
前面两篇文章分析了Java中几种常见的线程池, 下面我们通过源码来看一看他们究竟在最底层是怎么实现的
本文内容包括:
- ctl属性;
- ThreadPoolExecutor中其他属性;
- 任务提交的实现;
- 内部类Worker(任务执行, 终止)
- 线程池终止
- 线程池的监控
- 线程池的安排
源代码分析基于JDK11.0.5
如果觉得文章写的不错, 可以关注微信公众号: Coder张小凯
内容和博客同步更新~
系列文章入口:
Java线程池ThreadPoolExecutor分析与实战终
上一篇讲解了Executor, ExecutorSerivce和AbstractExecutorService的源码
然后Java中存在的4种线程池的工作原理, 趁热打铁, 下面看一看ThreadPoolExecutor的源码
ThreadPoolExecutor
ThreadPoolExecutor的源码如下, 一共2100行, 我们慢慢理解:
package java.util.concurrent;
import java.util.ArrayList;
import java.util.ConcurrentModificationException;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
/**
* 一种ExecutorService
* 它使用几个池线程类型中的一个执行每个提交的任务
* 通常使用Executors工厂方法配置创建
*
* An {@link ExecutorService} that executes each submitted task using
* one of possibly several pooled threads, normally configured
* using {@link Executors} factory methods.
*
* 线程池解决了两个不同的问题:
* 1.它们通常在执行大量异步任务时提供更好的性能,这是由于减少了每个任务的调用开销;
* 2.并且它们提供了一种限制和管理资源(包括执行任务集合时消耗的线程)的方法
*
* 每个ThreadPoolExecutor还维护一些基本统计信息,例如已完成的任务数
*
* <p>Thread pools address two different problems: they usually
* provide improved performance when executing large numbers of
* asynchronous tasks, due to reduced per-task invocation overhead,
* and they provide a means of bounding and managing the resources,
* including threads, consumed when executing a collection of tasks.
* Each {@code ThreadPoolExecutor} also maintains some basic
* statistics, such as the number of completed tasks.
*
* 为了在各种上下文中(场景)使用
* 这个类提供了许多可调整的参数和可扩展的hook方法
* 但是,程序员应该使用更方便的Executors工厂方法
* 1.Executors{newCachedThreadPool}(无限制线程池,自动回收线程)
* 2.Executors{newFixedThreadPool}(固定大小的线程池)
* 3.Executors{newSingleThreadExecutor}(单后台线程)
* 为最常见的使用场景预先配置设置
*
* 否则,在手动配置和调整此类时,请使用以下指南:
*
* <p>To be useful across a wide range of contexts, this class
* provides many adjustable parameters and extensibility
* hooks. However, programmers are urged to use the more convenient
* {@link Executors} factory methods {@link
* Executors#newCachedThreadPool} (unbounded thread pool, with
* automatic thread reclamation), {@link Executors#newFixedThreadPool}
* (fixed size thread pool) and {@link
* Executors#newSingleThreadExecutor} (single background thread), that
* preconfigure settings for the most common usage
* scenarios. Otherwise, use the following guide when manually
* configuring and tuning this class:
*
* <dl>
*
* 核心池和最大池大小
*
* <dt>Core and maximum pool sizes</dt>
*
* ThreadPoolExecutor将根据:
* corePoolSize和maximumPoolSize设置的界限自动调整池大小
*
* <dd>A {@code ThreadPoolExecutor} will automatically adjust the
* pool size (see {@link #getPoolSize})
* according to the bounds set by
* corePoolSize (see {@link #getCorePoolSize}) and
* maximumPoolSize (see {@link #getMaximumPoolSize}).
*
* 在方法execute(Runnable)中提交新任务时
* 如果正在运行的线程少于corePoolSize,则会创建一个新线程来处理该请求
* (即使其他工作线程处于空闲状态)
*
* 否则,如果运行的线程少于maximumPoolSize,则仅当队列已满时,才会创建一个新线程来处理该请求
* 1.通过将corePoolSize和maximumPoolSize设置为相同的值,可以创建一个固定大小的线程池
* 2.通过将maximumPoolSize设置为本质上无边界的值,例如Integer.MAX_value,可以允许池容纳任意数量的并发任务
* 最典型的情况是,核心池和最大池大小仅在构造时设置
* 但也可以使用setCorePoolSize和setMaximumPoolSize动态更改它们
*
* When a new task is submitted in method {@link #execute(Runnable)},
* if fewer than corePoolSize threads are running, a new thread is
* created to handle the request, even if other worker threads are
* idle. Else if fewer than maximumPoolSize threads are running, a
* new thread will be created to handle the request only if the queue
* is full. By setting corePoolSize and maximumPoolSize the same, you
* create a fixed-size thread pool. By setting maximumPoolSize to an
* essentially unbounded value such as {@code Integer.MAX_VALUE}, you
* allow the pool to accommodate an arbitrary number of concurrent
* tasks. Most typically, core and maximum pool sizes are set only
* upon construction, but they may also be changed dynamically using
* {@link #setCorePoolSize} and {@link #setMaximumPoolSize}. </dd>
*
* 按需构造
*
* <dt>On-demand construction</dt>
*
* 默认情况下,即使核心线程最初也是在新任务到达时创建和启动的
* 也可以使用方法prestartCoreThread或prestartcorethreads动态重写
* 如果使用非空队列构造线程池,则可能需要预启动线程
*
* <dd>By default, even core threads are initially created and
* started only when new tasks arrive, but this can be overridden
* dynamically using method {@link #prestartCoreThread} or {@link
* #prestartAllCoreThreads}. You probably want to prestart threads if
* you construct the pool with a non-empty queue. </dd>
*
* 创建新线程
*
* <dt>Creating new threads</dt>
*
* 使用ThreadFactory创建新线程
* 如果未另行指定,则使用Executors.defaultThreadFactory
* 它创建的线程都处于相同的ThreadGroup,并且具有相同的NORM_PRIORITY优先级和非守护进程状态
* 通过提供不同的ThreadFactory,可以更改线程的名称、线程组、优先级、守护进程状态等
*
* 如果ThreadFactory在从newThread返回null时无法创建线程,则执行器将继续,但可能无法执行任何任务
* 线程应该拥有modifyThread(RuntimePermission)
* 如果工作线程或使用池的其他线程不具有此权限,则服务可能会降级:
* 配置更改可能不会及时生效,关闭池可能仍处于可以终止但未完成的状态
*
* <dd>New threads are created using a {@link ThreadFactory}. If not
* otherwise specified, a {@link Executors#defaultThreadFactory} is
* used, that creates threads to all be in the same {@link
* ThreadGroup} and with the same {@code NORM_PRIORITY} priority and
* non-daemon status. By supplying a different ThreadFactory, you can
* alter the thread's name, thread group, priority, daemon status,
* etc. If a {@code ThreadFactory} fails to create a thread when asked
* by returning null from {@code newThread}, the executor will
* continue, but might not be able to execute any tasks. Threads
* should possess the "modifyThread" {@code RuntimePermission}. If
* worker threads or other threads using the pool do not possess this
* permission, service may be degraded: configuration changes may not
* take effect in a timely manner, and a shutdown pool may remain in a
* state in which termination is possible but not completed.</dd>
*
* 线程生存时间
*
* <dt>Keep-alive times</dt>
*
* 如果池当前有多个corePoolSize线程,则如果多余的线程空闲时间超过keepAliveTime,则将终止这些线程
* 这提供了一种在池未被积极使用时减少资源消耗的方法
* 如果线程池稍后变得更为活跃,则将构造新线程
* 也可以使用方法setKeepAliveTime(long,TimeUnit)动态更改此参数
*
* 使用Long.MAX_value, TimeUnit.NANOSECONDS的值可以有效地禁止空闲线程在关闭之前终止
* 默认情况下,keep-alive策略仅在存在多个corePoolSize线程时应用
* 但是只要keep alive time值非零,也可以使用方法allowCoreThreadTimeOut(true)
* 将此超时策略应用于核心线程
*
* <dd>If the pool currently has more than corePoolSize threads,
* excess threads will be terminated if they have been idle for more
* than the keepAliveTime (see {@link #getKeepAliveTime(TimeUnit)}).
* This provides a means of reducing resource consumption when the
* pool is not being actively used. If the pool becomes more active
* later, new threads will be constructed. This parameter can also be
* changed dynamically using method {@link #setKeepAliveTime(long,
* TimeUnit)}. Using a value of {@code Long.MAX_VALUE} {@link
* TimeUnit#NANOSECONDS} effectively disables idle threads from ever
* terminating prior to shut down. By default, the keep-alive policy
* applies only when there are more than corePoolSize threads, but
* method {@link #allowCoreThreadTimeOut(boolean)} can be used to
* apply this time-out policy to core threads as well, so long as the
* keepAliveTime value is non-zero. </dd>
*
* 队列
*
* <dt>Queuing</dt>
*
* 任何BlockingQueue都可以用来传输和保存提交的任务, 此队列的使用与池大小有关:
*
* <dd>Any {@link BlockingQueue} may be used to transfer and hold
* submitted tasks. The use of this queue interacts with pool sizing:
*
* <ul>
*
* 如果运行的线程少于corePoolSize,则执行器总是倾向于添加新线程,而不是排队
*
* <li>If fewer than corePoolSize threads are running, the Executor
* always prefers adding a new thread
* rather than queuing.
*
* 如果corePoolSize或更多线程正在运行,则执行器总是希望将请求排队,而不是添加新线程
*
* <li>If corePoolSize or more threads are running, the Executor
* always prefers queuing a request rather than adding a new
* thread.
*
* 如果请求不能排队,则创建一个新线程
* 除非该线程超过maximumPoolSize,在这种情况下,任务将被拒绝
*
* <li>If a request cannot be queued, a new thread is created unless
* this would exceed maximumPoolSize, in which case, the task will be
* rejected.
*
* </ul>
*
* 排队的一般策略有三种:
*
* There are three general strategies for queuing:
* <ol>
*
* 直接交接
* 工作队列的一个很好的默认选择是SynchronousQueue,它将任务直接交给线程,而不必保存它们
* 在这里,如果没有线程可以立即运行任务,则尝试对任务进行排队将失败,因此将构造一个新线程
* 此策略在处理可能具有内部依赖项的请求集时避免锁定
* 直接切换通常需要无限的队列大小,以避免拒绝新提交的任务
* 这反过来又造成了当命令的平均到达速度超过可以处理的速度时,无限线程增长的可能性
*
* <li><em> Direct handoffs.</em> A good default choice for a work
* queue is a {@link SynchronousQueue} that hands off tasks to threads
* without otherwise holding them. Here, an attempt to queue a task
* will fail if no threads are immediately available to run it, so a
* new thread will be constructed. This policy avoids lockups when
* handling sets of requests that might have internal dependencies.
* Direct handoffs generally require unbounded maximumPoolSizes to
* avoid rejection of new submitted tasks. This in turn admits the
* possibility of unbounded thread growth when commands continue to
* arrive on average faster than they can be processed.
*
* 无界队列
* 使用无界队列(例如LinkedBlockingQueue没有预定义的容量)
* 将导致新任务在所有corePoolSize线程忙时在队列中等待
* 因此,不会创建超过corePoolSize的线程(所以maximumPoolSize的值没有任何影响)
* 当每个任务完全独立于其他任务时,任务不会影响彼此的执行;
* 例如,在web页面服务器中
* 虽然这种排队方式有助于消除请求的暂时性突发
* 但它允许在命令平均到达速度超过其处理速度时,无限工作队列增长的可能性
*
* <li><em> Unbounded queues.</em> Using an unbounded queue (for
* example a {@link LinkedBlockingQueue} without a predefined
* capacity) will cause new tasks to wait in the queue when all
* corePoolSize threads are busy. Thus, no more than corePoolSize
* threads will ever be created. (And the value of the maximumPoolSize
* therefore doesn't have any effect.) This may be appropriate when
* each task is completely independent of others, so tasks cannot
* affect each others execution; for example, in a web page server.
* While this style of queuing can be useful in smoothing out
* transient bursts of requests, it admits the possibility of
* unbounded work queue growth when commands continue to arrive on
* average faster than they can be processed.
*
* 有界队列
* 有界队列(例如ArrayBlockingQueue)
* 有助于防止在与有限的maximumPoolSizes一起使用时资源耗尽,但可能更难进行优化和控制
* 队列大小和最大池大小可以相互交换:
* 1.使用大队列和小池可以最小化CPU使用率、操作系统资源和上下文切换开销,但可能导致人为的低吞吐量; 如果任务经常阻塞(例如,如果它们是I/O绑定的),系统可能(比创建更多的线程运行时)使用更长时间;
* 2.使用小队列通常需要较大的池大小,这使得cpu更加繁忙,可能会遇到不可接受的调度开销,这也会降低吞吐量
*
* <li><em>Bounded queues.</em> A bounded queue (for example, an
* {@link ArrayBlockingQueue}) helps prevent resource exhaustion when
* used with finite maximumPoolSizes, but can be more difficult to
* tune and control. Queue sizes and maximum pool sizes may be traded
* off for each other: Using large queues and small pools minimizes
* CPU usage, OS resources, and context-switching overhead, but can
* lead to artificially low throughput. If tasks frequently block (for
* example if they are I/O bound), a system may be able to schedule
* time for more threads than you otherwise allow. Use of small queues
* generally requires larger pool sizes, which keeps CPUs busier but
* may encounter unacceptable scheduling overhead, which also
* decreases throughput.
