
二维码现在已经是日常生活中随处可见的了,本文讲解了二维码的原理,并且最后手把手教你使用JS创建一个二维码;
本文译自:
生成二维码的原理
下面是一个JavaScript生成QR Code的demo:
https://www.nayuki.io/page/creating-a-qr-code-step-by-step
下面以生成HelloWorld的二维码为例讲述了通过JavaScript是如何实现的;
0.分析Unicode字符
HelloWorld包含了10个Unicode字符,每个字符的Unicode如下表:
| Index | Char | CP hex | NM | AM | BM | KM |
|---|---|---|---|---|---|---|
| 0 | H | U+48 | No | Yes | Yes | No |
| 1 | e | U+65 | No | No | Yes | No |
| 2 | l | U+6C | No | No | Yes | No |
| 3 | l | U+6C | No | No | Yes | No |
| 4 | o | U+6F | No | No | Yes | No |
| 5 | W | U+57 | No | Yes | Yes | No |
| 6 | o | U+6F | No | No | Yes | No |
| 7 | r | U+72 | No | No | Yes | No |
| 8 | l | U+6C | No | No | Yes | No |
| 9 | d | U+64 | No | No | Yes | No |
在对每个字符进行Encode编码时,要选择对应的编码方式,上面的NM、AM、BM、KM分别表示:
- Numeric:数值编码;
- Alphanumeric:字母数字编码;
- Byte:二进制编码;
- Kanji:汉字编码;
如下表:
| Mode | Encodable |
|---|---|
| Numeric | No |
| Alphanumeric | No |
| Byte | Yes |
| Kanji | No |
最后选择各个字符都可以使用的二进制编码进行编码:Byte;
1.创建数据段
将每个字符转换为bit位;
对于数字和字母数字模式而言,连续字符会被编码组合在一起;
对于字节模式,字符会产生8、16、24或32位;
如下表:
| Index | Char | Values (hex) | Bits |
|---|---|---|---|
| 0 | H | 48 | 01001000 |
| 1 | e | 65 | 01100101 |
| 2 | l | 6C | 01101100 |
| 3 | l | 6C | 01101100 |
| 4 | o | 6F | 01101111 |
| 5 | W | 57 | 01010111 |
| 6 | o | 6F | 01101111 |
| 7 | r | 72 | 01110010 |
| 8 | l | 6C | 01101100 |
| 9 | d | 64 | 01100100 |
创建的单个数据段如下:
- 模式:字节;
- 计数:10字节;
- 数据:80位长;
为了简单起见,这个演示程序创建了一个单独的段;
但也可以对文本进行最佳分割,以最小化总比特长度,见:
2.调整适应二维码版本号的数据段
实际的二维码表示每个数据段所需的总位长度,取决于版本:
| Range**** | Num bits | Num codewords |
|---|---|---|
| Version 1 ~ 9 | 148 | 19 |
| Version 10 ~ 26 | 156 | 20 |
| Version 27 ~ 40 | 156 | 20 |
注:一个
codeword被定义为8位,即一个字节(byte);
每个版本数据段的二维码容量和纠错级别,以及数据格式:
| Version | ECC L | ECC M | ECC Q | ECC H |
|---|---|---|---|---|
| 1 | 19 | 16 | 13 | 9 |
| 2 | 34 | 28 | 22 | 16 |
| 3 | 55 | 44 | 34 | 26 |
| 4 | 80 | 64 | 48 | 36 |
| 5 | 108 | 86 | 62 | 46 |
| 6 | 136 | 108 | 76 | 60 |
| 7 | … | … | … | … |
我们选择的版本是:1;
3.连接段、添加填充并生成代码字
将各个位字符串串连接在一起:
| Item | Bit data | Num bits | Sum bits |
|---|---|---|---|
| Segment 0 mode | 0100 | 4 | 4 |
| Segment 0 count | 00010001 | 8 | 12 |
| Segment 0 data | 01001000 01100101 01101100 01101100 01101111 00101100 00100000 01110111 01101111 01110010 01101100 01100100 00100001 00100000 00110001 00110010 00110011 |
136 | 148 |
| Terminator | 0000 | 4 | 152 |
| Bit padding | 0 | 152 | |
| Byte padding | 0 | 152 |
注:
- 每个段始终是4位;
- 总的字符数取决于二维码模式和版本;
- 通常情况下,结束符都为4个0,除非数据的字节数已经达到了二维码版本长度(会有更少的0);
- 位填充会在在0~7个0位之间,以填充最后一个字节中所有未使用的位;
- 字节填充由交替(十六进制)EC和11组成,直到达到二维码版本要求的容量;
整个数据位序列:
010000010010010010110010110110001101100011101001011000101100001000010111101110111011000110001100011000110001100011000110001100011000110000
若以十六进制显示整个序列,则是:
41 14 86 56 C6 C6 F2 C2 07 76 F7 26 C6 42 12 03 13 23 30
4.拆分块,添加ECC
上述整个十六进制被分为了多个块,信息如下:
| Number of data codewords: | 19 |
|---|---|
| Number of blocks: | 1 |
| Data codewords per short block: | 19 |
| Data codewords per long block: | N/A |
| ECC codewords per any block: | 7 |
| Number of short blocks: | 1 |
| Number of long blocks: | 0 |
将数据码字序列(0 ~ 19)拆分为短块和长块;
然后针对每个块,计算ECC码字(20 ~ 26)并将其附加到块的末尾:
:
| Block index | |
|---|---|
| 0 | |
| 0 | 41 |
| 1 | 14 |
| 2 | 86 |
| 3 | 56 |
| 4 | C6 |
| 5 | C6 |
| 6 | F2 |
| 7 | C2 |
| 8 | 07 |
| 9 | 76 |
| 10 | F7 |
| 11 | 26 |
| 12 | C6 |
| 13 | 42 |
| 14 | 12 |
| 15 | 03 |
| 16 | 13 |
| 17 | 23 |
| 18 | 30 |
| 19 | |
| 20 | 85 |
| 21 | A9 |
| 22 | 5E |
| 23 | 07 |
| 24 | 0A |
| 25 | 36 |
| 26 | C9 |
注:此处省略了计算Reed-Solomon纠错码的过程;
结合来自不同块的数据/ECC码字形成的最终码字序列:
41 14 86 56 C6 C6 F2 C2 07 76 F7 26 C6 42 12 3 13 30 85 A9 5E 07 0A 36 C9
对应的Z字扫描:
0100000100010100100001100101011011000110110001101111001011000010000001110111011011110111001001101100011001000010000100100000001100010011001000110011000010000101101010010101111000000111000010100011011011001001
5.绘制固定图案
绘制水平和垂直基准线(在第6行和第6列上,从左上角开始,从0开始计算):

在三个角绘制7×7查找器图案(此时会覆盖一些基准模块):

在查找器相邻区域绘制临时的格式占位图案:
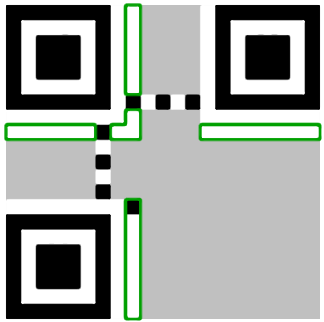
6.绘制代码字
计算Z字形扫描(从右下角开始)访问所有未填充的模块(跳过部分已经确定的部分):

根据Z字形扫描顺序和最终码字序列的位值绘制数据/ECC模块:

例如,二进制代码字的字节C5对应二进制为11000101,则生成模块序列:
黑、黑、白、白、白、黑、白、黑;
7.添加Mask遮罩
有多种Mask的样式,Mask的样式仅影响非确定部分:

将数据、ECC和剩余其他部分和Mask进行异或:

紧靠查找器绘制实际的格式位:

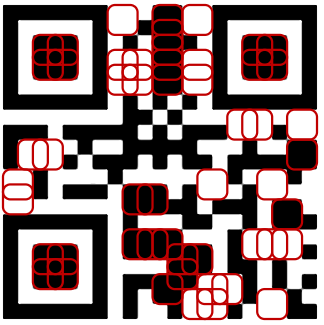
8.寻找多余的样式
水平相同颜色的区域(每个至少5个单位长):

垂直相同颜色的区域(每个至少5个单位长):

2×2颜色相同的区域:
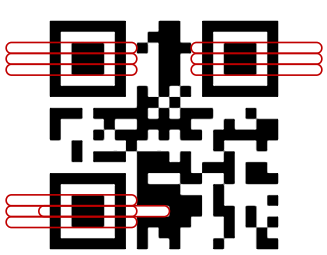
水平和查找器相同的样式:
垂直和查找器相同的样式:
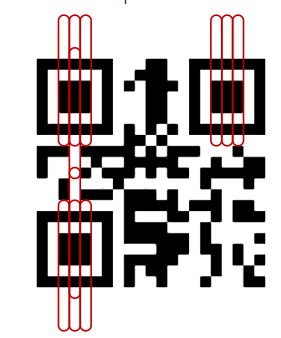
我认为,此步操作是为了避免识别到多个查找器样式;
结果统计:
| Side length: | 21 |
|---|---|
| Total modules: | 441 |
| White modules: | 217 |
| Black modules: | 224 |
| Proportion black: | 50.794% |
| Deviation from half: | 0.794% |
9.计算罚分,选择最佳Mask
| Mask | RunP | BoxP | FindP | BalP | TotalP |
|---|---|---|---|---|---|
| 0 | 205 | 159 | 840 | 0 | 1204 |
| 1 | 187 | 147 | 800 | 0 | 1134 |
| 2 | 173 | 111 | 800 | 0 | 1084 |
| 3 | 167 | 114 | 800 | 0 | 1081 |
| 4 | 195 | 126 | 800 | 0 | 1121 |
| 5 | 181 | 159 | 760 | 0 | 1100 |
| 6 | 183 | 126 | 880 | 0 | 1189 |
| 7 | 183 | 114 | 840 | 0 | 1137 |
最低总罚分:Mask 3;
如何计算罚分:
- RunP:相同颜色的每连续5个点为3分,每连续6个点为4分,每连续7个点为5分,等等;
- BoxP:同色每2×2盒为3分。框可以重叠;
- FindP:每个和扫描器类似的样式(
finder-like)图案得40分。可以重叠计分; - BalP:黑色模块比例在[45%,55%]范围内得0分;在[40%,60%]范围内得10分;在[35%,65%]范围内得20分;在[30%,70%]范围内得30分;以此类推;
附录
本文译自:
延申阅读: