2" "big-data-3"
do
echo ==================== $host ====================
# 3.traverse dir for each file
for file in $@
do
# 4.check file exist
if [ -e $file ]
then
# 5.get parent dor
pdir=$(cd -P $(dirname $file); pwd)
# 6.get file name
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
# 增加执行权限
chmod +x xsync测试:
[root@big-data-1 bin]# xsync xsync
==================== big-data-1 ====================
sending incremental file list
sent 38 bytes received 12 bytes 100.00 bytes/sec
total size is 596 speedup is 11.92
==================== big-data-2 ====================
sending incremental file list
sent 38 bytes received 12 bytes 100.00 bytes/sec
total size is 596 speedup is 11.92
==================== big-data-3 ====================
sending incremental file list
sent 38 bytes received 12 bytes 100.00 bytes/sec
total size is 596 speedup is 11.92成功!
JDK安装
各个容器内执行:
mkdir -p /opt/software
mkdir -p /opt/module创建目录;
将宿主机中的JDK发送到容器中:
docker cp jdk-8u212-linux-x64.tar.gz big-data-1:/opt/software
docker cp jdk-8u212-linux-x64.tar.gz big-data-2:/opt/software
docker cp jdk-8u212-linux-x64.tar.gz big-data-3:/opt/software各个容器内解压缩:
cd /opt/software
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
# 配置环境变量
vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
# 立即生效
source /etc/profile.d/my_env.sh
# 校验
java -version创建模拟数据
各个容器内执行:
mkdir /opt/module/applog宿主机将文件copy进容器中:
docker cp 日志.zip big-data-1:/opt/module/applog
docker cp 日志.zip big-data-2:/opt/module/applog
docker cp 日志.zip big-data-3:/opt/module/applog各个容器内解压缩:
yum install -y unzip
cd /opt/module/applog
unzip 日志.zip
rm -rf *.zip各个容器内生成日志:
java -jar gmall2020-mock-log-2021-01-22.jar① 配置集群日志生成脚本
配置环境变量:
vim /etc/profile.d/my_env.sh export PATH=$PATH:$JAVA_HOME/bin:.:~/bin source /etc/profile.d/my_env.sh创建生成脚本:
vim ~/bin/lg.sh # 脚本内容 #!/bin/bash for i in "big-data-1" "big-data-2" "big-data-3"; do echo "========== $i ==========" ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-01-22.jar >/dev/null 2>&1 &" done chmod u+x ~/bin/lg.sh
② 集群所有进程查看脚本
各个容器中:
vim ~/bin/xcall.sh #! /bin/bash for i in "big-data-1" "big-data-2" "big-data-3" do echo --------- $i ---------- ssh $i "$*" done chmod 777 ~/bin/xcall.sh测试:
[root@big-data-1 /]# ~/bin/xcall.sh jps --------- big-data-1 ---------- 204 Jps --------- big-data-2 ---------- 152 Jps --------- big-data-3 ---------- 155 Jps
Hadoop安装和配置
软件安装
宿主机传输文件到容器:
docker cp hadoop-3.1.3.tar.gz big-data-1:/opt/software
docker cp hadoop-3.1.3.tar.gz big-data-2:/opt/software
docker cp hadoop-3.1.3.tar.gz big-data-3:/opt/software各容器解压缩并配置:
cd /opt/software
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
# 配置环境变量
vim /etc/profile.d/my_env.sh
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
# 立即生效
source /etc/profile.d/my_env.shHadoop配置
进入Hadoop目录:
# big-data-1节点
cd $HADOOP_HOME/etc/hadoop修改核心配置文件:
vim core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://big-data-1:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 配置该root(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
</configuration>HDFS配置文件:
vim hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>big-data-1:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>big-data-3:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>YARN配置文件:
vim yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>big-data-2</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>MapReduce配置文件:
vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>配置workers:
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
big-data-1
big-data-2
big-data-3配置历史服务器:
vim mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>big-data-1:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>big-data-1:19888</value>
</property>配置日志的聚集:
vim yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://big-data-1:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>分发Hadoop:
# 在big-data-1执行
xsync /opt/module/hadoop-3.1.3/启动Hadoop集群
如果集群是第一次启动,需要在big-data-1节点格式化NameNode(注意格式化之前,一定要先停止上次启动所有namenode和datanode进程,然后再删除data和log数据)!