*
* </ol>
*
* </dd>
*
* 拒绝策略
*
* <dt>Rejected tasks</dt>
*
* 在方法execute(Runnable)中提交的新任务将在:
* 1.执行器关闭
* 2.执行器对最大线程工作队列容量使用有限边界且已饱和
* 时被拒绝
* 在这两种情况下,execute方法都会调用其
* RejectedExecutionHandler的RejectedExecutionHandler方法的RejectedExecutionHandler}
*
* JDK提供了四个预定义的处理程序策略:
*
* <dd>New tasks submitted in method {@link #execute(Runnable)} will be
* <em>rejected</em> when the Executor has been shut down, and also when
* the Executor uses finite bounds for both maximum threads and work queue
* capacity, and is saturated. In either case, the {@code execute} method
* invokes the {@link
* RejectedExecutionHandler#rejectedExecution(Runnable, ThreadPoolExecutor)}
* method of its {@link RejectedExecutionHandler}. Four predefined handler
* policies are provided:
*
* <ol>
*
* 默认的ThreadPoolExecutor.AbortPolicy:
* 处理程序在拒绝时抛出运行时RejectedExecutionException
*
* <li>In the default {@link ThreadPoolExecutor.AbortPolicy}, the handler
* throws a runtime {@link RejectedExecutionException} upon rejection.
*
* ThreadPoolExecutor.CallerRunsPolicy:
* 调用execute本身的线程运行该任务
* 这提供了一个简单的反馈控制机制,可以降低提交新任务的速度
*
* <li>In {@link ThreadPoolExecutor.CallerRunsPolicy}, the thread
* that invokes {@code execute} itself runs the task. This provides a
* simple feedback control mechanism that will slow down the rate that
* new tasks are submitted.
*
* ThreadPoolExecutor.DiscardPolicy:
* 无法执行的任务将被简单地删除
*
* <li>In {@link ThreadPoolExecutor.DiscardPolicy}, a task that
* cannot be executed is simply dropped.
*
* ThreadPoolExecutor.DiscardOldestPolicy:
* 如果未关闭执行器,则删除工作队列头部的任务,然后重试执行
* (这可能会再次失败,导致重复执行)
*
* <li>In {@link ThreadPoolExecutor.DiscardOldestPolicy}, if the
* executor is not shut down, the task at the head of the work queue
* is dropped, and then execution is retried (which can fail again,
* causing this to be repeated.)
*
* </ol>
*
* 可以定义和使用其他类型的RejectedExecutionHandler类
* 这样做需要注意,特别是当策略设计为仅在特定容量或排队策略下工作时
*
* It is possible to define and use other kinds of {@link
* RejectedExecutionHandler} classes. Doing so requires some care
* especially when policies are designed to work only under particular
* capacity or queuing policies. </dd>
*
* 钩子方法
*
* <dt>Hook methods</dt>
*
* 此类提供在执行每个任务之前和之后调用的(protected)可重写的beforeExecute和afterExecute方法
* 它们可用于操作执行环境, 例如:
* 重新初始化ThreadLocals、收集统计信息或添加日志项
* 此外,可以重写方法terminated,以便在执行器完全终止后执行任何需要执行的特殊处理
*
* <dd>This class provides {@code protected} overridable
* {@link #beforeExecute(Thread, Runnable)} and
* {@link #afterExecute(Runnable, Throwable)} methods that are called
* before and after execution of each task. These can be used to
* manipulate the execution environment; for example, reinitializing
* ThreadLocals, gathering statistics, or adding log entries.
* Additionally, method {@link #terminated} can be overridden to perform
* any special processing that needs to be done once the Executor has
* fully terminated.
*
* 如果hook、callback或BlockingQueue方法抛出异常
* 则内部工作线程可能会依次失败、突然终止并可能被替换
*
* <p>If hook, callback, or BlockingQueue methods throw exceptions,
* internal worker threads may in turn fail, abruptly terminate, and
* possibly be replaced.</dd>
*
* 队列维护
*
* <dt>Queue maintenance</dt>
*
* 方法getQueue()允许访问工作队列以进行监视和调试
* 强烈建议不要将此方法用于任何其他目的
* 提供的两个方法remove和purge可用于在取消大量排队任务时协助存储回收
*
* <dd>Method {@link #getQueue()} allows access to the work queue
* for purposes of monitoring and debugging. Use of this method for
* any other purpose is strongly discouraged. Two supplied methods,
* {@link #remove(Runnable)} and {@link #purge} are available to
* assist in storage reclamation when large numbers of queued tasks
* become cancelled.</dd>
*
* 回收
*
* <dt>Reclamation</dt>
*
* 程序中不再引用且没有剩余线程的池可以在不显式关闭的情况下回收(垃圾回收)
* 通过设置适当的保持活动时间、使用零核心线程的下限和/或设置allowCoreThreadTimeOut(true)
* 可以将池配置为允许所有未使用的线程最终消亡
*
* <dd>A pool that is no longer referenced in a program <em>AND</em>
* has no remaining threads may be reclaimed (garbage collected)
* without being explicitly shutdown. You can configure a pool to
* allow all unused threads to eventually die by setting appropriate
* keep-alive times, using a lower bound of zero core threads and/or
* setting {@link #allowCoreThreadTimeOut(boolean)}. </dd>
*
* </dl>
*
* 扩展例子:
* 这个类的大多数扩展重写了一个或多个受保护的钩子方法
* 例如,下面是一个子类,它添加了一个简单的暂停/恢复功能:
*
* <p><b>Extension example</b>. Most extensions of this class
* override one or more of the protected hook methods. For example,
* here is a subclass that adds a simple pause/resume feature:
*
* <pre> {@code
* class PausableThreadPoolExecutor extends ThreadPoolExecutor {
* private boolean isPaused;
* private ReentrantLock pauseLock = new ReentrantLock();
* private Condition unpaused = pauseLock.newCondition();
*
* public PausableThreadPoolExecutor(...) { super(...); }
* // 重写执行前方法
* protected void beforeExecute(Thread t, Runnable r) {
* super.beforeExecute(t, r);
* pauseLock.lock();
* try {
* while (isPaused) unpaused.await();
* } catch (InterruptedException ie) {
* t.interrupt();
* } finally {
* pauseLock.unlock();
* }
* }
* // 停止
* public void pause() {
* pauseLock.lock();
* try {
* isPaused = true;
* } finally {
* pauseLock.unlock();
* }
* }
* // 恢复
* public void resume() {
* pauseLock.lock();
* try {
* isPaused = false;
* unpaused.signalAll();
* } finally {
* pauseLock.unlock();
* }
* }
* }}</pre>
*
* @since 1.5
* @author Doug Lea
*/
public class ThreadPoolExecutor extends AbstractExecutorService {
/**
* 主池控制状态ctl属性是一个原子整数, 包含两个概念字段:
* 1.workerCount: 指示线程的有效运行状态数;
* 2.runState: 指示是否正在运行、正在关闭等;
*
* The main pool control state, ctl, is an atomic integer packing
* two conceptual fields
* workerCount, indicating the effective number of threads
* runState, indicating whether running, shutting down etc
*
* 为了将它们打包成一个int
* 我们将workerCount限制为(2^29)-1[大约5亿]线程,而不是(2^31)-1[20亿]线程
* 如果将来出现这种情况(线程数超过5亿):
* 可以将变量更改为AtomicLong, 并调整下面的shift/mask常量
* 但是在需要这样改变之前,使用int代码会更快更简单
*
* In order to pack them into one int, we limit workerCount to
* (2^29)-1 (about 500 million) threads rather than (2^31)-1 (2
* billion) otherwise representable. If this is ever an issue in
* the future, the variable can be changed to be an AtomicLong,
* and the shift/mask constants below adjusted. But until the need
* arises, this code is a bit faster and simpler using an int.
*
* workerCount是允许启动和不允许停止的工人数
* 该值可能暂时不同于活动线程的实际数量, 例如:
* 1.当线程工厂在被请求时无法创建线程
* 2.当退出的线程在终止前仍在执行记帐(仍然在数量上, 未被减一)时
* 用户可见池大小为工作集的当前大小
*
* The workerCount is the number of workers that have been
* permitted to start and not permitted to stop. The value may be
* transiently different from the actual number of live threads,
* for example when a ThreadFactory fails to create a thread when
* asked, and when exiting threads are still performing
* bookkeeping before terminating. The user-visible pool size is
* reported as the current size of the workers set.
*
* 运行状态提供主生命周期控制,具有以下值:
*
* RUNNING: 接受新任务并处理排队的任务
* SHUTDOWN: 不接受新任务,但处理排队的任务
* STOP: 不接受新任务、不处理排队的任务和中断正在进行的任务
* TIDYING: 所有任务都已终止,workerCount为零, 状态转换为tiding的线程将运行terminated()钩子方法
* TERMINATED: terminated()方法已完成
*
* The runState provides the main lifecycle control, taking on values:
*
* RUNNING: Accept new tasks and process queued tasks
* SHUTDOWN: Don't accept new tasks, but process queued tasks
* STOP: Don't accept new tasks, don't process queued tasks,
* and interrupt in-progress tasks
* TIDYING: All tasks have terminated, workerCount is zero,
* the thread transitioning to state TIDYING
* will run the terminated() hook method
* TERMINATED: terminated() has completed
*
* 这些值之间的数字顺序很重要,以便进行有序比较
* 运行状态随时间单调地增加,但不必命中每个状态, 状态过渡是:
*
* RUNNING -> SHUTDOWN: 调用shutdown()方法时
*
* (RUNNING or SHUTDOWN) -> STOP: 在调用shutdownNow()方法时
*
* SHUTDOWN -> TIDYING: 当队列和池都为空时
*
* STOP -> TIDYING: 当池为空时
*
* TIDYING -> TERMINATED: 当terminated()钩子方法完成时
*
* The numerical order among these values matters, to allow
* ordered comparisons. The runState monotonically increases over
* time, but need not hit each state. The transitions are:
*
* RUNNING -> SHUTDOWN
* On invocation of shutdown()
* (RUNNING or SHUTDOWN) -> STOP
* On invocation of shutdownNow()
* SHUTDOWN -> TIDYING
* When both queue and pool are empty
* STOP -> TIDYING
* When pool is empty
* TIDYING -> TERMINATED
* When the terminated() hook method has completed
*
* 等待awaitTermination()的线程将在状态达到TERMINATED时返回
*
* Threads waiting in awaitTermination() will return when the
* state reaches TERMINATED.
*
* 检测从SHUTDOWN到TIDYING的转换比想象的要简单得多
* 因为队列在(正常工作)非空之后可能变空,在SHUTDOWN状态下也可能变空
* 但我们只在看到它为空之后又看到workerCount为0(有时需要重新检查——见下文)时终止
*
* Detecting the transition from SHUTDOWN to TIDYING is less
* straightforward than you'd like because the queue may become
* empty after non-empty and vice versa during SHUTDOWN state, but
* we can only terminate if, after seeing that it is empty, we see
* that workerCount is 0 (which sometimes entails a recheck -- see
* below).
*/
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
// runState存储在高阶位中
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 打包和解包ctl(线程池生命周期属性)
private static int runStateOf(int c) { return c & ~COUNT_MASK; }
private static int workerCountOf(int c) { return c & COUNT_MASK; }
// 参数rs表示runState
// 参数wc表示workerCount
// 即根据runState和workerCount打包合并成ctl
private static int ctlOf(int rs, int wc) { return rs | wc; }
// 不需要解包ctl的位字段访问器
// 这取决于bit的layout和workerCount永不为负
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
private static boolean isRunning(int c) {
return c < SHUTDOWN;
}
/**
* 尝试CAS递增ctl的workerCount字段(增加工作线程)
*/
private boolean compareAndIncrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect + 1);
}
/**
* 尝试CAS减少ctl的workerCount字段
*/
private boolean compareAndDecrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect - 1);
}
/**
* 递减ctl的workerCount字段
* 此方法只在线程突然终止时调用(processWorkerExit方法)
* 其他减量在getTask中执行
*/
private void decrementWorkerCount() {
ctl.addAndGet(-1);
}
/**
* 用于保存任务并将其传递给工作线程的队列
* 我们不要求workQueue.poll()返回空值必然意味着workQueue.isEmpty()
* 因此仅依赖于isEmpty来查看队列是否为空
* 例如: 在决定是否从关闭过渡到整理时,我们必须这样做
* 这适用于特殊用途的队列,例如DelayQueues的poll()方法允许返回空值,即使稍后在延迟到期时可能返回非空值
*/
private final BlockingQueue<Runnable> workQueue;
/**
* 对workers Set和related bookkeeping的访问保持锁定
*
* 虽然我们可以使用某种类型的并发集合,但通常最好使用锁
* 其中一个原因是,这会序列化InterruptedWorkers,从而避免不必要的中断风暴
* (特别是在shutdown期间)
* 否则,退出的线程将同时中断那些尚未中断的线程
* 它还简化了一些与最大池大小等相关的统计工作
* 在shutdown和shutdownNow执行时,还会获取mainLock,以确保在分别检查允许中断和实际中断的情况下,workers集合是稳定的
*/
private final ReentrantLock mainLock = new ReentrantLock();
/**
* 包含池中所有工作线程的Set集合, 仅在获取mainLock时能够访问
*/
private final HashSet<Worker> workers = new HashSet<>();
/**
* 提供给awaitTermination方法的等待条件
*/
private final Condition termination = mainLock.newCondition();
/**
* 跟踪最大的已达到池大小, 仅在获取mainLock时能够访问
*/
private int largestPoolSize;
/**
* 已完成任务的计数器, 仅在工作线程终止时更新, 仅在获取mainLock时能够访问
*/
private long completedTaskCount;
/*
* 所有用户控制参数都声明为volatile
* 因此正在进行的操作总是基于最新的值,但不需要锁定
* 因为相对于其他操作的同步更改来说, 没有内部常量依赖于它们
*/
/**
* 线程工厂: 所有线程都是使用此工厂(通过addWorker方法)
* 所有调用方都必须为addWorker失败做好准备
* 这反映了系统或用户限制线程数的策略
* 即使不将其视为错误,创建线程失败也可能导致新任务被拒绝或现有任务仍滞留在队列中
*
* 我们进一步保留线程池池变量配置,而继续创建Thread, 可能会遇到OutOfMemoryError之类的错误
* (由于创建线程需要在Thread.start中分配本机堆栈,因此此类错误相当常见)
* 此时用户将希望执行清理池关闭以进行清理
* 如果有足够的内存供清理代码完成,此时则不会遇到另一个OutOfMemory错误
*/
private volatile ThreadFactory threadFactory;
/**
* 在执行中线程池饱和或线程池关闭时调用的拒绝策略方法
*/
private volatile RejectedExecutionHandler handler;
/**
* 等待工作的空闲线程超时时间(以纳秒为单位)
* 当存在超过corePoolSize数量的线程存在或设置了allowCoreThreadTimeOut时使用此超时
* 否则他们会永远等待新的工作
*/
private volatile long keepAliveTime;
/**
* 如果为false(默认值), 则核心线程即使处于空闲状态也不会被回收
* 如果为true,则核心线程使用keepAliveTime超时回收
*/
private volatile boolean allowCoreThreadTimeOut;
/**
* corePoolSize是要保持活动状态(并且不允许超时等)的最小工作线程数
* 除非设置allowCoreThreadTimeOut(在这种情况下,最小值为零)
*
* 由于worker count实际上存储在COUNT_BITS中
* 因此真正的限制数是: corePoolSize & COUNT_MASK
*/
private volatile int corePoolSize;
/**
* 最大池大小。
*
* 由于worker count实际上存储在COUNT_BITS中
* 因此真正的限制数是: maximumPoolSize & COUNT_MASK
*/
private volatile int maximumPoolSize;
/**
* 默认的拒绝执行处理器(默认为AbortPolicy, 即抛出异常)
*/
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
/**
* 关闭和立即关闭的调用方所需的权限
* 我们还要求(见checkShutdownAccess方法)调用者有权实际中断(actually interrupt)worker集合中的线程
* (由Thread.interrupt()控制, ThreadGroup.checkAccess依赖, 而ThreadGroup.checkAccess又依赖于SecurityManager.checkAccess)
* 只有当这些检查通过时,才会尝试关闭
*
* 所有对Thread.interrupt的实际调用(请参阅interruptdleworkers和interruptWorkers)都忽略了SecurityExceptions
* 这意味着尝试的中断会自动失败
* 在关闭的情况下,除非SecurityManager有不一致的策略
* (有时允许访问线程,有时不允许)否则它们不应该失败
* 在这种情况下,未能真正中断线程可能会禁用或延迟完全终止
* interruptibleworks的其他用途是建议性的
* 而未能真正中断只会延迟对配置更改的响应,因此不会进行异常处理
*/
private static final RuntimePermission shutdownPerm =
new RuntimePermission("modifyThread");
/**
* Worker类主要维护运行任务的线程的中断控制状态,以及其他次要的记录行为
* 这个类扩展了AbstractQueuedSynchronizer, 以简化获取和释放围绕每个任务执行的锁的过程
* 这可以防止在唤醒等待任务的工作线程而不是中断正在运行的任务的中断
* 我们实现了一个简单的不可重入互斥锁,而不是使用ReentrantLock
* 因为我们不希望工作任务在调用setCorePoolSize之类的池控制方法时能够重新获取锁
* 另外,为了在线程真正开始运行任务之前禁止中断,我们将锁状态初始化为负值,并在启动时清除它(在runWorker中)
*/
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* 这个类永远不会被序列化,但是我们提供了一个serialVersionUID来禁止javac警告
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Worker类的工作线程; 如果工厂失败创建失败,则为空 */
final Thread thread;
/** 要运行的初始任务, 可能为空 */
Runnable firstTask;
/** 每个线程的任务计数器 */
volatile long completedTasks;
// TODO: switch to AbstractQueuedLongSynchronizer and move
// completedTasks into the lock word.
/**
* 使用给定的第一个任务和ThreadFactory创建线程
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // 禁止中断runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** 将执行任务委托给外部runWorker */
public void run() {
runWorker(this);
}
// 锁定方法
// 0表示未锁定状态
// 1表示锁定状态
// 是否被锁定(判断状态是否不为0)
protected boolean isHeldExclusively() {
return getState() != 0;
}
// 通过CAS操作尝试获取锁
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// 释放锁
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
// 获取锁, 未获得则一直自旋
public void lock() { acquire(1); }
// 尝试获取锁(通过CAS, 获取到返回true)
public boolean tryLock() { return tryAcquire(1); }
// 释放锁
public void unlock() { release(1); }
// 判断当前工作线程是否被锁定
public boolean isLocked() { return isHeldExclusively(); }
// 如果当前线程正在工作, 则中断
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
/*
* 控制状态设置方法
*/
/**
* 将运行状态转换为给定target,或者如果已经至少是给定目标,则将其保留状态
*
* @param targetState 转换的目标状态,SHUTDOWN or STOP
* (但不能是TIDYING or TERMINATED --使用tryTerminate)
*/
private void advanceRunState(int targetState) {
// assert targetState == SHUTDOWN || targetState == STOP;
for (;;) {
// 获取运行状态
int c = ctl.get();
// 短路运算符
// 如果当前状态大于targetState(c >= targetState)直接返回
// 否则CAS操作更新状态(自旋)
// workerCountOf()方法计算实际的状态数值
if (runStateAtLeast(c, targetState) ||
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))))
break;
}
}
/**
* 如果(SHUTDOWN状态且线程池和工作队列为空)或(STOP状态且线程池为空),则转换为TERMINATED状态
* 如果有资格终止,但workerCount(工作线程数)不为零,则中断空闲的工作进程以确保关闭信号传播
* 必须在可能导致终止的任何操作之后调用此方法
* (减少工作进程计数或在关机期间从队列中删除任务)
* 该方法是非私有的,(为了)允许在ScheduledThreadPoolExecutor进行访问
*/
final void tryTerminate() {
for (;;) {
// 获取线程池当前状态
int c = ctl.get();
// 如果线程正在运行(未关闭)
// 或者不是TIDYING(终止前整理状态)
// 或者不是STOP状态且工作队列不为空(仍有线程在工作)
// 直接返回
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateLessThan(c, STOP) && ! workQueue.isEmpty()))
return;
// 需要有资格终止
if (workerCountOf(c) != 0) { // Eligible to terminate
// 仅仅停止闲置线程
interruptIdleWorkers(ONLY_ONE);
return;
}
// 获取当前整个线程池的锁
final ReentrantLock mainLock = this.mainLock;
// 锁定
mainLock.lock();
try {
// CAS设置状态为TIDYING(即完全停止前整理状态)
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
// 停止
terminated();
} finally {
// 从TIDYING转为TERMINATED状态
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
// 释放锁
mainLock.unlock();
}
// else retry on failed CAS
}
}
/*
* 用于控制对工作线程的中断的方法
*/
/**
* 如果有安全管理器,请确保调用方具有关闭线程的权限(请参阅shutdownPerm)
* 如果权限测试通过了,另外还要确保允许调用方中断每个工作线程
* 即使第一次检查通过,如果SecurityManager特别处理一些线程,这也最终无法通过
*/
private void checkShutdownAccess() {
// assert mainLock.isHeldByCurrentThread();
SecurityManager security = System.getSecurityManager();
// 存在安全管理器
if (security != null) {
// 测试权限
security.checkPermission(shutdownPerm);
// 测试线程获取权限(确保允许调用方中断每个工作线程)
for (Worker w : workers)
security.checkAccess(w.thread);
}
}
/**
* 中断所有线程,即使处于活动状态
* 忽略SecurityExceptions(在这种情况下,某些线程可能保持未被中断![因为内部捕获了InterrupedExeception?])
*/
private void interruptWorkers() {
// assert mainLock.isHeldByCurrentThread();
for (Worker w : workers)
w.interruptIfStarted();
}
/**
* 中断可能正在等待任务(闲置)的线程
* 以便它们可以检查终止或配置更改
* 忽略SecurityExceptions(在这种情况下,某些线程可能保持未被中断
*
* @param onlyOne 如果是true,则最多打断一个工人
* 只有在调用tryTerminate方法但仍有其他工作进程时,才会从tryTerminate调用此函数;
* 在这种情况下,如果所有线程当前都在等待,则最多会中断一个等待的工作进程来传播关闭信号
* 中断任意线程可确保自关机开始以来新到达的工作线程最终也将退出
* 为了保证最终的终止,总是只中断一个空闲的工作线程就足够了;
* 但是shutdown()方法会中断所有空闲的工作线程,以便冗余的工作线程能够迅速退出,而不是等待一个散乱的任务完成
*/
private void interruptIdleWorkers(boolean onlyOne) {
// 获取主线程, 并加锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
// 获取工作线程
Thread t = w.thread;
// 如果工作线程未被中断, 且获取当前工作线程锁成功
if (!t.isInterrupted() && w.tryLock()) {
try {
// 中断线程
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
// 如果只中断一个线程, 则直接退出
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
/**
* 常见形式的interruptedleworkers,以避免记住布尔参数的含义
*/
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
// 默认在停止时只中断一个线程
private static final boolean ONLY_ONE = true;
/*
* 其他实用程序,其中大部分也被ScheduledThreadPoolExecutor继承
*/
/**
* 为给定的命令调用被拒绝时执行的处理程序
* 为ScheduledThreadPoolExecutor使用而使用默认可见性(包可见)
*/
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
/**
* 在调用shutdown时执行运行状态转换之后的任何进一步清理
* 这里是no操作,但在ScheduledThreadPoolExecutor中用于取消延迟的任务
*/
void onShutdown() {
}
/**
* 将任务队列排入新列表,通常使用drainTo
* 但是,如果队列是DelayQueue或任何其他类型的队列,
* 而poll或drainTo可能无法取出某些元素,则它会逐个加入并删除!
*/
private List<Runnable> drainQueue() {
// 取出工作队列
BlockingQueue<Runnable> q = workQueue;
// 待返回的任务队列
ArrayList<Runnable> taskList = new ArrayList<>();
// 使用阻塞队列的drainTo方法
q.drainTo(taskList);
// 无法取出某些元素,则逐个删除
if (!q.isEmpty()) {
for (Runnable r : q.toArray(new Runnable[0])) {
if (q.remove(r))
taskList.add(r);
}
}
return taskList;
}
/*
* 创建、运行和清理方法
*/
/**
* 检查是否可以根据当前池状态和给定的参数(核心或最大值)添加新的工作进程
* 如果可以添加,则相应地调整工作进程计数;
* 如果调整工作进程计数成功,则创建并启动一个新的工作进程,将firsttask参数作为其第一个任务
* 如果池已停止或符合关闭条件,则此方法返回false
* 如果线程工厂在未能创建线程,它也会返回false
* 如果线程创建失败,或者是由于线程工厂返回null,或者是由于异常(通常是thread.start()中的OutOfMemoryError),我们将干净地回滚
*
* @param firstTask 新线程应该首先运行的任务(如果没有,则为空)
* 创建工作线程时,首先要创建一个初始任务(在execute()方法中),以便在少于corePoolSize线程时绕过队列
* (在这种情况下,我们总是启动一个线程)
* 或者在队列已满(在这种情况下,我们必须绕过队列)
* 在初始化时, 空闲线程通常是通过prestartCoreThread创建的,或者用来替换其他正在死亡的工作线程
*
* @param core 如果为true,则使用corePoolSize作为绑定,否则使用maximumPoolSize
* (此处使用布尔指示符而不是值,以确保在检查其他线程池状态后读取新值)
* @return true if successful
*/
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (int c = ctl.get();;) {
// 仅在必要时检查队列是否为空
// 如果线程池状态为SHUTDOWN
// 且如果线程池状态为STOP, 或者任务不为空或者工作队列为空
// 此时不增加
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP)
|| firstTask != null
|| workQueue.isEmpty()))
return false;
for (;;) {
// 当前工作核心数大于声明要求(此时无法添加)
if (workerCountOf(c)
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
return false;
// 否则如果CAS创建工作线程成功, 直接break;
if (compareAndIncrementWorkerCount(c))
break retry;
// 否则CAS创建线程失败, 重新获取当前线程池状态
c = ctl.get(); // Re-read ctl
// 如果状态为SHUTDOWN, 则重新循环
// (注意, 下次的状态"可能"为SHUTDOWN)
if (runStateAtLeast(c, SHUTDOWN))
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 创建新的工人, 并传入任务firstTask
w = new Worker(firstTask);
// 获取Worker内部定义的线程(此时线程已经被ThreadFactory初始化了)
final Thread t = w.thread;
if (t != null) {
// 通过线程池主锁加锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int c = ctl.get();
// 持有锁时重新检查
// 在ThreadFactory失败或获取锁之前线程池被shutdown时退出
if (isRunning(c) ||
(runStateLessThan(c, STOP) && firstTask == null)) {
if (t.isAlive()) // 预检查工作线程t可以被启动(startable)
throw new IllegalThreadStateException();
// 加入工作队列
workers.add(w);
int s = workers.size();
// 更新池大小
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 如果成功添加了worker到工人队列
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// 如果添加失败, 回滚
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
/**
* 回滚工作线程创建
* -从工人队列中移除工人(如果存在)
* -减少工人数量
* -重新检查是否终止,以防该员工的存在导致终止
*/
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 从工人队列中移除工人(如果存在)
if (w != null)
workers.remove(w);
// 减少工人数量
decrementWorkerCount();
// 重新检查是否终止,以防该员工的存在导致终止
tryTerminate();
} finally {
mainLock.unlock();
}
}
/**
* 对待清除的工人进行清理和记录, 仅从工作线程调用
* 除非设置为"completedAbruptly",否则假定workerCount已调整为退出状态
* 此方法将线程从工作集合set中移除;
* 如果工作集合set由于用户任务异常而退出,
* 或者如果运行的工作集少于corePoolSize,
* 或者队列为非空但工作集合set为空, 则可能终止池或替换工人(worker)
*
* @param w the worker
* @param completedAbruptly 如果允许工作进程由于用户异常而死亡
*/
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // completedAbruptly,则未调整workerCount
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 更新已经完成的任务数记录
// 并移除工人
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
int c = ctl.get();
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
/**
* 根据当前配置, 获取任务(可能会造成阻塞或定时等待);
* 如果此工作进程由于以下原因必须退出,则返回null:
* 1.有多于maximumPoolSize个工作线程(由于调用了setMaximumPoolSize)
* 2.线程池已停止;
* 3.线程池已关闭,队列为空;
* 4.这个工人在等待任务时超时,并且超时的工作线程在超时等待之前和之后都将被终止
* (即allowCoreThreadTimeOut | | workerCount>corePoolSize)
* [如果队列非空,则此工作线程不是线程池中的最后一个线程]
*
* @return 任务, 或者如果工人将要退出(停止),则为空(在这种情况下,将递减workerCount)
*/
private Runnable getTask() {
boolean timedOut = false; // 上次poll()超时了吗?
for (;;) {
int c = ctl.get();
// Check if queue empty only if necessary.
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP) || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// 工人会被淘汰吗?
// 通过判断允许核心工人超期或工人数超过核心工人数
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 如果:
// 1.有多于maximumPoolSize个工作线程(由于调用了setMaximumPoolSize)
// 2.线程池已停止;
// 3.线程池已关闭,队列为空;
// 4.这个工人在等待任务时超时,并且超时的工作线程在超时等待之前和之后都将被终止
// 返回null
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 根据任务类型获取任务
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
/**
* 工人进程运行主loop
* 从队列中重复获取任务并执行它们,同时处理许多问题:
*
* 1.我们可以从一个初始任务开始,在这种情况下,我们不需要得到(队列中的)第一个任务;
* 否则,只要线程池正在运行,我们就从getTask方法获取任务;
* 如果getTask方法返回null,则工作进程将由于线程池状态或配置的更改而退出;
* 其他的退出是由外部代码中的异常引发的,在这种情况下completedAbruptly会保持, 这通常会导致processWorkerExit替换此线程
*
* 2.在运行任何任务之前,获取锁是为了防止任务执行时其他线程池中断;
* 然后我们确保除非池停止,否则此线程没有被设置中断
*
* 3.每个任务运行之前都会调用beforexecute方法,这可能会引发异常;
* 在这种情况下,我们会使线程在不处理任务的情况下死亡
* (以completedAbruptly=true中断循环)
*
* 4.假设beforexecute正常完成,我们运行该任务,收集其抛出的任何异常以发送到afterExecute方法
* 我们分别处理RuntimeException, Error(这两个规范都保证我们捕获)和任意Throwables
* 因为我们不能在Runnable.run中重新抛出Throwables,所以在退出时将它们包装在Errors中
* (工作线程的UncaughtExceptionHandler)
* 任何抛出的异常也会保守地导致线程死亡
*
* 5.在task.run方法完成后,我们调用afterExecute, 这也可能引发异常,这也会导致线程死亡
* 根据JLS Sec 14.20,即使task.run抛出异常,这个影响(导致线程死亡)也是有效的
*
* 异常机制的结果是:
* afterExecute和线程的UncaughtExceptionHandler使我们可以提供
* 关于用户代码遇到的任何问题的准确信息
*
* @param w the worker
*/
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
// 取出任务
Runnable task = w.firstTask;
w.firstTask = null;
// 允许工作线程被中断
w.unlock();
boolean completedAbruptly = true;
try {
// firstTask为空时, 通过getTask方法获取任务
while (task != null || (task = getTask()) != null) {
// 工人加锁, 防止外部修改状态
w.lock();
// 如果池正在停止,确保线程被中断;
// 如果没有,请确保线程没有中断
// 在第二种情况下需要重新检查,以在清除中断时处理shutdownNow情况
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 执行beforeExecute
beforeExecute(wt, task);
try {
// 执行任务
task.run();
// 执行afterExecute
afterExecute(task, null);
} catch (Throwable ex) {
// afterExecute处理可能出现的异常
afterExecute(task, ex);
throw ex;
}
} finally {
// 最后:
// 1.任务置为null(帮助GC)
// 2.任务完成数+1
// 3.任务解锁线程
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
// pubilc 构造方法和方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
/**
* 使用给定的初始参数创建新的ThreadPoolExecutor
*
* @param corePoolSize 要保留在池中的线程数,即使它们处于空闲状态
* (除非设置了 allowCoreThreadTimeOut)
*
* @param maximumPoolSize 线程池中允许的最大线程数
* @param keepAliveTime 当线程数大于核心时,这是多余空闲线程在终止前等待新任务的最长时间
* @param unit 时间单位
* @param workQueue 在执行任务之前用于保存任务的队列
* (此队列将仅包含由execute方法提交的Runnable任务
* @param threadFactory 执行器创建新线程时使用的工厂
* @param handler 由于达到线程边界和队列容量而阻止执行时要使用的处理程序(拒绝策略)
* @throws IllegalArgumentException 如果下列条件之一成立:
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException 如果workQueue或threadFactory或handler为空
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
/**
* 在将来的某个时候执行给定的任务, 任务可以在新线程或现有池线程中执行
*
* 如果由于该执行器已关闭或已达到其容量而无法提交任务以供执行,
* 则由当前的RejectedExecutionHandler处理该任务
*
* @param command the task to execute
* @throws RejectedExecutionException at discretion of
* {@code RejectedExecutionHandler}, if the task
* cannot be accepted for execution
* @throws NullPointerException if {@code command} is null
*/
public void execute(Runnable command) {
// 如果任务为null, 直接报NullPointerException异常
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1.如果运行的线程少于corePoolSize,尝试以给定的命令作为第一个任务启动新线程执行
* 对addWorker的调用以原子方式检查runState和workerCount,
* 因此可以通过返回false来防止在不应该添加线程时出现的错误警报
*
* 2.如果任务可以成功排队,那么我们仍然需要再次检查是否应该添加线程
* (因为自上次检查以来可能已有线程死亡)
* 或者池是否在进入此方法后关闭!
* 因此,我们重新检查状态:
* 如果停止,则回滚排队; 如果没有,则启动新线程
*
* 3. 如果无法将任务排队,则尝试添加新线程;
* 如果失败了,则说明线程池正在被关闭或线程池饱和,所以拒绝任务;
*/
// 获取状态
int c = ctl.get();
// 如果现有工作线程数小于corePoolSize
if (workerCountOf(c) < corePoolSizecorePoolSize) {
// 则通过新加入一个worker来执行新任务(此时任务在新线程执行)
if (addWorker(command, true))
return;
// 无法获取新工人, 更新线程池状态
c = ctl.get();
}
// 如果线程池在运行, 且加入任务成功
if (isRunning(c) && workQueue.offer(command)) {
// 更新线程池状态
int recheck = ctl.get();
// 如果线程池没在运行, 且删除任务成功
if (! isRunning(recheck) && remove(command))
// 拒绝
reject(command);
// 如果线程池状态中工人变为0个
else if (workerCountOf(recheck) == 0)
// 添加工人
addWorker(null, false);
}
// 否则, 线程池未在运行或任务未成功加入
// 通过新加入一个worker来执行新任务(此时任务在新线程执行)
else if (!addWorker(command, false))
// 加入工人失败, 拒绝
reject(command);
}
/**
* 启动有序关闭,在该关闭前执行以前提交的任务,但不接受新任务
* 如果已关闭,则调用没有效果
*
* 此方法不会永久等待以前提交的任务完成执行, (使用awaitTermination执行此操作)
*
* @throws SecurityException {@inheritDoc}
*/
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 检查停止权限
checkShutdownAccess();
// 更新状态
advanceRunState(SHUTDOWN);
// 停止闲置worker
interruptIdleWorkers();
// hook for ScheduledThreadPoolExecutor
onShutdown();
} finally {
mainLock.unlock();
}
tryTerminate();
}
/**
* 尝试停止所有正在执行的任务,停止处理等待中的任务,并返回等待执行的任务列表;
* 从该方法返回时,这些任务将从任务队列中移除
*
* 此方法不会永久等待以前提交的任务完成执行, (使用awaitTermination方法执行此操作)
*
* 除了尽最大努力尝试停止处理正在积极执行的任务之外,没有任何保证;
* 此实现通过Thread.interrupt方法中断任务;
* 任何未能响应中断的任务都可能永远不会终止!
*
* @throws SecurityException {@inheritDoc}
*/
public List<Runnable> shutdownNow() {
// 停止的任务列表
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 检查停止权限
checkShutdownAccess();
// 更新状态为STOP
advanceRunState(STOP);
// (尽最大努力尝试)停止正在执行中的任务!
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
// 线程池是否停止
public boolean isShutdown() {
return runStateAtLeast(ctl.get(), SHUTDOWN);
}
/** Used by ScheduledThreadPoolExecutor. */
boolean isStopped() {
return runStateAtLeast(ctl.get(), STOP);
}
/**
* 如果此执行器正在执行shutdown或shutdownNow,但尚未完全终止,则返回true
* (此方法可能对调试有用)
* 如果返回true经过了一定的时间段,则可能表示提交的任务已忽略或抑制中断,从而导致此执行器无法正确终止
*
* @return {@code true} if terminating but not yet terminated
*/
public boolean isTerminating() {
int c = ctl.get();
return runStateAtLeast(c, SHUTDOWN) && runStateLessThan(c, TERMINATED);
}
// 线程池已经终止
public boolean isTerminated() {
return runStateAtLeast(ctl.get(), TERMINATED);
}
// 线程池停止时(等待任务结束)
public boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 还未完全停止时, 等待
while (runStateLessThan(ctl.get(), TERMINATED)) {
// 时间到未停止, 返回false
if (nanos <= 0L)
return false;
nanos = termination.awaitNanos(nanos);
}
// 时间到之前停止
return true;
} finally {
mainLock.unlock();
}
}
// 不使用Throwable重写以与子类兼容
// 其finalize方法调用super.finalize方法(如建议的那样)
// 在JDK11之前,finalize()有一个非空的方法体
/**
* @implNote 这个类以前的版本有一个finalize方法关闭这个执行器
* 但是在这个版本中,finalize什么也不做
*/
@Deprecated(since="9")
protected void finalize() {}
/**
* 设置用于创建新线程的线程工厂
*
* @param threadFactory the new thread factory
* @throws NullPointerException if threadFactory is null
* @see #getThreadFactory
*/
public void setThreadFactory(ThreadFactory threadFactory) {
if (threadFactory == null)
throw new NullPointerException();
this.threadFactory = threadFactory;
}
/**
* Returns the thread factory used to create new threads.
*
* @return the current thread factory
* @see #setThreadFactory(ThreadFactory)
*/
public ThreadFactory getThreadFactory() {
return threadFactory;
}
/**
* 为不可执行的任务设置新的处理程序(拒绝策略)
*
* @param handler the new handler
* @throws NullPointerException if handler is null
* @see #getRejectedExecutionHandler
*/
public void setRejectedExecutionHandler(RejectedExecutionHandler handler) {
if (handler == null)
throw new NullPointerException();
this.handler = handler;
}
/**
* Returns the current handler for unexecutable tasks.
*
* @return the current handler
* @see #setRejectedExecutionHandler(RejectedExecutionHandler)
*/
public RejectedExecutionHandler getRejectedExecutionHandler() {
return handler;
}
/**
* 设置线程池的核心数, 这将重写构造函数中设置的值
* 如果新值小于当前值,则多余的现有线程将在下次变为空闲时而终止
* 如果更大,如果有新任务需要,将启动新线程来执行任何排队的任务
*
* @param corePoolSize the new core size
* @throws IllegalArgumentException if {@code corePoolSize < 0}
* or {@code corePoolSize} is greater than the {@linkplain
* #getMaximumPoolSize() maximum pool size}
* @see #getCorePoolSize
*/
public void setCorePoolSize(int corePoolSize) {
// 如果corePoolSize<0或者corePoolSize大于线程池最大值
if (corePoolSize < 0 || maximumPoolSize < corePoolSize)
throw new IllegalArgumentException();
// 增量delta
int delta = corePoolSize - this.corePoolSize;
// 更新corePoolSize
this.corePoolSize = corePoolSize;
// 现有的工人数大于corePoolSize(即数量减少)
if (workerCountOf(ctl.get()) > corePoolSize)
interruptIdleWorkers();
// 现有的工人数小于corePoolSize(数量要增加)
else if (delta > 0) {
// 我们真的不知道“需要”多少个新线程
// 作为一种启发式方法,预先启动足够多的新工作线程(最多新的核心大小)
// 来处理队列中当前数量的任务,但在执行此操作时,如果队列变为空,则停止
int k = Math.min(delta, workQueue.size());
while (k-- > 0 && addWorker(null, true)) {
if (workQueue.isEmpty())
break;
}
}
}
/**
* 返回线程池的核心数
*
* @return the core number of threads
* @see #setCorePoolSize
*/
public int getCorePoolSize() {
return corePoolSize;
}
/**
* 提前启动"一个"核心线程,让它空闲地等待工作
* 这将覆盖仅在执行新任务时启动核心线程的默认策略
* 如果所有核心线程都已启动,则此方法将返回false
*
* @return {@code true} if a thread was started
*/
public boolean prestartCoreThread() {
return workerCountOf(ctl.get()) < corePoolSize &&
addWorker(null, true);
}
/**
* 与prestartCoreThread相同,不同之处在于:
* 即使corePoolSize为0, 也会安排至少启动"一个线程"!
*/
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
/**
* 提前启动所有核心线程,让它们空闲地等待工作
* 这将覆盖仅在执行新任务时启动核心线程的默认策略
*
* @return the number of threads started
*/
public int prestartAllCoreThreads() {
int n = 0;
while (addWorker(null, true))
++n;
return n;
}
/**
* 如果此池允许核心线程超时,则返回true;
* 如果在keepAlive时间内没有任务到达,线程terminate;
* 如果需要,则在新任务到达时替换;
* 如果为true,则应用于非核心线程的相同保持活动策略也适用于核心线程
* 如果为false(默认值),则不会由于缺少传入任务而终止核心线程
*
* @return {@code true} if core threads are allowed to time out,
* else {@code false}
*
* @since 1.6
*/
public boolean allowsCoreThreadTimeOut() {
return allowCoreThreadTimeOut;
}
/**
* 设置控制"核心线程"是否可以超时的策略
* 如果在保持活动时间内没有任务到达,则该策略将在新任务到达时根据需要被替换
* 如果为false,则不会由于缺少传入任务而终止核心线程;
* 如果为true,则应用于非核心线程的相同保持活动策略也适用于核心线程;
* 为了避免连续的线程替换,在设置true时keepAliveTime必须大于零
* 通常应该在"线程池被激活之前调用此方法"
*
* @param value {@code true} if should time out, else {@code false}
* @throws IllegalArgumentException if value is {@code true}
* and the current keep-alive time is not greater than zero
*
* @since 1.6
*/
public void allowCoreThreadTimeOut(boolean value) {
// 超时时间应当大于零
if (value && keepAliveTime <= 0)
throw new IllegalArgumentException("Core threads must have nonzero keep alive times");
// 更新超时状态标志
if (value != allowCoreThreadTimeOut) {
allowCoreThreadTimeOut = value;
if (value)
interruptIdleWorkers();
}
}
/**
* 设置允许的最大线程数, 这将重写构造函数中设置的值
* 如果新值小于当前值,则多余的现有线程将在下次变为空闲时终止
*
* @param maximumPoolSize the new maximum
* @throws IllegalArgumentException if the new maximum is
* less than or equal to zero, or
* less than the {@linkplain #getCorePoolSize core pool size}
* @see #getMaximumPoolSize
*/
public void setMaximumPoolSize(int maximumPoolSize) {
if (maximumPoolSize <= 0 || maximumPoolSize < corePoolSize)
throw new IllegalArgumentException();
this.maximumPoolSize = maximumPoolSize;
// 如果新值小于当前值,则检测一次空闲线程
if (workerCountOf(ctl.get()) > maximumPoolSize)
interruptIdleWorkers();
}
/**
* Returns the maximum allowed number of threads.
*
* @return the maximum allowed number of threads
* @see #setMaximumPoolSize
*/
public int getMaximumPoolSize() {
return maximumPoolSize;
}
/**
* 设置线程keepAliveTime,即线程在终止之前可以保持空闲的时间量
* 如果池中当前的线程数超过核心线程数;
* 或者如果此池allowsCoreThreadTimeOut允许核心线程超时,
* 则到此时间而空闲的线程将被终止
* 这将重写构造函数中设置的值
*
* @param time 时间值为零将导致"多余的线程"在执行任务后"立即终止"
* 允许allowsCoreThreadTimeOut时, 不可设置为0
* @param unit the time unit of the {@code time} argument
* @throws IllegalArgumentException if {@code time} less than zero or
* if {@code time} is zero and {@code allowsCoreThreadTimeOut}
* @see #getKeepAliveTime(TimeUnit)
*/
public void setKeepAliveTime(long time, TimeUnit unit) {
if (time < 0)
throw new IllegalArgumentException();
// 允许allowsCoreThreadTimeOut时, 不可设置为0
if (time == 0 && allowsCoreThreadTimeOut())
throw new IllegalArgumentException("Core threads must have nonzero keep alive times");
// 设置时间
long keepAliveTime = unit.toNanos(time);
long delta = keepAliveTime - this.keepAliveTime;
this.keepAliveTime = keepAliveTime;
// 如果等待时间减少, 清除一次空闲线程
if (delta < 0)
interruptIdleWorkers();
}
/**
* 返回线程保持活动时间,即线程在终止之前可能保持空闲的时间量
*
* @param unit the desired time unit of the result
* @return the time limit
* @see #setKeepAliveTime(long, TimeUnit)
*/
public long getKeepAliveTime(TimeUnit unit) {
return unit.convert(keepAliveTime, TimeUnit.NANOSECONDS);
}
/* 面向用户的队列实用方法 */
/**
* 返回此执行器使用的任务队列, 对任务队列的访问主要用于调试和监视
* 此队列可能正在使用中, 遍历任务队列"不会阻止排队的任务执行"
*
* @return the task queue
*/
public BlockingQueue<Runnable> getQueue() {
return workQueue;
}
/**
* 从执行器的内部队列中移除此任务(如果存在),从而导致它在尚未启动时不再运行
*
* 此方法可作为取消任务的一一种方法使用
* 但它可能无法删除在放入内部队列之前已转换为其他形式的任务:
* 例如,使用submit输入的任务可能会转换为维护Future状态的表单
* 但是,在这种情况下,可以使用purge方法删除那些已被取消的Future对象
*
* @param task the task to remove
* @return {@code true} if the task was removed
*/
public boolean remove(Runnable task) {
boolean removed = workQueue.remove(task);
tryTerminate(); // 在SHUTDOWN状态并且队列为空(保证SHUTDOWN)
return removed;
}
/**
* 尝试从工作队列中删除所有已取消的Future任务
* (此方法可以用作对其他方法没有其他影响的一种存储回收操作)
* [取消的任务永远不会执行,但可能会累积在工作队列中,直到工作线程可以主动删除它们]
* 相反,调用此方法会尝试"立即删除"它们
* 但是,在其他线程的干扰下,此方法可能无法删除任务
*/
public void purge() {
final BlockingQueue<Runnable> q = workQueue;
try {
Iterator<Runnable> it = q.iterator();
while (it.hasNext()) {
Runnable r = it.next();
// 如果任务是Future类型, 并且已经被撤销, 则清除任务
if (r instanceof Future<?> && ((Future<?>)r).isCancelled())
it.remove();
}
} catch (ConcurrentModificationException fallThrough) {
// 如果在遍历过程中遇到干扰,选择慢遍历方法
// 为遍历创建array副本,并为取消的条目调用remove
// 慢遍历的时间复杂度更可能是O(N*N)
for (Object r : q.toArray())
if (r instanceof Future<?> && ((Future<?>)r).isCancelled())
q.remove(r);
}
tryTerminate(); // In case SHUTDOWN and now empty
}
/* 线程池数据统计 */
/**
* 返回池中当前工作线程数
*
* @return the number of threads
*/
public int getPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 排除isTerminated返回true并且getPoolSize()>0的情况
return runStateAtLeast(ctl.get(), TIDYING) ? 0
: workers.size();
} finally {
mainLock.unlock();
}
}
/**
* 返回正在积极执行任务的线程的大概数量(根据worker被锁来判断)
*
* @return the number of threads
*/
public int getActiveCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int n = 0;
for (Worker w : workers)
// 根据worker被锁来判断
if (w.isLocked())
++n;
return n;
} finally {
mainLock.unlock();
}
}
/**
* 返回池中同时存在的最大线程数
*
* @return the number of threads
*/
public int getLargestPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
return largestPoolSize;
} finally {
mainLock.unlock();
}
}
/**
* 返回计划执行和已执行的任务的大致总数
* 由于任务和线程的状态在计算期间可能会动态变化,因此返回的值只是一个近似值
*
* @return the number of tasks
*/
public long getTaskCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 当前统计完成的任务数
long n = completedTaskCount;
// 遍历的原因是只有worker被清除时才将他的数据加入completedTaskCount属性中;
for (Worker w : workers) {
// 与当前工作线程的任务数相加
n += w.completedTasks;
// 如果当前线程被锁, 则再加一
if (w.isLocked())
++n;
}
// 最后加上任务队列长度(计划执行任务数)
return n + workQueue.size();
} finally {
mainLock.unlock();
}
}
/**
* 返回已完成执行的任务的大致总数
* 由于任务和线程的状态在计算过程中可能会动态变化,因此返回的值只是一个近似值
* 但在连续的调用中此值一定不会减少
*
* @return the number of tasks
*/
public long getCompletedTaskCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
long n = completedTaskCount;
for (Worker w : workers)
n += w.completedTasks;
return n;
} finally {
mainLock.unlock();
}
}
/**
* Returns a string identifying this pool, as well as its state,
* including indications of run state and estimated worker and
* task counts.
*
* @return a string identifying this pool, as well as its state
*/
public String toString() {
long ncompleted;
int nworkers, nactive;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
ncompleted = completedTaskCount;
nactive = 0;
nworkers = workers.size();
for (Worker w : workers) {
ncompleted += w.completedTasks;
if (w.isLocked())
++nactive;
}
} finally {
mainLock.unlock();
}
int c = ctl.get();
String runState =
isRunning(c) ? "Running" :
runStateAtLeast(c, TERMINATED) ? "Terminated" :
"Shutting down";
return super.toString() +
"[" + runState +
", pool size = " + nworkers +
", active threads = " + nactive +
", queued tasks = " + workQueue.size() +
", completed tasks = " + ncompleted +
"]";
}
/* 扩展的钩子方法 */
/**
* 在给定线程中执行给定Runnable之前调用的方法
* 此方法由执行任务r的线程t调用,可用于重新初始化线程局部变量或执行日志记录
*
* 这个实现什么也不做,但是可以"在子类中定制"
* 注意:为了正确地嵌套多个重写,子类通常应该在这个"方法的末尾"调用super.beforeExecute
*
* @param t the thread that will run task {@code r}
* @param r the task that will be executed
*/
protected void beforeExecute(Thread t, Runnable r) { }
/**
* 在执行完给定的可运行程序后调用的方法, 此方法由执行任务的线程调用
* 如果异常非空,则抛出的是导致执行线程突然终止的未捕获的RuntimeException或Error
*
* 这个实现什么也不做,但是可以在子类中定制
* 注意: 为了正确地嵌套多个重写, 子类通常应该在"这个方法的开头"调用super.afterExecute
*
* 注意: 当操作显式地或通过方法(如submit)包含在任务(如FutureTask)中时:
* 由这些任务对象捕获并维护计算异常,因此它们不会导致突然终止,并且内部异常不会传递给此方法;
*
* 如果你希望在此方法中捕获这两种类型的异常,则可以参考下面这个例子;
*
* 在此示例子类中,如果任务已中止,则打印直接原因或基础异常:
*
* <pre> {@code
* class ExtendedExecutor extends ThreadPoolExecutor {
* // ...
* protected void afterExecute(Runnable r, Throwable t) {
* super.afterExecute(r, t);
* if (t == null
* && r instanceof Future<?>
* && ((Future<?>)r).isDone()) {
* try {
* Object result = ((Future<?>) r).get();
* } catch (CancellationException ce) {
* t = ce;
* } catch (ExecutionException ee) {
* t = ee.getCause();
* } catch (InterruptedException ie) {
* // ignore/reset
* Thread.currentThread().interrupt();
* }
* }
* if (t != null)
* System.out.println(t);
* }
* }}</pre>
*
* @param r the runnable that has completed
* @param t the exception that caused termination, or null if
* execution completed normally
*/
protected void afterExecute(Runnable r, Throwable t) { }
/**
* 执行器终止时调用的方法, 默认实现什么也不做
* 注意: 为了正确地嵌套多个重写, 子类通常应该在这个方法中调用super.terminated
*/
protected void terminated() { }
/* 预定义的RejectedExecutionHandlers(拒绝策略) */
/**
* 拒绝策略: CallerRunsPolicy
* 它直接在execute方法的调用线程(提交任务的线程)中运行被拒绝的任务;
* 除非执行程序已关闭,在这种情况下,该任务将被丢弃
*/
public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() { }
/**
* 在调用方线程中执行任务r,除非已关闭执行器,在这种情况下,将丢弃该任务
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
/**
* 拒绝策略: AbortPolicy(默认)
* 直接抛出RejectedExecutionException
*
* 这是ThreadPoolExecutor和ScheduledThreadPoolExecutor的默认处理程序
*/
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
/**
* 拒绝策略: DiscardPolicy
* 自动放弃被拒绝的任务
*/
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* 不执行任何操作,直接丢弃任务r
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
/**
* 拒绝策略: DiscardOldestPolicy
* 丢弃最旧的未处理请求,然后重试execute,除非该执行程序关闭,否则该任务将被丢弃
*/
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardOldestPolicy} for the given executor.
*/
public DiscardOldestPolicy() { }
/**
* 获取并忽略执行器将要执行的下一个任务(如果该任务立即可用)
* 然后重试执行任务r,除非执行器关闭,否则将放弃任务r
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
}呼呼~ 终于翻译完了2100多行的程序, 下面来做一下总结吧!
一.ctl属性
在ThreadLocalExecutor源码中第一个属性便是一个AtomicInteger类型的ctl, 用来描述线程池的状态(pool control state)
与ctl的相关代码如下:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
// runState存储在高阶位中
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 打包和解包ctl(线程池生命周期属性)
private static int runStateOf(int c) { return c & ~COUNT_MASK; }
private static int workerCountOf(int c) { return c & COUNT_MASK; }
// 参数rs表示runState
// 参数wc表示workerCount
// 即根据runState和workerCount打包合并成ctl
private static int ctlOf(int rs, int wc) { return rs | wc; }
// 不需要解包ctl的位字段访问器
// 这取决于bit的layout和workerCount永不为负
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
private static boolean isRunning(int c) {
return c < SHUTDOWN;
}下面是注释中对ctl的描述:
主池控制状态ctl属性是一个原子整数, 包含两个概念字段:
- workerCount: 有效线程的运行数;
- runState: 指示是否正在运行、正在关闭等;
① workerCount
为了将它们打包成一个int, 我们将workerCount限制为
(2^29)-1[大约5亿]个线程,而不是(2^31)-1[20亿]个线程如果将来出现这种情况(线程数超过5亿):
可以将变量更改为AtomicLong, 并调整下面的shift/mask常量
但是在需要这样改变之前,使用int代码会更快更简单
workerCount是允许启动和不允许停止的工人数
该值可能暂时不同于活动线程的实际数量, 例如:
- 当线程工厂在被请求时无法创建线程
- 当退出的线程在终止前仍在执行记帐(仍然在数量上, 未被减一)时
用户可见池大小为工作集的当前大小
runState提供线程池生命周期控制,具有以下值:
- RUNNING: 接受新任务并处理排队的任务
- SHUTDOWN: 不接受新任务,但处理排队的任务
- STOP: 不接受新任务、不处理排队的任务和中断正在进行的任务
- TIDYING: 所有任务都已终止,workerCount为零, 状态转换为tiding的线程将运行terminated()钩子方法
- TERMINATED: terminated()方法已完成
这些值之间的数字顺序很重要,以便进行有序比较
运行状态随时间单调地增加,但不必命中每个状态, 状态过渡是:
- RUNNING -> SHUTDOWN: 调用shutdown()方法时
- (RUNNING or SHUTDOWN) -> STOP: 在调用shutdownNow()方法时
- SHUTDOWN -> TIDYING: 当队列和池都为空时
- STOP -> TIDYING: 当池为空时
- TIDYING -> TERMINATED: 当terminated()钩子方法完成时
等待awaitTermination()的线程将在状态达到TERMINATED时返回
检测从SHUTDOWN到TIDYING的转换比想象的要简单得多:
因为队列在(正常工作)非空之后可能变空,在SHUTDOWN状态下也可能变空
但我们只在看到它为空之后又看到workerCount为0(有时需要重新检查——见下文)时终止
而针对ctl的操作大部分是位运算, 注释也说了: 把这个int变量拆成两部分来用:
| 前三位 | 后29位 |
|---|---|
| 状态: runState | 当前工作线程数: workerCount |
所以,工作线程数量最大不能超过 2^29-1
所以来看一下ctl定义的状态的数值:
private static final int COUNT_BITS = Integer.SIZE - 3; // 29
private static final int CAPACITY = (1 << COUNT_BITS) - 1; // 000-11111 ... ... 11111111
// 状态在高位存储
private static final int RUNNING = -1 << COUNT_BITS; // 111-00000 ... ... 00000000
private static final int SHUTDOWN = 0 << COUNT_BITS; // 000-00000 ... ... 00000000
private static final int STOP = 1 << COUNT_BITS; // 001-00000 ... ... 00000000
private static final int TIDYING = 2 << COUNT_BITS; // 010-00000 ... ... 00000000
private static final int TERMINATED = 3 << COUNT_BITS; // 011-00000 ... ... 00000000最后看一下与ctl相关的操作方法:
① runStateOf()方法
c & 高3位为1,低29位为0的~COUNT_MASK,用于获取高3位保存的线程池状态;
② workerCountOf()方法
c & 高3位为0,低29位为1的COUNT_MASK,用于获取低29位的线程数量;
③ ctlOf()方法
参数rs表示runState, 参数wc表示workerCount(由于小于2^29-1所以最高位全为0)
即根据runState和workerCount打包合并成ctl
④ 其他状态比较方法
通过上面五种状态的大小可以看出, 状态逐渐递增(因为状态在高三位!)
所以比较状态只需要比较ctl的大小即可!
二.其他属性
① 线程池集合属性
final BlockingQueue<Runnable> workQueue: 用于保存任务并将其传递给工作线程的队列
我们不要求workQueue.poll()返回空值必然意味着workQueue.isEmpty(), 仅依赖于isEmpty来查看队列是否为空
例如: 在决定是否从关闭过渡到整理时,我们必须这样做
这适用于特殊用途的队列,例如DelayQueues的poll()方法允许返回空值,即使稍后在延迟到期时可能返回非空值
final HashSet<Worker> workers: 包含池中所有工作线程的Set集合, 仅在获取mainLock时能够访问
② 线程池锁相关
final ReentrantLock mainLock: 对workers Set和related bookkeeping的访问保持锁定
虽然我们可以使用某种类型的并发集合,但通常最好使用锁, 其中一个原因是:
这会序列化InterruptedWorkers,从而避免不必要的中断风暴(特别是在shutdown期间)
否则,退出的线程将同时中断那些尚未中断的线程
它还简化了一些与最大池大小等相关的统计工作, 在shutdown和shutdownNow执行时,还会获取mainLock,以确保在分别检查允许中断和实际中断的情况下,workers集合是稳定的
final Condition termination: 提供给awaitTermination方法的等待条件
③ 线程池数据相关属性
int largestPoolSize: 跟踪最大的已达到池大小, 仅在获取mainLock时能够访问long completedTaskCount: 已完成任务的计数器, 仅在工作线程终止时更新, 仅在获取mainLock时能够访问volatile long keepAliveTime: 等待工作的空闲线程超时时间(以纳秒为单位)- 当存在超过corePoolSize数量的线程存在或设置了allowCoreThreadTimeOut时使用此超时
- 否则他们会永远等待新的工作
volatile boolean allowCoreThreadTimeOut: 核心工人数闲置收回- 如果为false(默认值), 则核心线程即使处于空闲状态也不会被回收
- 如果为true,则核心线程使用keepAliveTime超时回收
volatile int corePoolSize: corePoolSize是要保持活动状态(并且不允许超时等)的最小工作线程数- 除非设置allowCoreThreadTimeOut(在这种情况下,最小值为零)
- 由于worker count实际上存储在COUNT_BITS中
- 因此真正的限制数是: corePoolSize & COUNT_MASK
volatile int maximumPoolSize: 最大池大小- 由于worker count实际上存储在COUNT_BITS中
- 因此真正的限制数是: maximumPoolSize & COUNT_MASK
说明: 所有用户控制参数都声明为volatile
因此正在进行的操作总是基于最新的值,但不需要锁定
④ 线程池权限相关
static final RuntimePermission shutdownPerm = new RuntimePermission("modifyThread"): 关闭和立即关闭的调用方所需的权限
我们还要求(见checkShutdownAccess方法)调用者有权实际中断(actually interrupt)worker集合中的线程(由Thread.interrupt()控制, ThreadGroup.checkAccess依赖, 而ThreadGroup.checkAccess又依赖于SecurityManager.checkAccess)
只有当这些检查通过时,才会尝试关闭
所有对Thread.interrupt的实际调用(请参阅interruptdleworkers和interruptWorkers)都忽略了SecurityExceptions, 这意味着尝试的中断会自动失败
在关闭的情况下,除非SecurityManager有不一致的策略, (有时允许访问线程,有时不允许)否则它们不应该失败
在这种情况下,未能真正中断线程可能会禁用或延迟完全终止
interruptibleworks的其他用途是建议性的, 而未能真正中断只会延迟对配置更改的响应,因此不会进行异常处理
⑤ 线程工厂
volatile ThreadFactory threadFactory: 所有线程都是使用此工厂(通过addWorker方法)创建
所有调用方都必须为addWorker失败做好准备, 这反映了系统或用户限制线程数的策略
即使不将其视为错误,创建线程失败也可能导致新任务被拒绝或现有任务仍滞留在队列中
我们进一步保留线程池池变量配置,而继续创建Thread, 可能会遇到OutOfMemoryError之类的错误(由于创建线程需要在Thread.start中分配本机堆栈,因此此类错误相当常见)
此时用户将希望执行清理池关闭以进行清理, 如果有足够的内存供清理代码完成,此时则不会遇到另一个OutOfMemory错误
⑥ 拒绝策略相关属性
RejectedExecutionHandler handler: 在执行中线程池饱和或线程池关闭时调用的拒绝策略方法RejectedExecutionHandler defaultHandler = new AbortPolicy(): 默认的拒绝执行处理器(默认为AbortPolicy, 即抛出异常)
更多和属性相关的操作见源码注释~
三.任务提交内部原理
① execute(Runnable command)提交任务
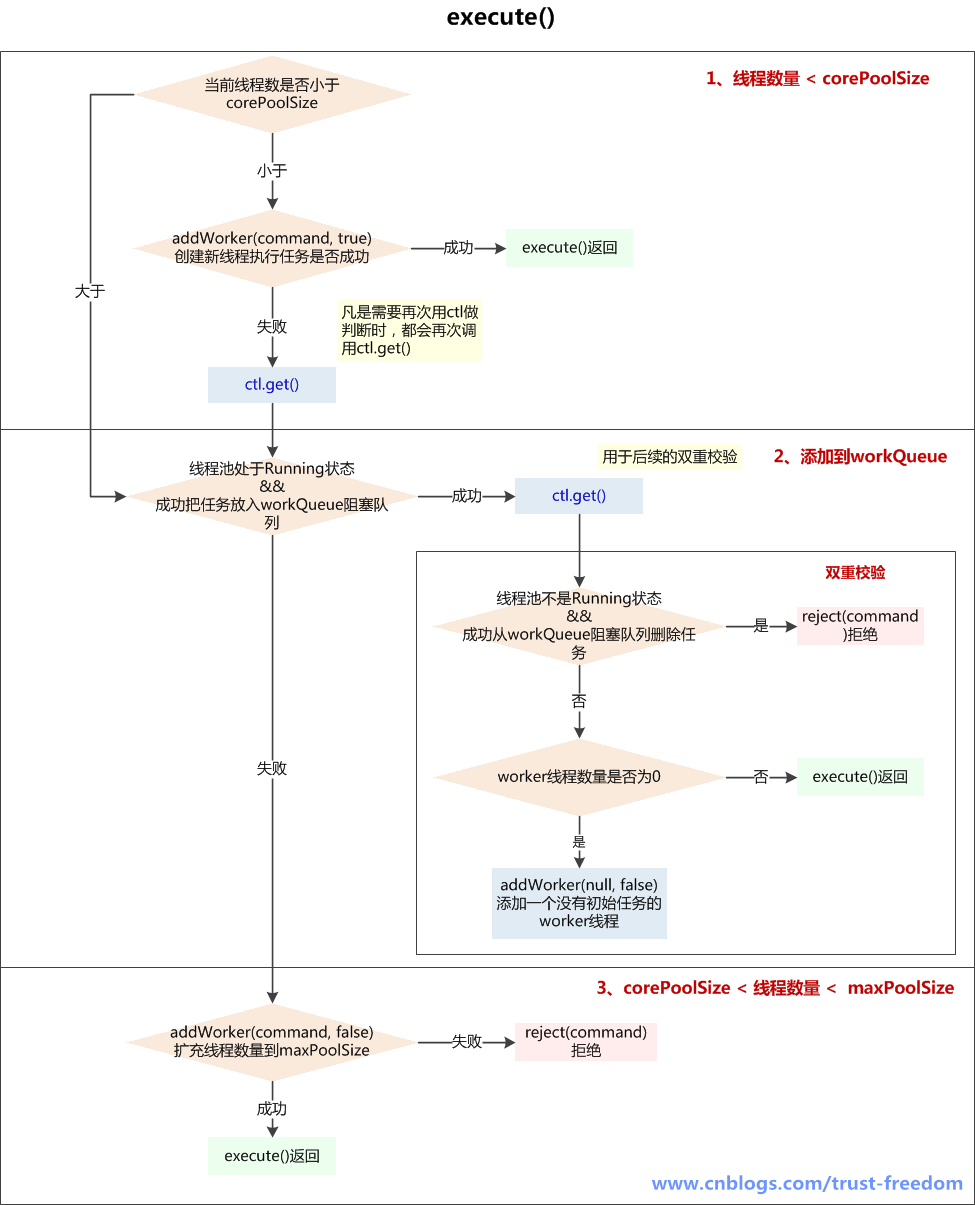
参数: command 提交执行的任务,不能为空
执行流程:
如果线程池当前线程数量少于corePoolSize: 则通过addWorker(command, true)创建新worker线程
- 如创建成功返回;
- 如没创建成功,则执行后续步骤;
addWorker(command, true)失败的原因可能是:
- 线程池已经shutdown,shutdown的线程池不再接收新任务;
- workerCountOf(c) < corePoolSize 判断后,由于并发,别的线程先创建了worker线程,导致workerCount >= corePoolSize
如果线程池还在running状态,将task加入workQueue阻塞队列中
- 如果加入成功,进行double-check;
- 如果加入失败(可能是队列已满),则执行后续步骤;
double-check主要目的是判断刚加入workQueue阻塞队列的task是否能被执行
- 如果线程池已经不是running状态了,应该拒绝添加新任务,从workQueue中删除任务;
- 如果线程池是运行状态,或者从workQueue中删除任务失败(刚好有一个线程执行完毕,并消耗了这个任务),确保还有线程执行任务(只要有一个就够了)
如果线程池不是running状态或者无法入队列,尝试开启新线程,扩容至maxPoolSize,如果addWork(command, false)失败了,拒绝当前command
② addWorker()
添加worker线程流程图如下:
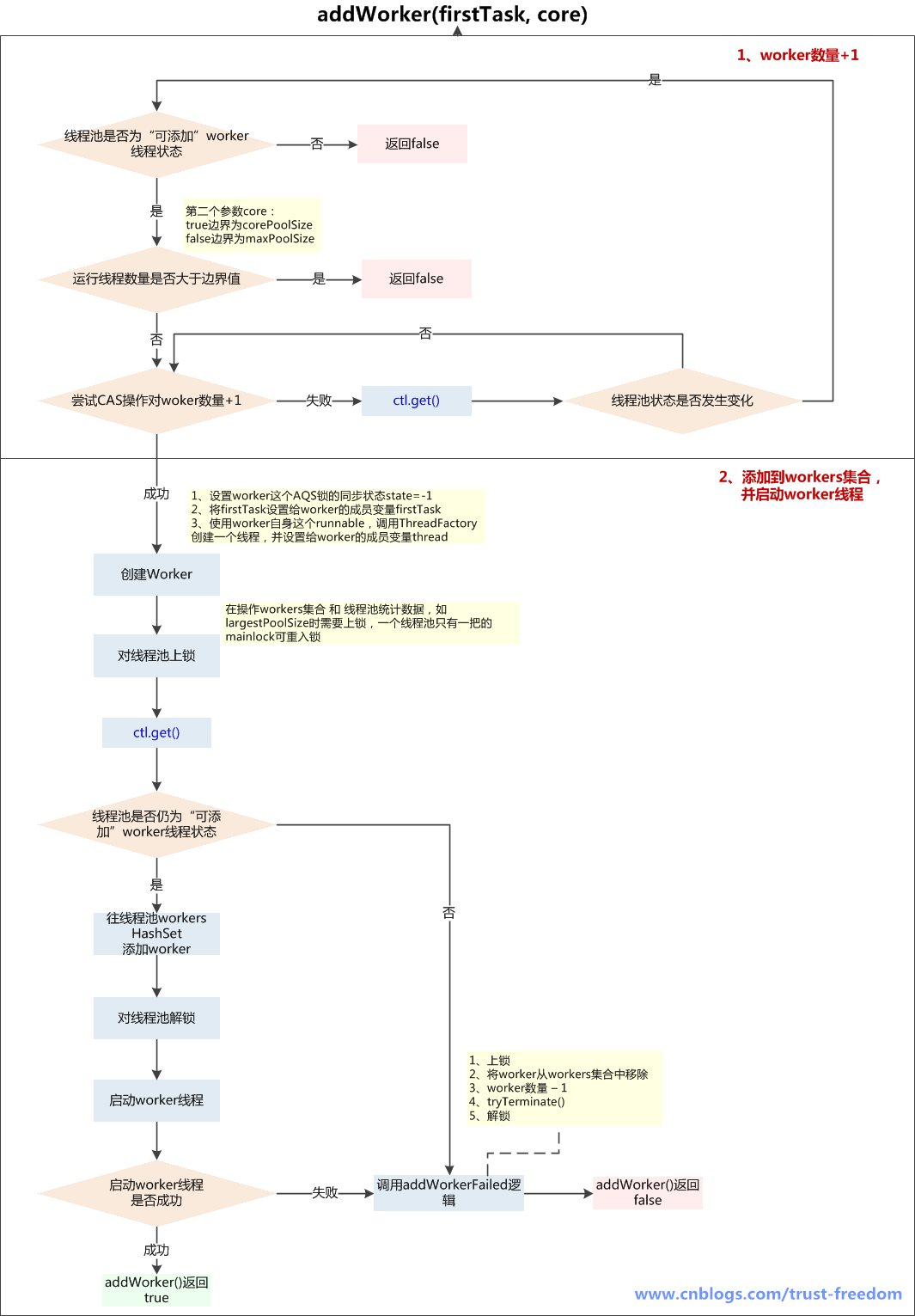
addWorker(Runnable firstTask, boolean core)
参数:
- firstTask: worker线程的初始任务,可以为空
- core:
- true: 将corePoolSize作为上限
- false: 将maximumPoolSize作为上限
addWorker方法有4种传参的方式:
- addWorker(command, true)
- addWorker(command, false)
- addWorker(null, false)
- addWorker(null, true)
在execute方法中就使用了前3种,结合这个核心方法进行以下分析
- 第一个:线程数小于corePoolSize时,放一个需要处理的task进Workers Set; 如果Workers Set长度超过corePoolSize,就返回false
- 第二个:当队列被放满时,就尝试将这个新来的task直接放入Workers Set,而此时Workers Set的长度限制是maximumPoolSize, 如果线程池也满了的话就返回false
- 第三个:放入一个空的task进workers Set,长度限制是maximumPoolSize, 这样一个task为空的worker在线程执行的时候会去任务队列里拿任务,这样就相当于创建了一个新的线程,只是没有马上分配任务
- 第四个:这个方法就是放一个null的task进Workers Set,而且是在小于corePoolSize时,如果此时Set中的数量已经达到corePoolSize那就返回false,什么也不干。实际使用中是在prestartAllCoreThreads()方法,这个方法用来为线程池预先启动corePoolSize个worker等待从workQueue中获取任务执行
执行流程:
判断线程池当前是否为可以添加worker线程的状态
- 可以则继续下一步
- 不可以return false;
A.线程池状态>shutdown: 可能为stop、tidying、terminated,不能添加worker线程
B.线程池状态==shutdown: firstTask不为空,不能添加worker线程,因为shutdown状态的线程池不接收新任务
C.线程池状态==shutdown, firstTask == null, workQueue为空: 不能添加worker线程,因为firstTask为空是为了添加一个没有任务的线程再从workQueue获取task,而workQueue为空,说明添加无任务线程已经没有意义
线程池当前线程数量是否超过上限(corePoolSize 或 maximumPoolSize)
- 超过了return false
- 没超过则对workerCount+1,继续下一步
在线程池的ReentrantLock保证下,向WorkersSet中添加新创建的worker实例,添加完成后解锁,并启动worker线程
- 如果这一切都成功了,return true;
- 如果添加worker入Set失败或启动失败,调用addWorkerFailed()逻辑, 进行回滚
四.内部类Worker
Worker类本身既实现了Runnable,又继承了AbstractQueuedSynchronizer,所以其既是一个可执行的任务,又可以达到锁的效果
① new Worker()
- 将AQS的state置为-1,在runWoker()前不允许中断
- 待执行的任务会以参数传入,并赋予firstTask
- 用Worker这个Runnable创建Thread
之所以Worker自己实现Runnable,并创建Thread,在firstTask外包一层,是因为:
要通过Worker控制工作线程中断,而firstTask这个工作任务只是负责执行业务
② Worker控制中断主要有以下几方面:
初始AQS状态为-1,此时不允许中断interrupt(),只有在worker线程启动了,执行了runWoker(),将state置为0,才能中断;
不允许中断体现在:
- shutdown()线程池时,会对每个worker tryLock()上锁,而Worker类这个AQS的tryAcquire()方法是固定将state从0->1,故初始状态state==-1时tryLock()失败,没发interrupt();
- shutdownNow()线程池时,不用tryLock()上锁,但调用worker.interruptIfStarted()终止worker,interruptIfStarted()也有state>0才能interrupt的逻辑
为了防止某种情况下,在运行中的worker被中断,runWorker()每次运行任务时都会lock()上锁,而shutdown()这类可能会终止worker的操作需要先获取worker的锁,这样就防止了中断正在运行的线程
Worker实现的AQS为不可重入锁,为了是在获得worker锁的情况下再进入其它一些需要加锁的方法
③ Worker和Task的区别
Worker是线程池中的线程,而Task虽然是runnable,但是并没有真正启动线程执行,只是被Worker调用了run方法!!!!
runWorker()执行任务
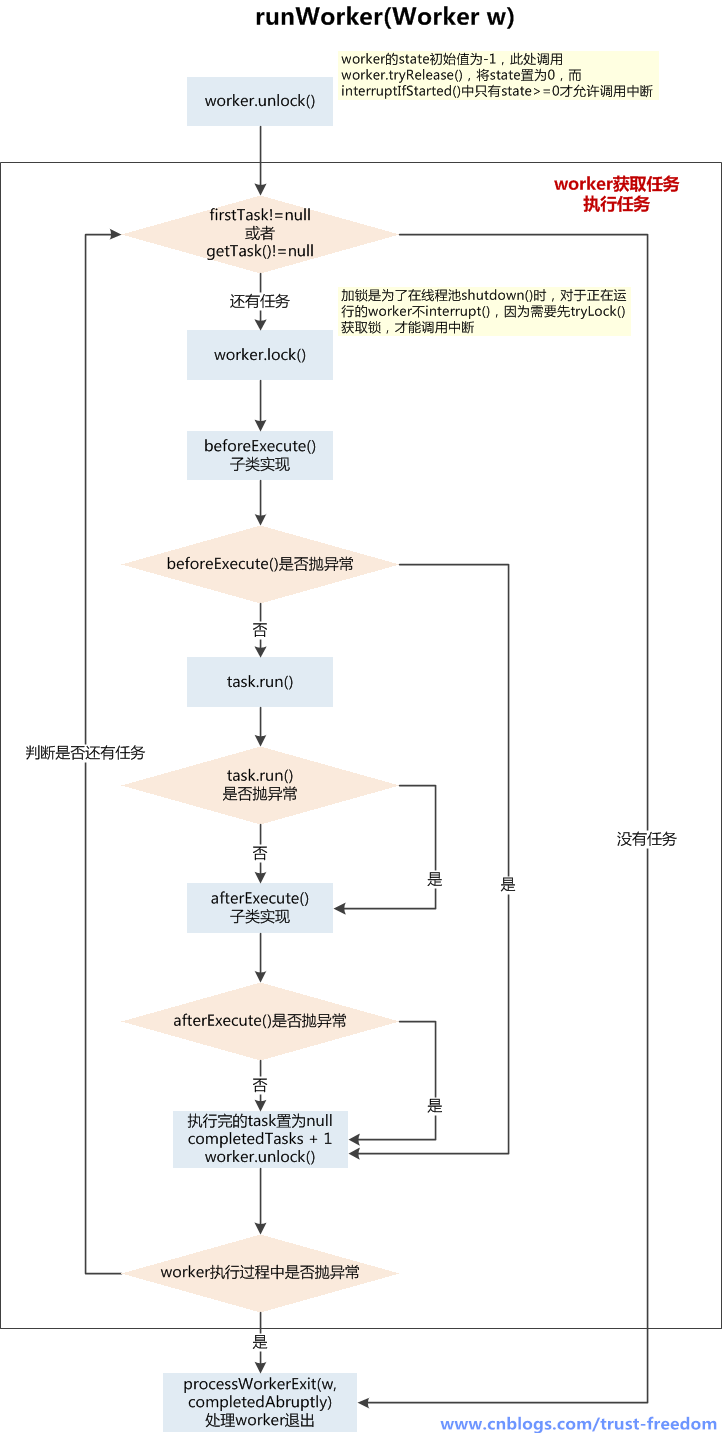
执行流程:
1、Worker线程启动后,通过Worker类的run()方法调用runWorker(this)
2、执行任务之前,首先worker.unlock(),将AQS的state置为0,允许中断当前worker线程
3、开始执行firstTask,调用task.run(),在执行任务前会上锁wroker.lock(),在执行完任务后会解锁,为了防止在任务运行时被线程池一些中断操作中断
4、在任务执行前后,可以根据业务场景自定义beforeExecute() 和 afterExecute()方法
5、无论在beforeExecute()、task.run()、afterExecute()发生异常上抛,都会导致worker线程终止,进入processWorkerExit()处理worker退出的流程
6、如正常执行完当前task后,会通过getTask()从阻塞队列中获取新任务,当队列中没有任务,且获取任务超时,那么当前worker也会进入退出流程
getTask()获取任务
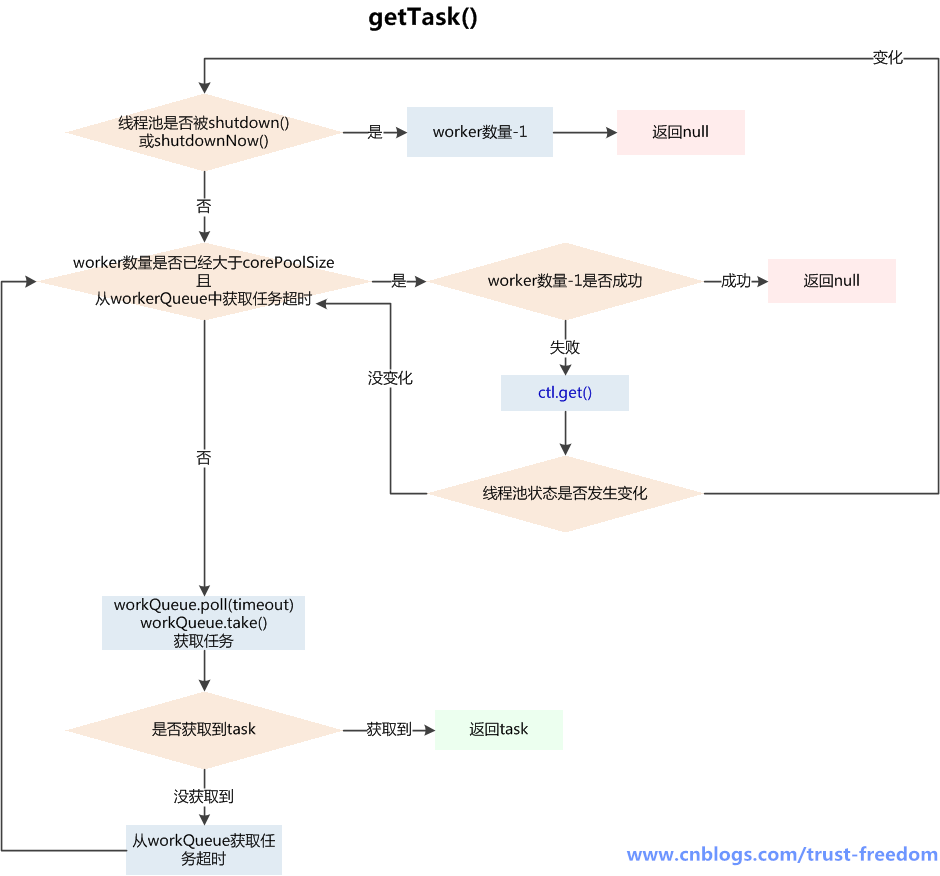
执行流程:
1、首先判断是否可以满足从workQueue中获取任务的条件,不满足return null
线程池状态是否满足:
- shutdown状态 + workQueue为空 或 stop状态,都不满足,因为被shutdown后还是要执行workQueue剩余的任务,但workQueue也为空,就可以退出了
- stop状态,shutdownNow()操作会使线程池进入stop,此时不接受新任务,中断正在执行的任务,workQueue中的任务也不执行了,故return null返回
线程数量是否超过maximumPoolSize 或 获取任务是否超时
- 线程数量超过maximumPoolSize可能是线程池在运行时被调用了setMaximumPoolSize()被改变了大小,否则已经addWorker()成功不会超过maximumPoolSize
- 如果 当前线程数量>corePoolSize,才会检查是否获取任务超时,这也体现了当线程数量达到maximumPoolSize后,如果一直没有新任务,会逐渐终止worker线程直到corePoolSize
2、如果满足获取任务条件,根据是否需要定时获取调用不同方法:
- workQueue.poll():如果在keepAliveTime时间内,阻塞队列还是没有任务,返回null
- workQueue.take():如果阻塞队列为空,当前线程会被挂起等待;当队列中有任务加入时,线程被唤醒,take方法返回任务
3、在阻塞从workQueue中获取任务时,可以被interrupt()中断,代码中捕获了InterruptedException,重置timedOut为初始值false,再次执行第1步中的判断,满足就继续获取任务,不满足return null,会进入worker退出的流程
processWorkerExit() worker线程退出
processWorkerExit(Worker w, boolean completedAbruptly)
参数:
- worker: 要结束的worker
- completedAbruptly: 是否突然完成(是否因为异常退出)
执行流程:
1、worker数量-1
- 如果是突然终止,说明是task执行时异常情况导致,即run()方法执行时发生了异常,那么正在工作的worker线程数量需要-1
- 如果不是突然终止,说明是worker线程没有task可执行了,不用-1,因为已经在getTask()方法中-1了
2、从Workers Set中移除worker,删除时需要上锁mainlock
3、tryTerminate():在对线程池有负效益的操作时,都需要“尝试终止”线程池,大概逻辑:判断线程池是否满足终止的状态:
- 如果状态满足,但还有线程池还有线程,尝试对其发出中断响应,使其能进入退出流程
- 没有线程了,更新状态为tidying->terminated
4、是否需要增加worker线程,如果线程池还没有完全终止,仍需要保持一定数量的线程
线程池状态是running 或 shutdown
- 如果当前线程是突然终止的,addWorker()
- 如果当前线程不是突然终止的,但当前线程数量 < 要维护的线程数量,addWorker()
故如果调用线程池shutdown(),直到workQueue为空前,线程池都会维持corePoolSize个线程,然后再逐渐销毁这corePoolSize个线程
五.线程池终止
shutdown()温柔的终止线程池
① shutdown()执行流程:
1、上锁,mainLock是线程池的主锁,是可重入锁,当要操作workers set这个保持线程的HashSet时,需要先获取mainLock,还有当要处理largestPoolSize、completedTaskCount这类统计数据时需要先获取mainLock
2、判断调用者是否有权限shutdown线程池
3、使用CAS操作将线程池状态设置为shutdown,shutdown之后将不再接收新任务
4、中断所有空闲线程 interruptIdleWorkers()
5、onShutdown(),ScheduledThreadPoolExecutor中实现了这个方法,可以在shutdown()时做一些处理
6、解锁
7、尝试终止线程池 tryTerminate()
可以看到shutdown()方法最重要的几个步骤是:更新线程池状态为shutdown、中断所有空闲线程、tryTerminated()尝试终止线程池
那么,什么是空闲线程?interruptIdleWorkers() 是怎么中断空闲线程的?
通过interruptIdleWorkers()方法
② interruptIdleWorkers()
interruptIdleWorkers() 首先会获取mainLock锁,因为要迭代workers set,在中断每个worker前,需要做两个判断:
1、线程是否已经被中断,是就什么都不做
2、worker.tryLock() 是否成功
第二个判断比较重要,因为Worker类除了实现了可执行的Runnable,也继承了AQS,本身也是一把锁
tryLock()调用了Worker自身实现的tryAcquire()方法,这也是AQS规定子类需要实现的尝试获取锁的方法
tryAcquire()先尝试将AQS的state从0–>1,返回true代表上锁成功,并设置当前线程为锁的拥有者
可以看到compareAndSetState(0, 1)只尝试了一次获取锁,且不是每次state+1,而是0–>1,说明锁不是可重入的
③ 为什么要worker.tryLock()获取worker的锁呢?
这就是Woker类存在的价值之一,控制线程中断
在runWorker()方法中每次获取到task,task.run()之前都需要worker.lock()上锁,运行结束后解锁,即正在运行任务的工作线程都是上了worker锁的
在interruptIdleWorkers()中断之前需要先tryLock()获取worker锁,意味着正在运行的worker不能中断,因为worker.tryLock()失败,且锁是不可重入的
故shutdown()只有对能获取到worker锁的空闲线程(正在从workQueue中getTask(),此时worker没有加锁)发送中断信号
由此可以将worker划分为:
1、空闲worker:正在从workQueue阻塞队列中获取任务的worker
2、运行中worker:正在task.run()执行任务的worker
正阻塞在getTask()获取任务的worker在被中断后,会抛出InterruptedException,不再阻塞获取任务
捕获中断异常后,将继续循环到getTask()最开始的判断线程池状态的逻辑,当线程池是shutdown状态,且workQueue.isEmpty时,return null,进行worker线程退出逻辑
某些情况下,interruptIdleWorkers()时多个worker正在运行,不会对其发出中断信号,假设此时workQueue也不为空
那么当多个worker运行结束后,会到workQueue阻塞获取任务,获取到的执行任务,没获取到的,如果还是核心线程,会一直workQueue.take()阻塞住,线程无法终止,因为workQueue已经空了,且shutdown后不会接收新任务了
这就需要在shutdown()后,还可以发出中断信号
Doug Lea大神巧妙的在所有可能导致线程池产终止的地方安插了tryTerminated()尝试线程池终止的逻辑,并在其中判断如果线程池已经进入终止流程,没有任务等待执行了,但线程池还有线程,中断唤醒一个空闲线程
④ tryTerminated()
tryTerminate() 执行流程:
1、判断线程池是否需要进入终止流程(只有当shutdown状态+workQueue.isEmpty 或 stop状态,才需要)
2、判断线程池中是否还有线程,有则 interruptIdleWorkers(ONLY_ONE) 尝试中断一个空闲线程(正是这个逻辑可以再次发出中断信号,中断阻塞在获取任务的线程)
3、如果状态是SHUTDOWN,workQueue也为空了,正在运行的worker也没有了,开始terminated
会先上锁,将线程池置为tidying状态,之后调用需子类实现的 terminated(),最后线程池置为terminated状态,并唤醒所有等待线程池终止这个Condition的线程
shutdownNow()强硬的终止线程池
shutdownNow() 和 shutdown()的大体流程相似,差别是:
1、将线程池更新为stop状态
2、调用 interruptWorkers() 中断所有线程,包括正在运行的线程
3、将workQueue中待处理的任务移到一个List中,并在方法最后返回,说明shutdownNow()后不会再处理workQueue中的任务
interruptWorkers()
interruptWorkers() 很简单,循环对所有worker调用 interruptIfStarted(),其中会判断worker的AQS state是否大于0,即worker是否已经开始运作,再调用Thread.interrupt()
需要注意的是,对于运行中的线程调用Thread.interrupt()并不能保证线程被终止,task.run()内部可能捕获了InterruptException,没有上抛,导致线程一直无法结束
awaitTermination()等待线程池终止
参数:
- timeout:超时时间
- unit: timeout超时时间的单位
返回:
- true:线程池终止
- false:超过timeout指定时间
在发出一个shutdown请求后,在以下3种情况发生之前,awaitTermination()都会被阻塞
1、所有任务完成执行
2、到达超时时间
3、当前线程被中断
awaitTermination() 循环的判断线程池是否terminated终止或是否已经超过超时时间,然后通过termination这个Condition阻塞等待一段时间
termination.awaitNanos() 是通过LockSupport.parkNanos(this, nanosTimeout)实现的阻塞等待
阻塞等待过程中发生以下具体情况会解除阻塞(对上面3种情况的解释):
1、如果发生了 termination.signalAll()(内部实现是 LockSupport.unpark())会唤醒阻塞等待,且由于ThreadPoolExecutor只有在 tryTerminated()尝试终止线程池成功,将线程池更新为terminated状态后才会signalAll(),故awaitTermination()再次判断状态会return true退出
2、如果达到了超时时间 termination.awaitNanos() 也会返回,此时nano==0,再次循环判断return false,等待线程池终止失败
3、如果当前线程被 Thread.interrupt(),termination.awaitNanos()会上抛InterruptException,awaitTermination()继续上抛给调用线程,会以异常的形式解除阻塞
故终止线程池并需要知道其是否终止可以用如下方式:
executorService.shutdown();
try {
while(!executorService.awaitTermination(500, TimeUnit.MILLISECONDS)) {
LOGGER.debug("Waiting for terminate");
}
}
catch(InterruptedException e) {
//中断处理
}六.线程池的监控
通过继承线程池进行监控
可以通过继承线程池来自定义线程池,重写线程池的 beforeExecute、afterExecute和terminated方法,也可以在任务执行前、执行后和线程池关闭前执 行一些代码来进行监控
例如,监控任务的平均执行时间、最大执行时间和最小执行时间等。 这几个方法在线程池里是空方法
① getTaskCount()
获取线程池需要执行的任务数量
总数=已经结束线工作程完成的任务数(completedTaskCount) + 还未结束线程工作线程完成的任务数(w.completedTasks)+正在执行的任务数(w.isLocked())+还未执行的任务数(workQueue.size())
② getCompletedTaskCount()
获取线程池在运行过程中已完成的任务数量
总数=已经结束线工作程完成的任务数(completedTaskCount) + 还未结束线程工作线程完成的任务数(w.completedTasks)
③ getLargestPoolSize()
获取线程池里曾经创建过的最大线程数量
通过这个数据可以知道线程池是 否曾经满过: 如该数值等于线程池的最大大小,则表示线程池曾经满过
④ getPoolSize()
获取线程池的线程数量
如果线程池不销毁的话,线程池里的线程不会自动销 毁,所以这个大小只增不减
⑤ getActiveCount()
获取活动的线程数
总结
零零洒洒总结完了ThreadPoolExecutor的源码, 总体来说, 在阅读ThreadPoolExecutor源码的时候, 遵循以下几个步骤即可:
- ctl属性;
- ThreadPoolExecutor中其他属性;
- 任务提交的实现;
- 内部类Worker(任务执行, 终止)
- 线程池终止
- 线程池的监控
最后说一下如何合理地配置线程池
要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析:
- 任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
- 任务的优先级:高、中和低。
- 任务的执行时间:长、中和短
- 任务的依赖性:是否依赖其他系统资源,如数据库连接
性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务应配置尽可能小的 线程,如配置Ncpu+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配 置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务 和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量 将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高 的任务先执行。
- 如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能 执行。
- 可以通过 Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
- 建议使用有界队列有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点 儿,比如几千。无界队列在某些异常情况下可能会撑爆内存。
N核服务器,通过执行业务的单线程分析出本地计算时间为x,等待时间为y,则工作线程数(线程池线程数)设置为 N*(x+y)/x,能让CPU的利用率最大化
详情可以参考线程数究竟设多少合理
附录
参考文章:
如果觉得文章写的不错, 可以关注微信公众号: Coder张小凯
内容和博客同步更新~