
内存管理是操作系统中一个关键的组成部分,本文通过C++实例,简述了操作系统中的内存管理;
视频参考:
操作系统内存管理简述
为什么要有逻辑地址
由于程序无法知道实际可用的物理地址,所以必须对实际的内存地址做出映射!
如果有过单片机开发经验的同学应该知道,在进行嵌入式编程的时候,通常我们可以直接操作实际内存的物理地址,但是在操作系统中,都是使用逻辑地址的;
使用逻辑地址,可以简化程序的开发,让所有的程序都以为他们拥有了操作系统的全部内存空间;
并且可以避免恶意程序可以跨代码段对其他程序进行恶意修改;(但是,恶意程序其实还是可以通过共享库的方式恶意入侵其他程序)
如:C++中如果跨内存进行访问就会抛出Segment Fault的经典错误;
逻辑地址和物理地址映射方法
① 固定偏移量
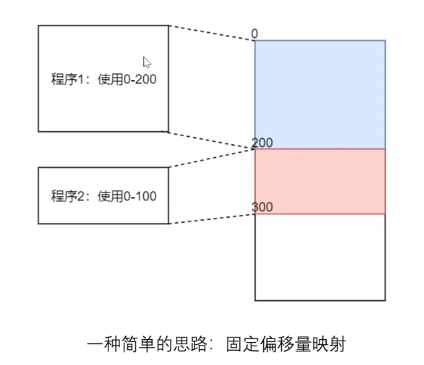
即每个程序都使用一段连续的内存空间进行映射;
优点是实现起来简单,但是缺点很明显:
首先,每个程序使用的内存大小是不确定的;
如果我们预估程序1使用的最大内存为200,则程序1在整个执行过程中的内存占用率都会小于200,此时称内存中产生了内碎片;
其次,当程序1结束使用,而程序3占用空间为201时,原来连续的200个空间,其实是无法被使用的,如下图:
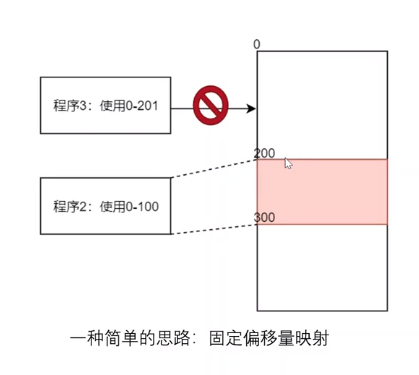
此时0-200的区域被称为内存的外碎片;
为了减少这些内存碎片,使用分页的思想进行处理;
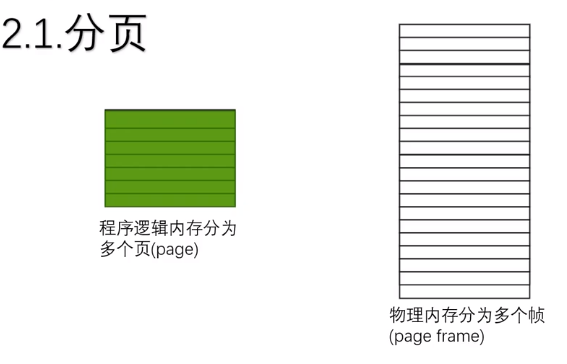
② 内存分页
内存分页是指将内存按照固定的大小进行拆分,拆分后的物理内存被分为了多个帧(page frame),程序的逻辑内存在加载时也被拆分为了多个页(page),如下图:
逻辑内存和物理内存直接的映射通过页表(Page Table)来维护,如下图:
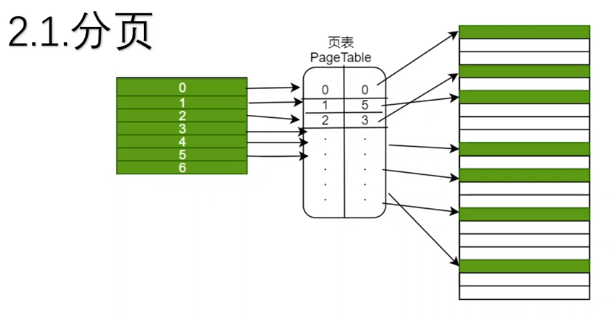
除了映射之外,页表存储了大量的信息:
- 当前条目是否可用;
- 当前页的读写权限;
- 是否是脏读帧;
- ……
因为每个进程之间的存储空间都是相互独立的(共享库等其他特殊数据除外),所以页表是每个进程都需要维护的,如下:
补充内容:
- 内存的一个地址里面”住”的是一个字节(Byte)的数据;
- 2^32 位的操作系统的物理地址有 2^32 个,因而只能使用4GB的内存;
- 任何一个32位的程序可操作的逻辑地址都是2^32个即4GB;(每个32位的程序都天真的以为自己拥有4GB内存)
- 上面势必造成多个程序使用内存总和很有可能大于物理内存,此时会借助磁盘,将并不着急使用的内存先放到磁盘,此时PageTable对应的帧号只显示是磁盘;
记一次内存映射的过程
假设我们使用的机器为32为操作系统,我们一共具有256MB内存,每一页的大小为4KB;
而由于4K的数据可以使用12bit来寻址(4K = 4 X 1024Byte = 4 x 2^12 = 2 ^14)则有:
- 逻辑地址(所有程序都认为自己是4GB):32bit = 20bit页号 + 12bit偏移;
- 物理地址(实际只有256MB内存):28bit = 16bit帧号 + 12bit偏移;
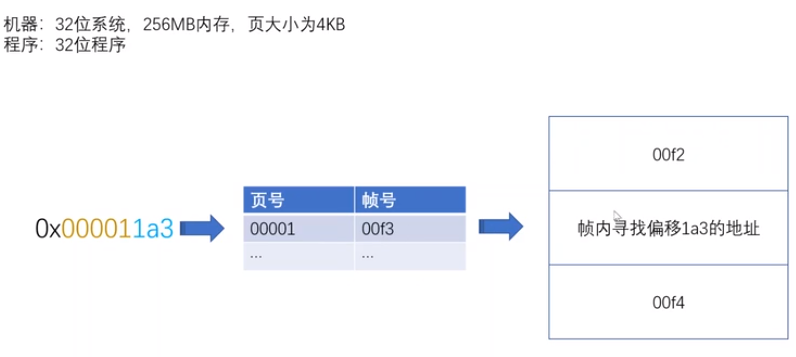
以地址0X000011A3为例,其逻辑地址为:页号:00001,偏移:1A3;
接下来去看其在物理地址的映射;
假设该页号在Page Table中对应的真正物理内存的帧号为00F3(16bit),则会在物理内存帧号为00F3,偏移为1A3的区域寻找真正的数据,如下图:
但是,如果寻址之后,发现在物理内存中对应的帧号是磁盘会发生什么呢?
当映射的帧号是disk时,即映射到了磁盘上;此时会触发缺页异常,进入内核态,内核从磁盘中读取缺的这页内容,将其加载到物理内存中;
但是物理内存的帧有可能所有帧都满了,此时就需要逐出不太”重要”的帧(例如,使用LRU算法);
逐出的过程需要判断当前物理页(帧)是否是脏的(脏:与磁盘中内容不一致,即从磁盘加载到物理内存后被改过就是脏的),如果是脏的还需要更新磁盘中的内容保证一致;
逐出后就腾出了位置给从磁盘中读到的这页的数据,然后需要更新页表的这一项的映射关系,将磁盘改为帧号,然后重新进行查页表这一步;
分页小结:
- 分页使得每个程序都有很大的逻辑地址空间,通过映射磁盘和高效的置换算法,使内存“无限大”;
- 分页使不同的进程的内存隔离,保证了安全;
- 分页降低了内存碎片问题;
但是上述分页过程中,需要两次读内存时间上有待优化,页表占用空间较大空间上也有待优化;
分页中的时间和空间优化
由上面的分析可知,要真正获取一个内存中的内容实际需要加载两次内存:一次是读取页表,一次是根据页表找到对应内存,因此可以进行时间上的优化;
并且,每个进程都需要维护一个页表,页表本身也是占内存空间的,因此也可以进行空间的优化;
时间优化
将最常访问的几个(一般8-128个左右)页表项储存到访问速度更快的硬件中,一般是在MMU(内存管理单元),这个小表的名称为*TLB (Translation Lookaside Buffer) *,可以称其为快表;
在寻址时,会先查询TLB,在miss后再查PT;
快表的命中率很高,这是由于程序的局部性原理,并且程序最常访问的页没几个;
其实本质上就是缓存的策略;
所以,这样的缓存就带来了程序并发执行的可见性问题;
空间优化
由于页表本身也占用内存,所以引入多级页表;
如上32位的系统和程序,一个程序要访问所有逻辑空间需要 2^20 个页面,对应2^20 个页表项;
如果每个页表项占4B的空间(32bit=4B),则一个程序维护的页表将占用4MB的物理内存!
4MB看起来很小,但是操作系统是要运行很多程序的!
如果使用多级页表,将23位分为4位、4位、12位的分级方式,最后一级指向物理地址,而第一级指向第二级,第二级指向第三级;
如果发现第一级只有3项指向第二级,且第二级的都有效,则只需要3*2^4=48个页表项;
程序内部的内存管理-分段
每个段有很多页,页表中存储段号和页号唯一映射物理地址帧号,即通过段号和页找找到唯一映射的帧号;严格意义的分段是,每一段的虚拟地址都是从0开始,然后页表是段号+页号来映射帧号的;
但是这种形式已经被废弃了,只有x86 32位的intel的cpu还保留了这种段页结合的方式,即严格意义的分段已经用的很少;
那为什么还经常听到段的概念?
现在所说的段一般是程序在逻辑层面保留的概念,对逻辑地址有个粗略的划分,便于程序编写,但是并不影响os的内存管理(还是分页管理);
以32位程序为例,如下图:
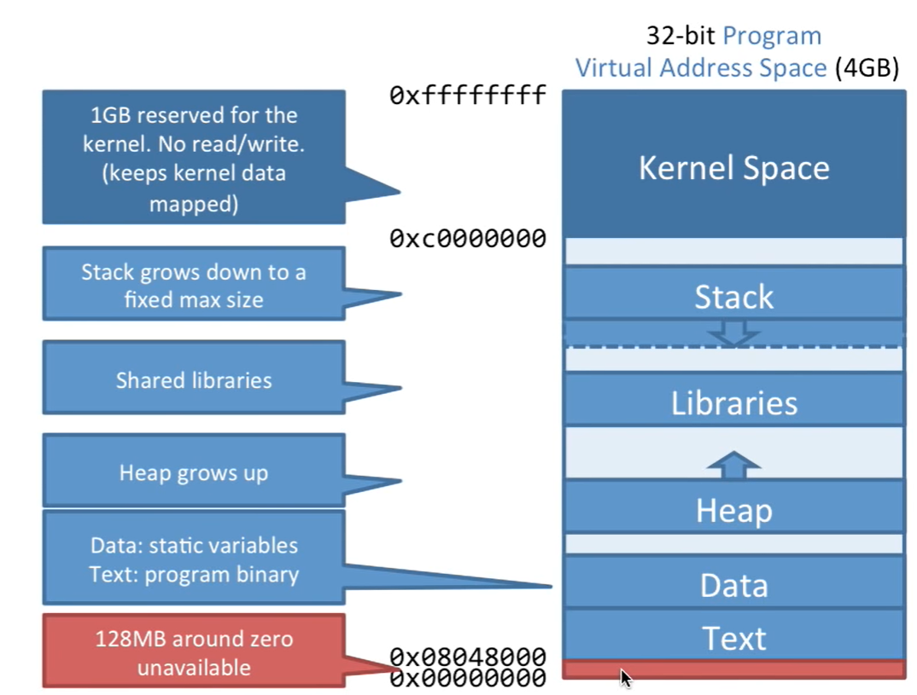
在逻辑空间中最高的0xc0000000 - 0xffffffff 这1G的内存是给内核留出的,剩余3G内存从低到高分别是Text、Data、Heap、Lib、Stack;
Heap是从低往高增长,Stack是从高往低增长,且有个最大限制;
Data存储静态变量Text存储程序二进制码;
Lib存储库函数需要占用的内存,多个程序如果都使用了相同的库,内存是共用的(共享内存);
同时各个部分的留有随机的一段偏移量,可以保护程序,这也使得每次执行程序的时候变量所在的内存地址总是不同的;
注:分段是逻辑空间上的,不影响分页的内存管理方式,后面进行分页,映射到物理内存上各部分跨多个页其实并不连续;
下图是两个程序在物理内存中的映射:
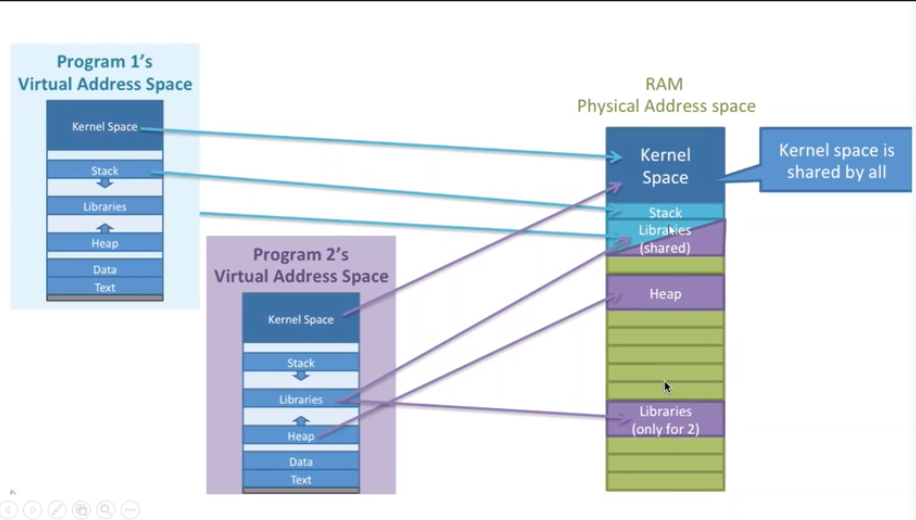
首先,Kernel部分的内存所有程序是共享的;
其次,他们有各自的堆区和栈区;
而对于Libraries区,则存在多个进程共享一个或者多个库(如Windows下的DLL或者Linux下的.so库);
Cache
CPU的三级缓存扮演着缓存主存数据的作用,而Cache在内存管理中的位置是怎样的呢?
PIPT:物理级cache,cpu分析完映射关系,先到Cache找有没有该物理地址的cache,这样会非常的慢,但是所有进程可以共享cache;
VIVT:逻辑级cache,cpu直接通过逻辑地址找cache,miss后再查TLB页表这些;这样很快,但是逻辑地址只能对当期进程使用,其他进程完全不能复用,尤其是库函数这种共享的不能利用好cache;
VIPT,将两者结合,用逻辑地址查找cache,cache中数据部分前面添加一个对应物理地址的tag;这样拿到这个tag后到tlb、页表中查看下这个对应关系是否正确,如果正确就直接读cache。这样速度和共享性都是折中的;
以上三种方式各有优劣,在不同的cpu中可能使用的不一样;
磁盘映射mmap与缺页异常
在记一次内存映射的过程的最后讲述了,如果页表映射到了磁盘的时候就会触发缺页异常,而这个过程其实是非常非常慢的;
建立磁盘与内存页映射关系有专门的系统调用:mmap;
mmap其实经常用在一些数据库的底层实现上,其实现原理大概就是:将数据文件映射到逻辑地址中;
而在进行查询的时候,是直接查询一个虚拟内存地址,然后首次访问可能会比较慢(缺页),但读取一次之后这页就补全了,后面访问该页的速度就会变快;
当然还是有很多细节的,比如:什么时候该逐出,页替换算法如何优化;
附录
更多内容推荐看:
- CSAPP
- 《程序员的自我修养》