格式化节点:
# 在big-data-1执行
cd $HADOOP_HOME
./bin/hdfs namenode -format启动HDFS:
sbin/start-dfs.sh在配置了ResourceManager的节点(big-data-2)启动YARN:
# 在big-data-2执行
sbin/start-yarn.sh查看结果:
curl big-data-1:9870
# 返回类似于:<title>Hadoop Administration</title> 则成功;或者:宿主机访问
172.30.0.11:9870;注:如果你的宿主机是虚拟机或者其他服务器,可以在宿主机配置Nginx反向代理,进而在本机直接访问宿主机即可!
具体方法:
# 宿主机编辑Nginx配置 vi /etc/nginx/conf.d/hadoop_admin.conf server { listen 9870; server_name localhost; location / { proxy_pass http://172.30.0.11:9870; } }添加映射即可;
然后本机访问:
<宿主机IP>:9870;效果如下:
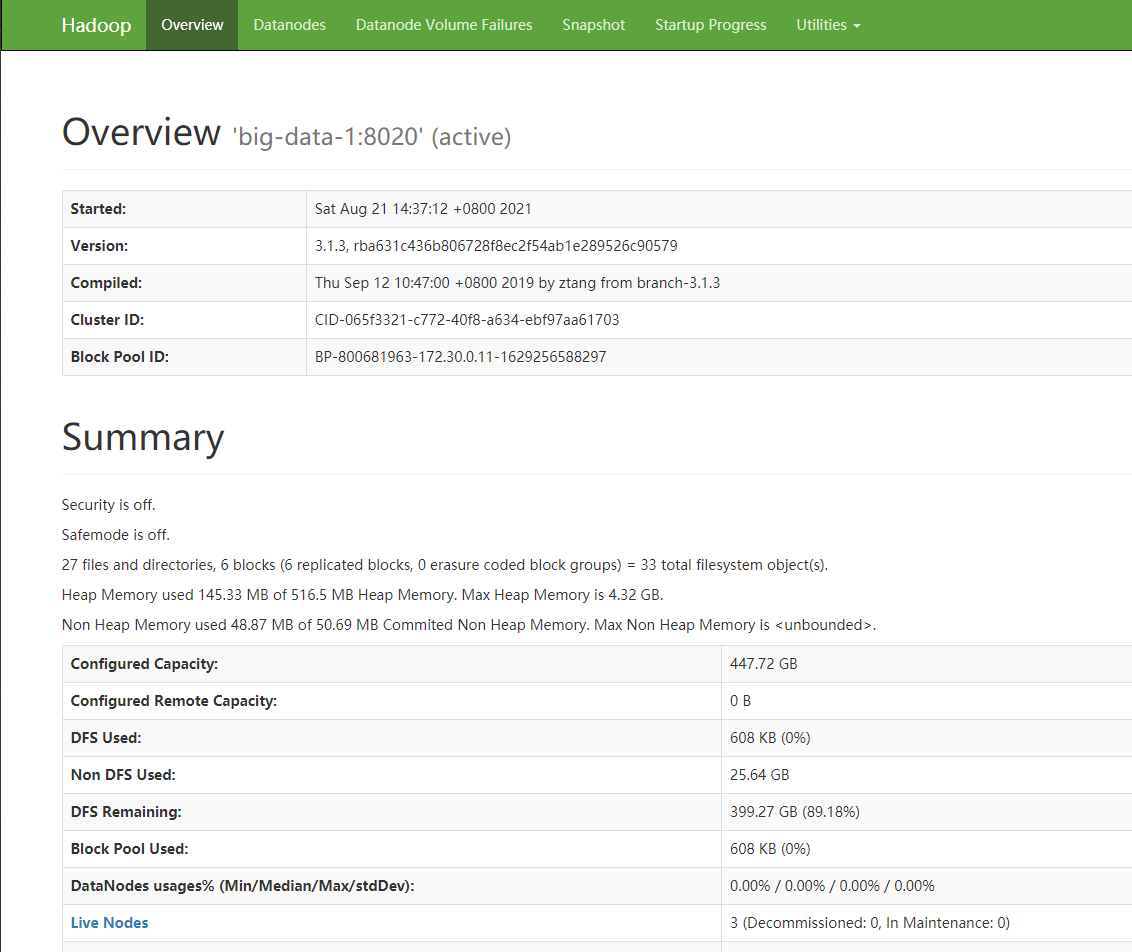
接下来我们配置Hadoop集群启动脚本;
配置Hadoop集群启动脚本
vim ~/bin/hdp.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== Start Hadoop Cluster ==================="
echo " --------------- Start hdfs ---------------"
ssh big-data-1 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- Start yarn ---------------"
ssh big-data-2 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- Start historyserver ---------------"
ssh big-data-1 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== Close Hadoop Cluster ==================="
echo " --------------- Close historyserver ---------------"
ssh big-data-1 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- Close yarn ---------------"
ssh big-data-2 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- Close hdfs ---------------"
ssh big-data-1 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
# 修改权限
chmod 777 hdp.sh脚本测试:
启动:
[root@big-data-1 bin]# ./hdp.sh start
=================== Start Hadoop Cluster ===================
--------------- Start hdfs ---------------
Starting namenodes on [big-data-1]
Last login: Sat Aug 21 05:17:52 UTC 2021 from 172.30.0.11 on pts/2
Starting datanodes
localhost: datanode is running as process 530. Stop it first.
Last login: Sat Aug 21 06:37:11 UTC 2021
Starting secondary namenodes [big-data-3]
Last login: Sat Aug 21 06:37:13 UTC 2021
--------------- Start yarn ---------------
Starting resourcemanager
Last login: Sat Aug 21 05:17:56 UTC 2021 from 172.30.0.11 on pts/1
Starting nodemanagers
Last login: Sat Aug 21 06:37:20 UTC 2021
--------------- Start historyserver ---------------关闭:
[root@big-data-1 /]# ~/bin/hdp.sh stop
=================== Close Hadoop Cluster ===================
--------------- Close historyserver ---------------
--------------- Close yarn ---------------
Stopping nodemanagers
Last login: Sat Aug 21 06:37:22 UTC 2021
Stopping resourcemanager
Last login: Sat Aug 21 06:47:52 UTC 2021
--------------- Close hdfs ---------------
Stopping namenodes on [big-data-1]
Last login: Sat Aug 21 06:37:16 UTC 2021
Stopping datanodes
Last login: Sat Aug 21 06:47:56 UTC 2021
Stopping secondary namenodes [big-data-3]
Last login: Sat Aug 21 06:47:57 UTC 2021创建Big-Data镜像
经过上面的安装和配置,我们已经创建了一个三节点的Hadoop集群;
接下来我们将这几个容器提交为镜像:
docker commit --message "大数据集群基本镜像:完成Hadoop和Yarn部分" big-data-1 jasonkay/big-data-1:v1.0
docker commit --message "大数据集群基本镜像:完成Hadoop和Yarn部分" big-data-2 jasonkay/big-data-2:v1.0
docker commit --message "大数据集群基本镜像:完成Hadoop和Yarn部分" big-data-3 jasonkay/big-data-3:v1.0Hadoop测试
测试之前请确保已经停止并清除了所有正在Run的容器!
通过命令行启动多个容器
启动测试
直接通过命令行启动容器:
docker run -itd --name big-data-1 --net big-data --ip 172.30.0.11 --hostname big-data-1 --privileged jasonkay/big-data-1:v1.0 /usr/sbin/init
docker run -itd --name big-data-2 --net big-data --ip 172.30.0.12 --hostname big-data-2 --privileged jasonkay/big-data-2:v1.0 /usr/sbin/init
docker run -itd --name big-data-3 --net big-data --ip 172.30.0.13 --hostname big-data-3 --privileged jasonkay/big-data-3:v1.0 /usr/sbin/init进入容器big-data-1:
docker exec -it big-data-1 /bin/bash容器中启动Hadoop:
[root@big-data-1 /]# ~/bin/hdp.sh start查看结果:
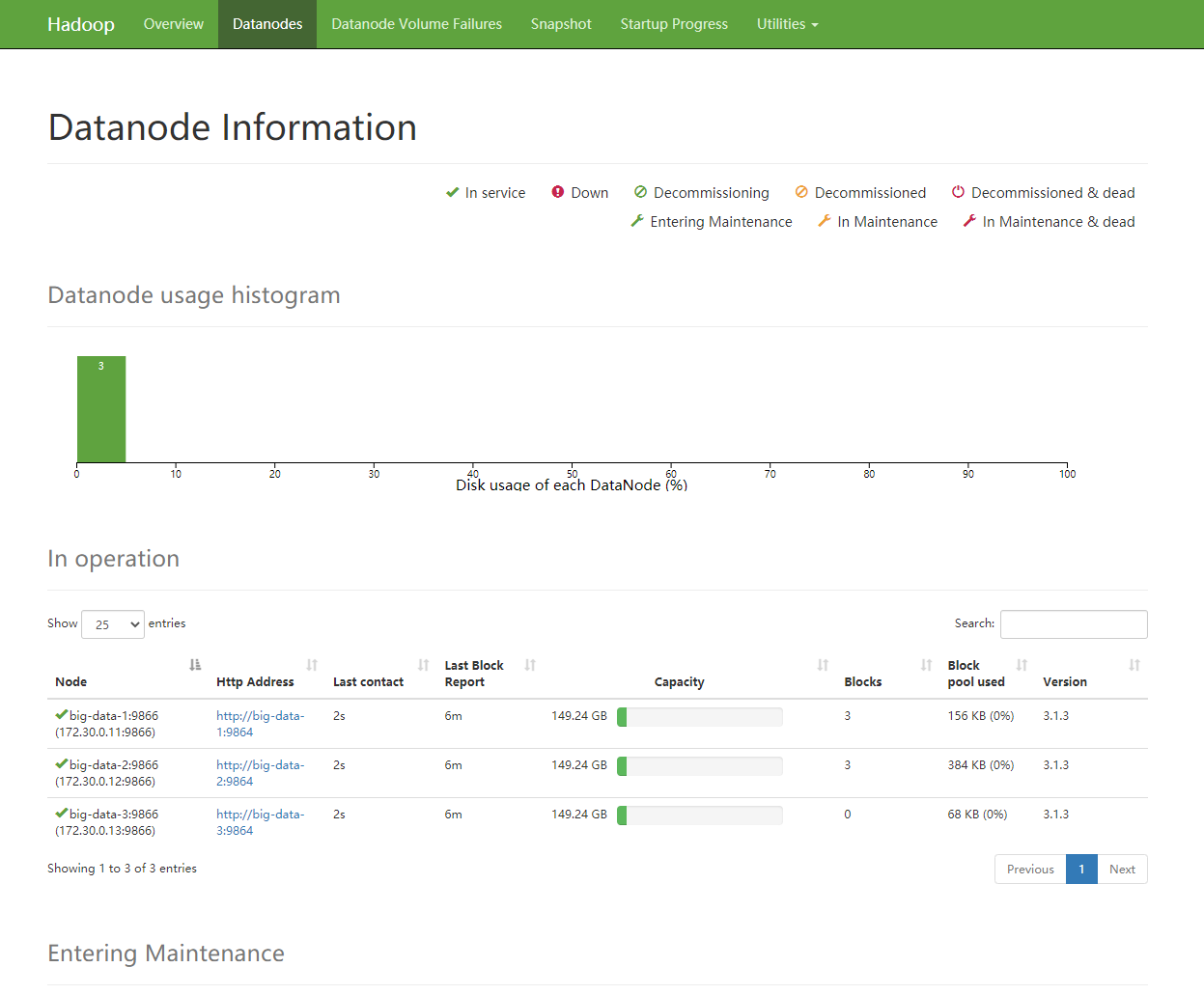
功能测试
数据准备:
cd ~/
vi data.txt
# 写入内容
hello hadoop
hello World
Hello Java
Hey man
i am a programmer写入HDFS:
# 创建/input目录
hdfs dfs -mkdir /input
# 写入hdfs
hdfs dfs -put data.txt /input
# 查看HDFS
hdfs dfs -ls /input
Found 1 items
-rw-r--r-- 1 root supergroup 62 2021-08-18 06:42 /input/data.txtWord Count测试:
cd /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /input/data.txt /output查看结果:
hdfs dfs -cat /output/part-r-00000
2021-08-21 07:00:46,337 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Hello 1
Hey 1
Java 1
World 1
a 1
am 1
hadoop 1
hello 2
i 1
man 1
programmer 1成功!
通过Docker-Compose启动多个容器
编辑docker-compose.yml
docker-compose.yml
version: '3.4'
services:
big-data-1:
image: jasonkay/big-data-1:v1.0
hostname: big-data-1
container_name: big-data-1
privileged: true
links:
- big-data-2
- big-data-3
depends_on:
- big-data-2
- big-data-3
ports:
- 9870:9870
- 22
entrypoint: ["/usr/sbin/init"]
networks:
big-data:
ipv4_address: 172.30.0.11
big-data-2:
image: jasonkay/big-data-2:v1.0
hostname: big-data-2
container_name: big-data-2
privileged: true
entrypoint: ["/usr/sbin/init"]
ports:
- 22
networks:
big-data:
ipv4_address: 172.30.0.12
big-data-3:
image: jasonkay/big-data-3:v1.0
hostname: big-data-3
container_name: big-data-3
privileged: true
entrypoint: ["/usr/sbin/init"]
ports:
- 22
networks:
big-data:
ipv4_address: 172.30.0.13
networks:
big-data:
external:
name: big-data启动三个节点:
[root@localhost docker-repo]# docker-compose up -d
Creating big-data-3 ... done
Creating big-data-2 ... done
Creating big-data-1 ... done进入big-data-1启动集群:
[root@big-data-1 bin]# ./hdp.sh start
=================== Start Hadoop Cluster ===================
--------------- Start hdfs ---------------
Starting namenodes on [big-data-1]
Last login: Wed Aug 18 04:48:01 UTC 2021
Starting datanodes
Last login: Sun Aug 22 08:13:26 UTC 2021
Starting secondary namenodes [big-data-3]
Last login: Sun Aug 22 08:13:28 UTC 2021
--------------- Start yarn ---------------
Starting resourcemanager
Last login: Wed Aug 18 04:47:56 UTC 2021
Starting nodemanagers
Last login: Sun Aug 22 08:13:35 UTC 2021
--------------- Start historyserver ---------------查看状态:
[root@big-data-1 ~]# ./xcall.sh jps
--------- big-data-1 ----------
1137 Jps
811 NodeManager
940 JobHistoryServer
492 DataNode
271 NameNode
--------- big-data-2 ----------
694 NodeManager
317 ResourceManager
142 DataNode
1054 Jps
--------- big-data-3 ----------
145 DataNode
229 SecondaryNameNode
518 Jps
316 NodeManager启动成功!
附录
软件来源:
Github地址:
DockerHub镜像:
- https://hub.docker.com/u/jasonkay
- https://hub.docker.com/r/jasonkay/big-data-1
- https://hub.docker.com/r/jasonkay/big-data-2
- https://hub.docker.com/r/jasonkay/big-data-3
系列文章: