
最近总结了一套阿里云的面试题, 其中有一个ThreadLocal和线程池配合使用造成内存泄露的问题. 当时写了答案但是感觉对于ThreadLocal的理解还不是特别深入, 所以想再看一下源码.
一. ThreadLocal的简介
ThreadLocal介绍
ThreadLocal望文生义,简单解释就是线程的本地变量
JDK对它的定义:
该类提供了线程局部 (thread-local) 变量。这些变量不同于它们的普通对应物,因为访问某个变量(通过其
get或set方法)的每个线程都有自己的局部变量,它独立于变量的初始化副本。ThreadLocal实例通常是类中的 private static 字段,它们希望将状态与某一个线程(例如,用户 ID 或事务 ID)相关联
从这段解释中可以看出它是实现线程安全的一种新的方式,不同于以前加锁synchronized的方式, 每个线程都有自己的独立的变量,这样他们之间是互不影响的,这样就间接的解决线程安全的问题。举个通俗的例子,相当于由以前的贫穷年代,大家哄抢一块蛋糕,到现在的物质丰盛年代,每个人都有一块自己的蛋糕,大家互不影响,就不会存在争抢的情况
评价:
ThreadLocal解决了线程局部变量统一定义问题,多线程数据不能共享。(InheritableThreadLocal特例除外)不能解决并发问题
解决了:基于类级别的变量定义,每一个线程单独维护自己线程内的变量值(存、取、删的功能)
ThreadLocal的构造方法
/**
* 创建一个ThreadLocal变量
* Creates a thread local variable.
* @see #withInitial(java.util.function.Supplier)
*/
public ThreadLocal() {}
/**
* JDK 1.8 新加入内容, 通过Supplier创建一个ThreadLocal
* (实际上是一个内部类SuppliedThreadLocal, 继承自ThreadLocal)
* 获取时采用Supplier的get()方法
*
* Creates a thread local variable. The initial value of the variable is
* determined by invoking the {@code get} method on the {@code Supplier}.
*
* @param <S> the type of the thread local's value
* @param supplier the supplier to be used to determine the initial value
* @return a new thread local variable
* @throws NullPointerException if the specified supplier is null
* @since 1.8
*/
public static <S> ThreadLocal<S> withInitial(Supplier<? extends S> supplier) {
return new SuppliedThreadLocal<>(supplier);
}
评价:
构造方法比较简单, 一个是默认的空的构造方法, 另一个是JDK 1.8之后加入的通过Supplier(实际上也是Lambda表达式)构造.
下面给出一个通过Supplier创建ThreadLocal的例子:
/** * ThreadLocal的Lambda构造方式: withInitial * * @author zk */ public class ThreadLocalWithInitial { /** * 运行入口 * * @param args 运行参数 */ public static void main(String[] args) throws InterruptedException { System.out.println("Safe deposit"); safeDeposit(); Thread.sleep(1000); System.out.println(); System.out.println("Not safe deposit"); notSafeDeposit(); } /** * 线程安全的存款 */ private static void safeDeposit() { SafeBank bank = new SafeBank(); Thread thread1 = new Thread(() -> bank.deposit(200), "Jasonkay"); Thread thread2 = new Thread(() -> bank.deposit(200), "马云"); Thread thread3 = new Thread(() -> bank.deposit(500), "马化腾"); thread1.start(); thread2.start(); thread3.start(); } /** * 非线程安全的存款 */ private static void notSafeDeposit() { NotSafeBank bank = new NotSafeBank(); Thread thread1 = new Thread(() -> bank.deposit(200), "Jasonkay"); Thread thread2 = new Thread(() -> bank.deposit(200), "马云"); Thread thread3 = new Thread(() -> bank.deposit(500), "马化腾"); thread1.start(); thread2.start(); thread3.start(); } } class NotSafeBank { /** * 当前余额 */ private int balance = 1000; /** * 存款 * * @param money 存款金额 */ public void deposit(int money) { String threadName = Thread.currentThread().getName(); System.out.println(threadName + " -> 当前账户余额为:" + this.balance); this.balance += money; System.out.println(threadName + " -> 存入 " + money + " 后,当前账户余额为:" + this.balance); } } /** * 线程安全的银行 */ class SafeBank { /** * 当前余额 */ private ThreadLocal<Integer> balance = ThreadLocal.withInitial(() -> 1000); /** * 存款 * * @param money 存款金额 */ public void deposit(int money) { String threadName = Thread.currentThread().getName(); System.out.println(threadName + " -> 当前账户余额为:" + this.balance.get()); this.balance.set(this.balance.get() + money); System.out.println(threadName + " -> 存入 " + money + " 后,当前账户余额为:" + this.balance.get()); } } ------- Output -------- Safe deposit Jasonkay -> 当前账户余额为:1000 马化腾 -> 当前账户余额为:1000 马云 -> 当前账户余额为:1000 马云 -> 存入 200 后,当前账户余额为:1200 Jasonkay -> 存入 200 后,当前账户余额为:1200 马化腾 -> 存入 500 后,当前账户余额为:1500 Not safe deposit Jasonkay -> 当前账户余额为:1000 马化腾 -> 当前账户余额为:1200 马云 -> 当前账户余额为:1000 马云 -> 存入 200 后,当前账户余额为:1900 马化腾 -> 存入 500 后,当前账户余额为:1700 Jasonkay -> 存入 200 后,当前账户余额为:1200可见使用ThreadLocal保证了各线程分配各自的数据
而使用
private ThreadLocal<Integer> balance = ThreadLocal.withInitial(() -> 1000);创建则省去了先new再setValue的繁琐过程
ThreadLocal的API
ThreadLocal向外暴露出基本的增删改查方法,几个方法都是很简单:
通过get和set方法是访问和修改的入口,再通过remove方法移除值
| 方法 | 说明 |
|---|---|
| T get() | 返回此线程局部变量的当前线程副本中的值 |
| void set(T value) | 将此线程局部变量的当前线程副本中的值设置为指定值 |
| void remove() | 移除此线程局部变量当前线程的值 |
二. ThreadLocal源码分析(基于JDK11.0.4)
线性探测法
由于在ThreadLocalMap中数据存储采用的是线性探测法解决hash冲突, 所以在这里补充一下有关线性探测法的知识:
线性探测法是散列解决冲突的一种方法:
- 当hash一个关键字时,发现没有冲突,就保存关键字;
- 如果出现冲突,则就探测冲突地址下一个地址,依次按照线性查找,直到发现有空地址为止,从而解决冲突
例如: 关键字集合{7、8、30、11、18、9、14},散列函数为: H(key) = (key x 3) MOD 7, 设装填因子(元素个数/散列表长度)为0.7,那么散列表的长度为10
关键字(key)集合存放位置分别为:
| 7 | 8 | 30 | 11 | 18 | 9 | 14 |
|---|---|---|---|---|---|---|
| 0 | 3 | 6 | 5 | 5 | 6 | 0 |
由表格知道,这里的7和14、30和9、11和18出现了位置存放冲突。存放key=7时,散列表长度为10的表中其实没有冲突, 因为7是第一个存在到表中的key,所以一定不会有冲突的,所以7对应散列表的地址0;
8、30、11存放的地址分别是3、 6 、5,但是到了key=18时候,发现存放的地址为5,而地址5已经存放了key=11, 这时发生了地址冲突
根据线性探测法,算法会探测地址5的下一个地址,即地址6,而此时地址6已经存放了key=30,程序继续探测下一个地址,发现地址7位空,此时把key=18存放到地址7处。以此类推,最后得出的散列表为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 7 | 14 | 8 | 11 | 30 | 18 | 9 |
成功查找率:(1+1+1+1+3+3+2)/ 7
不成功查找率:
计算查找不成功的次数就直接找关键字到第一个地址上关键字为空的距离即可, 但根据哈希函数地址为MOD7,因此初始只可能在0-6的位置。等概率情况下,查找0-6位置查找失败的查找次数为:
地址0,到第一个关键字为空的地址2的距离为3,因此查找不成功的次数为3.
地址1, 到第一个关键为空的地址2的距离为2,因此查找不成功的次数为2.
地址2, 到第一个关键为空的地址2的距离为1,因此查找不成功的次数为1.
地址3,到第一个关键为空的地址4的距离为2,因此查找不成功的次数为2.
地址4,到第一个关键为空的地址4的距离为1,因此查找不成功的次数为1.
地址5,到第一个关键为空的地址2(注意不是地址9,因为初始只可能在0~6之间,因此循环回去)的距离为5,因此查找不成功的次数为5.
地址6,到第一个关键为空的地址2(注意不是地址9,因为初始只可能在0~6之间,因此循环回去)的距离为4,因此查找不成功的次数为4.
不成功查找率:(3+2+1+2+1+5+4)/ 7
扩展: 在ThreadLocal中改进了线性探测
① ThreadLocal生成hashcode方法: nextHashCode()
private static AtomicInteger nextHashCode = new AtomicInteger(); private static int nextHashCode() {return extHashCode.getAndAdd(HASH_INCREMENT);}从nextHashCode方法可以看出: ThreadLocal每实例化一次,其hash值就原子增加HASH_INCREMENT = 0x61c88647(选择原因后面解释)
② set方法解读
// threadLocal.set() public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); } ThreadLocalMap getMap(Thread t) { return t.threadLocals; } // threadLocalMap.set() private void set(ThreadLocal<?> key, Object value) { Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1); for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal<?> k = e.get(); if (k == key) { e.value = value; return; } if (k == null) { replaceStaleEntry(key, value, i); return; } } tab[i] = new Entry(key, value); int sz = ++size; if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); }ThreadLocal从当前线程Thread中获取ThreadLocalMap实例(ThreadLocal的内部类);
调用ThreadLocalMap的set()方法[实际set()的实现方法], 进行设置:
- 通过
hash & (len -1)定位到table的位置i,假设table中i位置的元素为f- 如果f != null,假设f中的引用为k:
- 如果k和当前ThreadLocal实例一致,则修改value值,返回;
- 如果k为null,说明这个f已经是stale(陈旧的)的元素。调用replaceStaleEntry方法删除table中所有陈旧的元素(即entry的引用为null)并插入新元素,返回
- 否则通过nextIndex方法找到下一个元素f,继续进行线性探索。 如果f == null,则把Entry加入到table的i位置中。 通过cleanSomeSlots删除陈旧的元素,如果table中没有元素删除,需判断当前情况下是否要进行扩容;
- 如果f == null,则把Entry加入到table的i位置中
- 通过cleanSomeSlots删除陈旧的元素,如果table中没有元素删除,需判断当前情况下是否要进行扩容
所以在ThreadLocal中的线性探索公式为:
index = hash & (len - 1), 并且hash = pre_hash + 0x61c88647(HASH_INCREMENT)顺便提一下: ThreadLocal中使用的是AtomicInteger存放nextHashCode, 所以每次增加是原子操作
阅读源码前的解读
另外, 在进行源码分析之前先纠正一个误区: 很多人以为ThreadLocal的内部维持了一个map,其中以当前线程作为键,传入的数据作为值来进行封装的,这个想法是错误的!
ThreadLocal的内部维护着一个叫做ThreadLocalmap的静态类,它由一个首尾闭合的动态数组组成(默认大小为16),每个数组都是一个Entry对象,该对象以ThreadLocal对象作为key,以传入的数据作为值进行封装而成.以下是TheadLocalMap的图示:
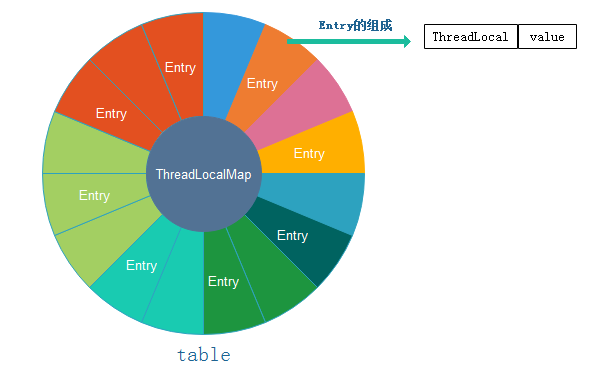
注意:
1. ThreadLocal类封装了set()、get()、remove()3个核心方法
2. 通过getMap()获取每个子线程Thread持有自己的ThreadLocalMap实例, 因此它们是不存在并发竞争的可以理解为每个线程有自己的变量副本
3. ThreadLocalMap中Entry[]数组存储数据,初始化长度16,后续每次都是2倍扩容(主线程中定义了几个变量,Entry[]才有几个key)
4.
Entry的key是对ThreadLocal的弱引用,当抛弃掉ThreadLocal对象时,垃圾收集器会忽略这个key的引用而清理掉ThreadLocal对象, 防止了内存泄漏
注释中的示例代码:
import java.util.concurrent.atomic.AtomicInteger; /** * 每个线程都保持对线程本地变量的副本的隐式引用, * 只要线程是活动的并且{@code ThreadLocal}实例是可访问的; * 在线程离开之后,线程本地实例的所有副本都受到垃圾收集 *(除非存在对这些副本的其他引用) * * Each thread holds an implicit reference to its copy of a thread-local * variable as long as the thread is alive and the {@code ThreadLocal} * instance is accessible; after a thread goes away, all of its copies of * thread-local instances are subject to garbage collection (unless other * references to these copies exist). */ public class ThreadId { // Atomic integer containing the next thread ID to be assigned // 包含要分配的下一个线程ID的原子整数 private static final AtomicInteger nextId = new AtomicInteger(0); // Thread local variable containing each thread's ID // 包含每个线程ID的线程局部变量 private static final ThreadLocal<Integer> threadId = new ThreadLocal<Integer>() { @Override protected Integer initialValue() { return nextId.getAndIncrement(); } }; // Returns the current thread's unique ID, assigning it if necessary // 返回当前线程的唯一ID,必要时将其赋值 public static int get() { return threadId.get(); } }ThreadId类会在每个线程中生成唯一标识符。线程的id在第一次调用threadid.get()时被分配,在随后的调用中保持不变
ThreadId类利用AtomicInteger原子方法getAndIncrement为每个线程创建一个threadId变量,例如: 第一个线程是1,第二个线程是2…,并供一个类静态get方法用以获取当前线程ID
有一个注意点是:用户可以自定义initialValue()初始化方法,来初始化threadLocal的值
关于Entry对象
//用虚引用封装的ThreadLocal
static class Entry extends WeakReference<ThreadLocal> {
Object value; // 声明一个值
Entry(ThreadLocal k, Object v) { // 用ThreadLocal对象和值创建一个Entry
super(k);
value = v;
}
}该对象继承自弱引用WeakReference. 我们知道java中引用类分为4种,强度从大到小的排列顺序为:强引用、软引用、弱引用、虚引用。这样做的最大好处就是可以方便GC处理
其中关于弱引用: 具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象
下面进行源码解读:
import jdk.internal.misc.TerminatingThreadLocal;
import java.lang.ref.*;
import java.util.Objects;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.function.Supplier;
public class ThreadLocal<T> {
/**
* ThreadLocals依赖于附加到每个线程的线性探测哈希映射
* (thread.ThreadLocals和inheritablethrreadlocals)
* ThreadLocal对象充当键,通过threadLocalHashCode进行搜索
* 这是一个自定义散列代码(仅在ThreadLocalMaps中有用)
* 它消除了在相同线程使用连续构造的threadlocal的常见情况下的冲突
* 同时在不太常见的情况下保持良好的性能
*
* ThreadLocals rely on per-thread linear-probe hash maps attached
* to each thread (Thread.threadLocals and
* inheritableThreadLocals). The ThreadLocal objects act as keys,
* searched via threadLocalHashCode. This is a custom hash code
* (useful only within ThreadLocalMaps) that eliminates collisions
* in the common case where consecutively constructed ThreadLocals
* are used by the same threads, while remaining well-behaved in
* less common cases.
*/
private final int threadLocalHashCode = nextHashCode();
/**
* 下一个hashcode, 原子更新, 从零开始
* The next hash code to be given out. Updated atomically. Starts at zero.
*/
private static AtomicInteger nextHashCode = new AtomicInteger();
/**
* 连续生成的散列码之间的差异
* -将隐式顺序线程局部id转换为近似最优分布的乘法散列值
* 以获得两个大小表的幂
*
* The difference between successively generated hash codes - turns
* implicit sequential thread-local IDs into near-optimally spread
* multiplicative hash values for power-of-two-sized tables.
*/
private static final int HASH_INCREMENT = 0x61c88647;
/**
* 返回下一个hashcode
* Returns the next hash code.
*/
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
/**
* 返回此线程局部变量的当前线程“初始值”
* 此方法将在线程第一次使用{@link#get}方法访问变量时调用
* 除非线程以前调用了{@link#set}方法,在这种情况下,不会为线程调用{@code initialValue}方法
* 通常,每个线程最多调用一次此方法,但在随后调用{@link#remove}和{@link#get}时,可能会再次调用此方法
*
* Returns the current thread's "initial value" for this
* thread-local variable. This method will be invoked the first
* time a thread accesses the variable with the {@link #get}
* method, unless the thread previously invoked the {@link #set}
* method, in which case the {@code initialValue} method will not
* be invoked for the thread. Normally, this method is invoked at
* most once per thread, but it may be invoked again in case of
* subsequent invocations of {@link #remove} followed by {@link #get}.
*
* 此实现只返回{@code null};
* 如果程序员希望线程局部变量具有{@code null}以外的初始值
* 则必须对{@code thread local}进行子类化,并重写此方法。通常,将使用匿名内部类
*
* <p>This implementation simply returns {@code null}; if the
* programmer desires thread-local variables to have an initial
* value other than {@code null}, {@code ThreadLocal} must be
* subclassed, and this method overridden. Typically, an
* anonymous inner class will be used.
*
* @return the initial value for this thread-local
*/
protected T initialValue() {
return null;
}
/**
* JDK 1.8新加入的, 通过Supplier创建一个ThreadLocal
*
* @param <S> the type of the thread local's value
* @param supplier the supplier to be used to determine the initial value
* @return a new thread local variable
* @throws NullPointerException if the specified supplier is null
* @since 1.8
*/
public static <S> ThreadLocal<S> withInitial(Supplier<? extends S> supplier) {
return new SuppliedThreadLocal<font color="#ff0000">(supplier);
}
/**
* ThreadLocal默认的构造器
* @see #withInitial(java.util.function.Supplier)
*/
public ThreadLocal() { }
/**
* 返回此线程局部变量的当前线程副本中的值
* 如果变量没有当前线程的值,则首先将其初始化为调用{@link#initialValue}方法返回的值
*
* Returns the value in the current thread's copy of this
* thread-local variable. If the variable has no value for the
* current thread, it is first initialized to the value returned
* by an invocation of the {@link #initialValue} method.
*
* @return the current thread's value of this thread-local
*/
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t); // 通过当前Thread获得ThreadLocalMap对象
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this); // 通过当前ThreadLocal对象获得ThreadLocalMap.Entry
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 如果无法找到对应线程的value值, 则调用setInitialValue()方法将其初始化为null
return setInitialValue();
}
/**
* 如果此线程局部变量的当前线程副本中有值,则返回true
* 即使该值为null
* (即: 没有存值时返回为false; 存了值, 即使为null也返回true, 因为此时会创建一个新的Entry)
* Returns {@code true} if there is a value in the current thread's copy of
* this thread-local variable, even if that values is {@code null}.
*
* @return {@code true} if current thread has associated value in this
* thread-local variable; {@code false} if not
*/
boolean isPresent() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
return map != null && map.getEntry(this) != null;
}
/**
* set()的另一种实现方式来初始化值;
* 如果用户重写了set()方法, 则此方法作为原set()方法(进行初始化)
*
* Variant of set() to establish initialValue. Used instead
* of set() in case user has overridden the set() method.
*
* @return the initial value
*/
private T setInitialValue() {
T value = initialValue(); // 默认实现返回 null
Thread t = Thread.currentThread(); // 获取当前线程
ThreadLocalMap map = getMap(t); // 根据当前线程获取ThreadLocalMap
if (map != null) { // 如果map不为空(说明之前使用过set, 并完成过初始化), 直接调用map的set
map.set(this, value);
} else { // map为空, 创建map
createMap(t, value);
}
if (this instanceof TerminatingThreadLocal) {
TerminatingThreadLocal.register((TerminatingThreadLocal<?>) this);
}
return value;
}
/**
* 将此线程的当前线程副本设置为指定值
* 大多数子类无需重写此方法,只需依赖initialValue方法来设置线程局部变量的值
*
* Sets the current thread's copy of this thread-local variable
* to the specified value. Most subclasses will have no need to
* override this method, relying solely on the {@link #initialValue}
* method to set the values of thread-locals.
*
* @param value the value to be stored in the current thread's copy of
* this thread-local.
*/
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
map.set(this, value);
} else {
createMap(t, value);
}
}
/**
* 删除此线程局部变量的当前线程值
* 如果此线程局部变量随后被当前线程get/read,则其值将通过调用其initialValue方法重新初始化
* 除非其值在中间被当前线程set
* 这可能导致在当前线程中多次调用initialValue方法
*
* Removes the current thread's value for this thread-local
* variable. If this thread-local variable is subsequently
* {@linkplain #get read} by the current thread, its value will be
* reinitialized by invoking its {@link #initialValue} method,
* unless its value is {@linkplain #set set} by the current thread
* in the interim. This may result in multiple invocations of the
* {@code initialValue} method in the current thread.
*
* @since 1.5
*/
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null) {
m.remove(this);
}
}
/**
* 获取与ThreadLocal关联的映射
* 在InheritableThreadLocal中被重写了
*
* Get the map associated with a ThreadLocal. Overridden in
* InheritableThreadLocal.
*
* @param t the current thread
* @return the map
*/
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
/**
* 创建与ThreadLocal关联的映射
* 在InheritableThreadLocal中被重写
*
* Create the map associated with a ThreadLocal. Overridden in
* InheritableThreadLocal.
*
* @param t the current thread
* @param firstValue value for the initial entry of the map
*/
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
/**
* 创建继承的线程局部变量map的工厂方法
* 设计为仅从Thread的构造方法调用
*
* Factory method to create map of inherited thread locals.
* Designed to be called only from Thread constructor.
*
* @param parentMap the map associated with parent thread
* @return a map containing the parent's inheritable bindings
*/
static ThreadLocalMap createInheritedMap(ThreadLocalMap parentMap) {
return new ThreadLocalMap(parentMap);
}
/**
* childValue方法显式地在子类InheritableThreadLocal中定义
* 但在这里内部定义是为了提供createInheritedMap 工厂方法
* 而无需在InheritableThreadLocal中对map类进行子类化
* 这种技术比在方法中嵌入测试实例的方法更可取
*
* Method childValue is visibly defined in subclass
* InheritableThreadLocal, but is internally defined here for the
* sake of providing createInheritedMap factory method without
* needing to subclass the map class in InheritableThreadLocal.
* This technique is preferable to the alternative of embedding
* instanceof tests in methods.
*/
T childValue(T parentValue) {
throw new UnsupportedOperationException();
}
/**
* 继承自ThreadLocal: 从指定的Supplier获取初始值
*
* An extension of ThreadLocal that obtains its initial value from
* the specified {@code Supplier}.
*/
static final class SuppliedThreadLocal<T> extends ThreadLocal<T> {
private final Supplier<? extends T> supplier;
SuppliedThreadLocal(Supplier<? extends T> supplier) {
this.supplier = Objects.requireNonNull(supplier);
}
@Override
protected T initialValue() {
return supplier.get();
}
}
/**
* ThreadLocalMap是一个定制的HashMap,仅适用于维护线程本地值
* 在ThreadLocal类之外不暴露任何方法
* 该类是包私有的,允许在类线程中声明字段
* 为了帮助处理非常大且使用寿命长的场景,哈希表条目使用WeakReferences作为键
* 但是,由于不使用引用队列,因此只有当表开始耗尽空间时,才保证删除过时的条目(存在内存泄漏)
*
* ThreadLocalMap is a customized hash map suitable only for
* maintaining thread local values. No operations are exported
* outside of the ThreadLocal class. The class is package private to
* allow declaration of fields in class Thread. To help deal with
* very large and long-lived usages, the hash table entries use
* WeakReferences for keys. However, since reference queues are not
* used, stale entries are guaranteed to be removed only when
* the table starts running out of space.
*/
static class ThreadLocalMap {
/**
* ThreadLocalMap的内部类, 用于真正存放ThreadLocal的K-V对
* 其中Key是ThreadLocal实例, Value是线程的副本
*
* 此哈希映射中的Entry继承了WeakReference
* 使用包含他的类作为键(始终是ThreadLocal对象)
* 请注意,空键(即entry.get() == null)意味着不再引用该键,因此可以从表中删除该项
* 这些条目在下面的代码中称为“stale entries”(过时的Entry)
*
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k); // 调用WeakReference的构造方法
value = v;
}
}
/**
* 容量初值为16, 一定是2的幂!(配合HASH_INCREMENT[0x61c88647]实现hashcode平均分布)
*/
private static final int INITIAL_CAPACITY = 16;
/**
* ThreadLocalMap内部采用Entry的动态数组实现, 进行动态扩容(扩容大小为2的幂)
*
* The table, resized as necessary.
* table.length MUST always be a power of two.
*/
private Entry[] table;
/**
* ThreadLocalMap中Entry的实际数量
*
* The number of entries in the table.
*/
private int size = 0;
/**
* 进行下一次扩容的阈值
*/
private int threshold; // Default to 0
/**
* 设置扩容阈值, 其值为len的2/3(内部调用时len就是动态数组table的长度)
*
* Set the resize threshold to maintain at worst a 2/3 load factor.
*/
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
/**
* 计算 (i + 1) % len
* Increment i modulo len.
*/
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
/**
* 计算(i + len - 1) % len
* Decrement i modulo len.
*/
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}
/**
* ThreadLocalMap的构造方法, 根据给定的初始的K-V进行初始化:
* (初始化类型为Entry的动态数组, 容量为16; 初始化索引i; 初始化threshold为16 * 2/3 = 10)
* ThreadLocalMaps是懒加载的,我们只在至少有一个条目要放入其中时创建
*
* Construct a new map initially containing (firstKey, firstValue).
* ThreadLocalMaps are constructed lazily, so we only create
* one when we have at least one entry to put in it.
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
/**
* ThreadLocalMap的构造方法, 根据给定的父ThreadLocalMap进行初始化:
* 其中包含来自给定父映射的所有可继承线程局部变量
* (是对于父ThreadLocalMap中table数组各元素的浅复制)
* 仅由CreateInheriteMap调用
*
* Construct a new map including all Inheritable ThreadLocals
* from given parent map. Called only by createInheritedMap.
*
* @param parentMap the map associated with parent thread.
*/
private ThreadLocalMap(ThreadLocalMap parentMap) {
Entry[] parentTable = parentMap.table;
int len = parentTable.length;
// 通过父ThreadLocalMap元素数量初始化扩容阈值
setThreshold(len);
// 初始化数组
table = new Entry[len];
// 对父ThreadLocalMap中的table进行浅复制
// 产生新的Entry, 但存放的是原来的Object的索引!
for (Entry e : parentTable) {
if (e != null) {
@SuppressWarnings("unchecked")
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key != null) {
Object value = key.childValue(e.value);
// new了Entry, 放入的是父table中的value
Entry c = new Entry(key, value);
int h = key.threadLocalHashCode & (len - 1);
while (table[h] != null)
h = nextIndex(h, len);
table[h] = c;
size++;
}
}
}
}
/**
* 获取对应key的Entry
* 此方法本身只处理快速路径: 现有键的直接命中
* 否则它将转发到getEntryAfterMiss方法
* 这是为了最大限度地提高性能直接命中,部分通过使这种方法易于链接
*
* Get the entry associated with key. This method
* itself handles only the fast path: a direct hit of existing
* key. It otherwise relays to getEntryAfterMiss. This is
* designed to maximize performance for direct hits, in part
* by making this method readily inlinable.
*
* @param key the thread local object
* @return the entry associated with key, or null if no such
*/
private Entry getEntry(ThreadLocal<?> key) {
// 通过hashcode计算索引i
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key) // 通过hash槽直接找到了, 则返回
return e;
else // hash槽中没找到, 则调用getEntryAfterMiss()方法
return getEntryAfterMiss(key, i, e);
}
/**
* 在其直接哈希槽中找不到key时使用的getEntry方法(发生了hash冲突)
*
* Version of getEntry method for use when key is not found in
* its direct hash slot.
*
* @param key the thread local object
* @param i the table index for key's hash code
* @param e the entry at table[i]
* @return the entry associated with key, or null if no such
*/
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
// 当前e不为空
while (e != null) {
ThreadLocal<?> k = e.get(); // 获得当前Entry的key
if (k == key) // 找到对应key的value, 返回
return e;
if (k == null) // key为null(遇到了脏entry, key为null, 但是value没有被回收)
// 调用expungeStaleEntry()方法, 清理掉脏entry
expungeStaleEntry(i);
else // 否则根据当前索引计算下一个索引i
i = nextIndex(i, len);
// 寻找下一个i
e = tab[i];
}
return null;
}
/**
* 设置(添加或修改)给定key的value
*
* set方法可能会有的情况:
* 1. 探测过程中slot都不无效,并且顺利找到key所在的slot,直接替换即可;
* 2. 探测过程中发现有无效slot,调用replaceStaleEntry
* 效果是最终一定会把key和value放在这个slot,并且会尽可能清理无效slot;
* - 在replaceStaleEntry过程中,如果找到了key,则做一个swap把它放到那个无效slot中,value置为新值
* - 在replaceStaleEntry过程中,没有找到key,直接在无效slot原地放entry
* 3. 探测没有发现key,则在连续段末尾的后一个空位置放上entry,这也是线性探测法的一部分
* 放完后,做一次启发式清理,如果没清理出去key,并且当前table大小已经超过阈值了,则做一次rehash
* rehash函数会调用一次全量清理slot方法也即expungeStaleEntries
* 如果完了之后table大小超过了threshold - threshold / 4,则进行扩容2倍
*
* Set the value associated with key.
*
* @param key the thread local object
* @param value the value to be set
*/
private void set(ThreadLocal<?> key, Object value) {
// 不使用get()方法
// 因为在使用set()方法创建新的Entry时, 需要替换之前的旧的Entry
// 这使得在get()方法中使用的快速路径会更频繁的失败
// (我觉得是在方法调用栈等方面的权衡, 最终导致作者用inline又实现了一遍方法)
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
// 获得table
Entry[] tab = table;
// 获得len
int len = tab.length;
// 获得key对应的索引i
int i = key.threadLocalHashCode & (len-1);
// 线性探测
// 基本上又写了一遍get()方法的核心内容...
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) { // 找到了key, 修改value;
e.value = value;
return;
}
if (k == null) { // key为null, 替换失效的entry
replaceStaleEntry(key, value, i);
return;
}
}
// 没有发现key
tab[i] = new Entry(key, value);
int sz = ++size;
// 调用cleanSomeSlots()做一次启发式清理
// 如果没清理出去key, 并且当前table大小已经超过阈值了, 做一次rehash
if (!cleanSomeSlots(i, sz) && sz >= threshold)
// rehash方法会调用一次全量清理slot方法也即expungeStaleEntries
// 如果完了之后table大小超过了threshold - threshold / 4,则进行扩容2倍
rehash();
}
/**
* 从map中删除ThreadLocal
* 直接在table中找key,如果找到了,把弱引用断了做一次段清理
*
* Remove the entry for key.
*/
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
// 显式断开弱引用
e.clear();
// 进行段清理
expungeStaleEntry(i);
return;
}
}
}
/**
* 用指定key的Entry替换set操作期间遇到的过时Entry
* 在value中传递的值被存储在Entry中,无论是否已存在指定键的条目
*
* Replace a stale entry encountered during a set operation
* with an entry for the specified key. The value passed in
* the value parameter is stored in the entry, whether or not
* an entry already exists for the specified key.
*
* 作为副作用,此方法将删除包含替换Entry在内的“运行”中的所有过时Entry
*(两个空槽之间的条目序列)
*
* As a side effect, this method expunges all stale entries in the
* "run" containing the stale entry. (A run is a sequence of entries
* between two null slots.)
*
* @param key the key
* @param value the value to be associated with key
* @param staleSlot index of the first stale entry encountered while
* searching for key.
*/
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
// 向前扫描,查找最前的一个无效slot
// 我们一次清理整个运行运行期间的无效Entry
// 避免由于垃圾收集器释放大量的引用(即每当收集器运行时)而导致持续的增量rehash
// We clean out whole runs at a time to avoid continual
// incremental rehashing due to garbage collector freeing
// up refs in bunches (i.e., whenever the collector runs).
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
// 向后遍历table, 查找key后面的尾随空槽,以先出现的为准
// Find either the key or trailing null slot of run, whichever occurs first
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 如果找到密钥,则需要将其与陈旧的Entry交换,以维护哈希表顺序
// 然后,可以将新失效的空槽或其上方遇到的任何其他失效空槽发送到expungeStaleEntry
// 以删除或重新刷新运行中的所有其他Entry
// If we find key, then we need to swap it
// with the stale entry to maintain hash table order.
// The newly stale slot, or any other stale slot
// encountered above it, can then be sent to expungeStaleEntry
// to remove or rehash all of the other entries in run.
if (k == key) {
// 更新对应slot的value值
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
/*
* 如果在整个扫描过程中(包括函数一开始的向前扫描与i之前的向后扫描)
* 找到了之前的无效slot则以那个位置作为清理的起点,
* 否则则以当前的i作为清理起点
*/
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// 如果当前的slot已经无效,并且向前扫描过程中没有无效slot
// 则更新slotToExpunge为当前位置
// If we didn't find stale entry on backward scan, the
// first stale entry seen while scanning for key is the
// first still present in the run.
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// 如果key在table中不存在,则在原地放一个即可
// If key not found, put new entry in stale slot
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// 在探测过程中如果发现任何无效slot,则做一次清理(连续段清理+启发式清理)
// If there are any other stale entries in run, expunge them
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
/**
* ThreadLocal中核心清理方法,它做的事情很简单:
* 从staleSlot开始遍历,将无效(弱引用指向对象被回收)清理
* 即对应entry中的value置为null,将指向这个entry的table[i]置为null,直到扫到空entry
* 另外,在过程中还会对非空的entry作rehash
* 可以说这个方法的作用就是从staleSlot开始清理连续段中的slot(断开强引用,rehash slot等)
*
* 通过重新清除位于过时槽和下一个空槽之间的任何可能发生冲突的Entry来删除过时的Entry
* 这还将删除在后面的null之前遇到的任何其他过时Entry
*
* Expunge a stale entry by rehashing any possibly colliding entries
* lying between staleSlot and the next null slot. This also expunges
* any other stale entries encountered before the trailing null. See
* Knuth, Section 6.4
*
* @param staleSlot index of slot known to have null key
* @return the index of the next null slot after staleSlot
* (all between staleSlot and this slot will have been checked
* for expunging).
*/
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 因为entry对应的ThreadLocal已经被回收,value设为null,显式断开强引用
tab[staleSlot].value = null;
// 显式设置该entry为null,以便垃圾回收
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 清理对应ThreadLocal已经被回收的entry
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
/*
* 对于还没有被回收的情况,需要做一次rehash
* 如果对应的ThreadLocal的ID对len取模出来的索引h不为当前位置i
* 则从h向后线性探测到第一个空的slot,把当前的entry给挪过去
*/
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
/*
* 在原代码的这里有句注释值得一提,原注释如下:
*
* Unlike Knuth 6.4 Algorithm R, we must scan until
* null because multiple entries could have been stale.
*
* 这段话提及了Knuth高德纳的著作TAOCP《计算机程序设计艺术》的6.4章节(散列)
* 中的R算法
* R算法描述了如何从使用线性探测的散列表中删除一个元素
* R算法维护了一个上次删除元素的index,当在非空连续段中扫到某个entry的哈希值取模后的索引
* 还没有遍历到时,会将该entry挪到index那个位置,并更新当前位置为新的index,
* 继续向后扫描直到遇到空的entry
*
* ThreadLocalMap因为使用了弱引用,所以其实每个slot的状态有三种也即
* 有效(value未回收),无效(value已回收),空(entry==null)
* 正是因为ThreadLocalMap的entry有三种状态,所以不能完全套高德纳原书的R算法
*
* 因为expungeStaleEntry函数在扫描过程中还会对无效slot清理将之转为空slot,
* 如果直接套用R算法,可能会出现具有相同哈希值的entry之间断开(中间有空entry)
*/
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
// 返回staleSlot之后第一个空的slot索引
return i;
}
/**
* 启发式地清理slot,
* i对应entry是非无效(指向的ThreadLocal没被回收,或者entry本身为空)
* n是用于控制扫描次数的
* 正常情况下如果log n次扫描没有发现无效slot,方法就结束了
* 但是如果发现了无效的slot,将n置为table的长度len,做一次连续段的清理
* 再从下一个空的slot开始继续扫描
*
* 这个函数有两处地方会被调用:
* 一处是插入的时候可能会被调用,另外个是在替换无效slot的时候可能会被调用,
* 区别是前者传入的n为元素个数,后者为table的容量
*
* Heuristically scan some cells looking for stale entries.
* This is invoked when either a new element is added, or
* another stale one has been expunged. It performs a
* logarithmic number of scans, as a balance between no
* scanning (fast but retains garbage) and a number of scans
* proportional to number of elements, that would find all
* garbage but would cause some insertions to take O(n) time.
*
* @param i a position known NOT to hold a stale entry. The
* scan starts at the element after i.
*
* @param n scan control: {@code log2(n)} cells are scanned,
* unless a stale entry is found, in which case
* {@code log2(table.length)-1} additional cells are scanned.
* When called from insertions, this parameter is the number
* of elements, but when from replaceStaleEntry, it is the
* table length. (Note: all this could be changed to be either
* more or less aggressive by weighting n instead of just
* using straight log n. But this version is simple, fast, and
* seems to work well.)
*
* @return true if any stale entries have been removed.
*/
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
// i在任何情况下自己都不会是一个无效slot,所以从下一个开始判断
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
// 扩大扫描控制因子
n = len;
removed = true;
// 清理一个连续段
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
/**
* 重新包装和/或调整table的容量
* 首先扫描整个表以删除过时的Entry
* 如果这不能充分缩小表的大小(使得数据能够插入, 并且小于threshold),将表容量增加一倍
*
* Re-pack and/or re-size the table. First scan the entire
* table removing stale entries. If this doesn't sufficiently
* shrink the size of the table, double the table size.
*/
private void rehash() {
// 做一次全量清理
expungeStaleEntries();
/*
* 因为做了一次清理,所以size很可能会变小
* ThreadLocalMap这里的实现是调低阈值来判断是否需要扩容,
* threshold默认为len*2/3,所以这里的threshold - threshold / 4相当于len/2
*/
if (size >= threshold - threshold / 4)
resize();
}
/**
* 扩容,因为需要保证table的容量len为2的幂,所以扩容即扩大2倍
* 复制table的元素到newTab,忽略陈旧的元素
* 假设table中的元素e需要复制到newTab的i位置,如果i位置存在元素,则找下一个空位置进行插入
*
* Double the capacity of the table.
*/
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (Entry e : oldTab) {
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
// 线性探测来存放Entry
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
/**
* 做一次全量清理
* Expunge all stale entries in the table.
*/
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null)
/*
* 这里可以取返回值,如果大于j的话取了用,这样也是可行的
* 因为expungeStaleEntry执行过程中是把连续段内所有无效slot都清理了一遍了
*/
expungeStaleEntry(j);
}
}
}
}三. 关于ThreadLocal源码中的一些问题
ThreadLocalMap到底存放在哪里
在Java 1.4之前,threadLocals会导致线程之间发生竞争。在新的设计里,每一个线程都有他们自己的ThreadLocalMap(在Thread类中以属性的方式定义, 并以懒加载的方式初始化),用来提高吞吐量,然而,我们仍然面临内存泄漏的可能性,因为长时间运行线程的ThreadLocalMap中的值不会被清除
在Java的早期版本中,threadLocals在多个线程进行访问的时候存在竞争问题,使得它们在多核应用程序中几乎无用。在Java 1.4中,引入了一个新的设计,设计者把threadLocals直接存储在Thread中。当我们现在调用ThreadLocal的get方法时,将会返回一个当前线程里的实例ThreadLocalMap(ThreadLocal的一个内部类)
当一个线程退出时,它会删除它ThreadLocal里的所有值。这发生在exit()方法中,垃圾回收之前,如果我们在使用ThreadLocal后忘记调用remove()方法,那么当线程退出后值还会存在
ThreadLocalMap包含了对ThreadLocal的弱引用以及值的强引用,但是,它并不会判断ReferenceQueue里面哪些弱引用的值已经被清除,因为Entry不可能立即从ThreadLocalMap中清除
threadLocal,threadLocalMap,entry之间的关系如下图所示:
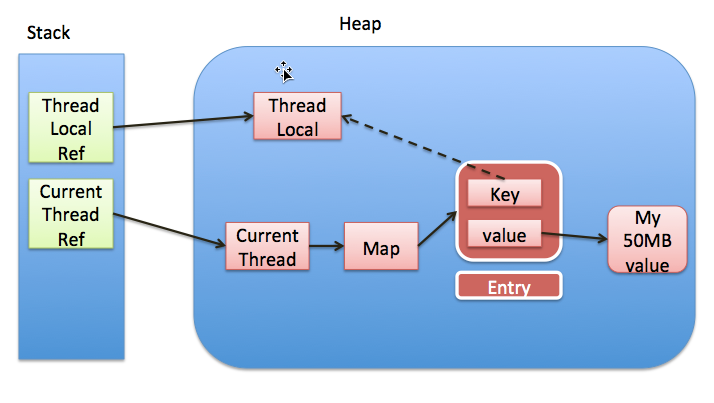
上图中,实线代表强引用,虚线代表的是弱引用
从线程Thread的角度来看,每个线程内部都会持有一个对ThreadLocalMap实例的引用,ThreadLocalMap实例相当于线程的局部变量空间,存储着线程各自的数据
综上所述:
ThreadLocalMap实例在JDK 1.4之后就存在于Thread类中, ThreadLocalMap的定义在ThreadLocal中以内部类的形式;
在使用时, ThreadLocal类似于工具类, 通过
Thread.currentThread()获取当前线程, 然后获取对应的threadLocals进行操作;实际存储线程本地副本的数据结构是ThreadLocalMap中定义的内部类Entry, ThreadLocalMap中定义的Entry[] 动态数组存放实际数据, 通过线性探测法
Entry[] 动态数组的大小初始化为16, 每次扩容翻倍(总是2的幂)
扩容的阈值由threshold提供, 通常为table大小的2/3, 但当size >= threshold时,遍历table并删除key为null的元素,此时如果删除后size >= threshold*3/4时,需要对table进行扩容
为什么使用0x61c88647进行Rehash操作
和通常的线性探测法进行线性的index增加不同, 在ThreadLocal中实际上hashcode每次增加魔数0x61c88647, 用来生成hashcode间隙, 并且官方给出的解释是: 可以让生成出来的值或者说ThreadLocal的ID较为均匀地分布在2的幂大小的数组中
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}可以看出,新的hashcode是在上一个被构造出的ThreadLocal的ID/threadLocalHashCode的基础上加上一个魔数0x61c88647的
实际上, 这个魔数的选取与斐波那契数列(黄金分割数)有关:
0x61c88647对应的十进制为1640531527, 斐波那契散列的乘数可以用(long) ((1L << 31) * (Math.sqrt(5) - 1))可以得到2654435769,如果把这个值给转为带符号的int,则会得到-1640531527
换句话说(1L << 32) - (long) ((1L << 31) * (Math.sqrt(5) - 1))得到的结果就是1640531527也就是0x61c88647
通过理论与实践,当我们用0x61c88647作为魔数累加为每个ThreadLocal分配各自的ID也就是threadLocalHashCode再与2的幂-1按位与,得到的结果分布很均匀
ThreadLocalMap使用的是线性探测法,均匀分布的好处在于很快就能探测到下一个临近的可用slot,从而保证了效率
下面通过一段代码来校验算法的散列性:
/**
* ThreadLocalMap使用“开放寻址法”中最简单的“线性探测法”解决散列冲突问题
*
* @author zk
*/
public class MagicHashCodeTest {
/**
* ThreadLocal中定义的hash魔数
*/
private static final int HASH_INCREMENT = 0x61c88647;
public static void main(String[] args) {
// 初始化16
hashcode(16);
// 后续2倍扩容
hashcode(32);
hashcode(64);
}
private static void hashcode(Integer length) {
var hashcode = 0;
for (var i = 0; i < length; i++) {
// 每次递增HASH_INCREMENT
hashcode = i * HASH_INCREMENT + HASH_INCREMENT;
//求散列下标,算法公式
System.out.print(hashcode & (length-1));
System.out.print(" ");
}
System.out.println();
}
}
------- Output -------
Entry[]初始化容量为16时,元素完美散列:
7 14 5 12 3 10 1 8 15 6 13 4 11 2 9 0
Entry[]容量扩容2倍=32时,元素完美散列:
7 14 21 28 3 10 17 24 31 6 13 20 27 2 9 16 23 30 5 12 19 26 1 8 15 22 29 4 11 18 25 0
Entry[]容量扩容2倍=64时,元素完美散列:
7 14 21 28 35 42 49 56 63 6 13 20 27 34 41 48 55 62 5 12 19 26 33 40 47 54 61 4 11 18 25 32 39 46 53 60 3 10 17 24 31 38 45 52 59 2 9 16 23 30 37 44 51 58 1 8 15 22 29 36 43 50 57 0根据运行结果,代表此算法在长度为2的N次方的数组上,确实可以完美散列
ThreadLocal源码中为了防止内存泄露做出的努力
以下文字转自: 一篇文章,从源码深入详解ThreadLocal内存泄漏问题
再看threadLocal,threadLocalMap,entry之间的关系图:
上图中,实线代表强引用,虚线代表的是弱引用,如果threadLocal外部强引用被置为null(threadLocalInstance=null)的话,threadLocal实例就没有一条引用链路可达,很显然在gc(垃圾回收)的时候势必会被回收, 因此entry就存在key为null的情况,而无法通过一个key为null去访问到该entry的value
同时,就存在了这样一条引用链:threadRef->currentThread->threadLocalMap->entry->valueRef->valueMemory, 导致在垃圾回收的时候进行可达性分析的时候, value可达! 从而不会被回收掉,但是该value永远不能被访问到,这样就存在了内存泄漏
当然,如果线程执行结束后,threadLocal,threadRef会断掉,因此threadLocal,threadLocalMap,entry都会被回收掉
可是,在实际使用中我们都是会用线程池去维护我们的线程,比如在Executors.newFixedThreadPool()时创建线程的时候,为了复用线程是不会结束的,所以threadLocal内存泄漏就值得我们关注!
实际上,为了解决ThreadLocal潜在的内存泄漏的问题,Josh Bloch and Doug Lea大师已经做了一些改进。在threadLocal的set和get方法中都有相应的处理。下文为了叙述,针对key为null的entry,源码注释为stale entry,直译为不新鲜的entry,这里我就称之为“脏entry”。比如在ThreadLocalMap的set方法中:
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}在ThreadLocalMap.set方法中针对脏entry做了这样的处理:
① 如果当前table[i] != null的话说明hash冲突就需要向后环形查找,若在查找过程中遇到脏entry就通过replaceStaleEntry进行处理;
② 如果当前table[i] == null的话说明新的entry可以直接插入,但是插入后会调用cleanSomeSlots方法检测并清除脏entry
cleanSomeSlots
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}入参:
① i的意义
插入entry的位置i,很显然在上述情况(table[i]==null)中,entry刚插入后该位置i很显然不是脏entry;
② 参数n的用途
主要用于扫描控制(scan control),从while中是通过n来进行条件判断的说明n就是用来控制扫描趟数(循环次数)的
在扫描过程中,如果没有遇到脏entry就整个扫描过程持续log2(n)次,log2(n)的得来是因为n >>>= 1,每次n右移一位相当于n除以2。如果在扫描过程中遇到脏entry的话就会令n为当前hash表的长度(n=len),再扫描log2(n)趟,注意此时n增加无非就是多增加了循环次数从而通过nextIndex往后搜索的范围扩大,示意图如下
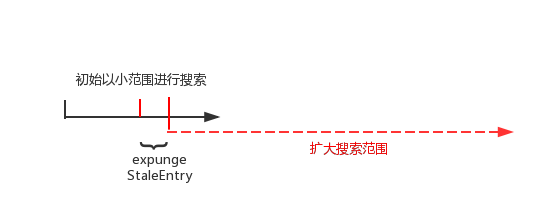
按照n的初始值,搜索范围为黑线,当遇到了脏entry,此时n变成了哈希数组的长度(n取值增大),搜索范围log2(n)增大,红线表示。如果在整个搜索过程没遇到脏entry的话,搜索结束,采用这种方式的主要是用于时间效率上的平衡
③ n的取值
如果是在set方法插入新的entry后调用,n位当前已经插入的entry个数size;如果是在replaceSateleEntry方法中调用n为哈希表的长度len
expungeStaleEntry
如果对输入参数能够理解的话,那么cleanSomeSlots方法搜索基本上就清除了,但是全部搞定还需要掌握expungeStaleEntry方法,当在搜索过程中遇到了脏entry的话就会调用该方法去清理掉脏entry。源码为:
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
//清除当前脏entry
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
//2.往后环形继续查找,直到遇到table[i]==null时结束
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
//3. 如果在向后搜索过程中再次遇到脏entry,同样将其清理掉
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
//处理rehash的情况
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}该方法主要做了这么几件事情:
① 清理当前脏entry,即将其value引用置为null,并且将table[staleSlot]也置为null。value置为null后该value域变为不可达,在下一次gc的时候就会被回收掉,同时table[staleSlot]为null后以便于存放新的entry;
② 从当前staleSlot位置向后环形(nextIndex)继续搜索,直到遇到哈希桶(tab[i])为null的时候退出;
③ 若在搜索过程再次遇到脏entry,继续将其清除。
也就是说该方法,清理掉当前脏entry后,并没有闲下来继续向后搜索,若再次遇到脏entry继续将其清理,直到哈希桶(table[i])为null时退出。因此方法执行完的结果为 从当前脏entry(staleSlot)位到返回的i位,这中间所有的entry不是脏entry。为什么是遇到null退出呢?原因是存在脏entry的前提条件是 当前哈希桶(table[i])不为null,只是该entry的key域为null。如果遇到哈希桶为null,很显然它连成为脏entry的前提条件都不具备。
现在对cleanSomeSlot方法做一下总结,cleanSomeSlot方法主要有这样几点:
① 从当前位置i处(位于i处的entry一定不是脏entry)为起点在初始小范围(log2(n),n为哈希表已插入entry的个数size)开始向后搜索脏entry,若在整个搜索过程没有脏entry,方法结束退出;
② 如果在搜索过程中遇到脏entryt通过expungeStaleEntry方法清理掉当前脏entry,并且该方法会返回下一个哈希桶(table[i])为null的索引位置为i。这时重新令搜索起点为索引位置i,n为哈希表的长度len,再次扩大搜索范围为log2(n’)继续搜索;
下面,以一个例子更清晰的来说一下,假设当前table数组的情况如下图:
如图当前n等于hash表的size即n=10,i=1,在第一趟搜索过程中通过nextIndex,i指向了索引为2的位置,此时table[2]为null,说明第一趟未发现脏entry,则第一趟结束进行第二趟的搜索
第二趟所搜先通过nextIndex方法,索引由2的位置变成了i=3,当前table[3]!=null但是该entry的key为null,说明找到了一个脏entry,先将n置为哈希表的长度len,然后继续调用expungeStaleEntry方法,该方法会将当前索引为3的脏entry给清除掉(令value为null,并且table[3]也为null),但是该方法可不想偷懒,它会继续往后环形搜索,往后会发现索引为4,5的位置的entry同样为脏entry,索引为6的位置的entry不是脏entry保持不变,直至i=7的时候此处table[7]位null,该方法就以i=7返回。至此,第二趟搜索结束;
由于在第二趟搜索中发现脏entry,n增大为数组的长度len,因此扩大搜索范围(增大循环次数)继续向后环形搜索;
直到在整个搜索范围里都未发现脏entry,cleanSomeSlot方法执行结束退出。
replaceStaleEntry
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
//向前找到第一个脏entry
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
1. slotToExpunge = i;
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == key) {
//如果在向后环形查找过程中发现key相同的entry就覆盖并且和脏entry进行交换
2. e.value = value;
3. tab[i] = tab[staleSlot];
4. tab[staleSlot] = e;
// Start expunge at preceding stale entry if it exists
//如果在查找过程中还未发现脏entry,那么就以当前位置作为cleanSomeSlots
//的起点
if (slotToExpunge == staleSlot)
5. slotToExpunge = i;
//搜索脏entry并进行清理
6. cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// If we didn't find stale entry on backward scan, the
// first stale entry seen while scanning for key is the
// first still present in the run.
//如果向前未搜索到脏entry,则在查找过程遇到脏entry的话,后面就以此时这个位置
//作为起点执行cleanSomeSlots
if (k == null && slotToExpunge == staleSlot)
7. slotToExpunge = i;
}
// If key not found, put new entry in stale slot
//如果在查找过程中没有找到可以覆盖的entry,则将新的entry插入在脏entry
8. tab[staleSlot].value = null;
9. tab[staleSlot] = new Entry(key, value);
// If there are any other stale entries in run, expunge them
10. if (slotToExpunge != staleSlot)
//执行cleanSomeSlots
11. cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}首先先看这一部分的代码:
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;这部分代码通过PreIndex方法实现往前环形搜索脏entry的功能,初始时slotToExpunge和staleSlot相同,若在搜索过程中发现了脏entry,则更新slotToExpunge为当前索引i。另外,说明replaceStaleEntry并不仅仅局限于处理当前已知的脏entry,它认为在出现脏entry的相邻位置也有很大概率出现脏entry,所以为了一次处理到位,就需要向前环形搜索,找到前面的脏entry。那么根据在向前搜索中是否还有脏entry以及在for循环后向环形查找中是否找到可覆盖的entry,我们分这四种情况来充分理解这个方法:
① 前向有脏entry
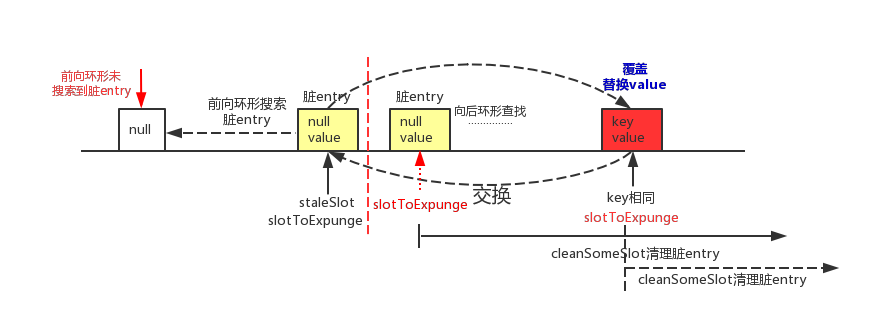
1.1 后向环形查找找到可覆盖的entry
该情形如下图所示。
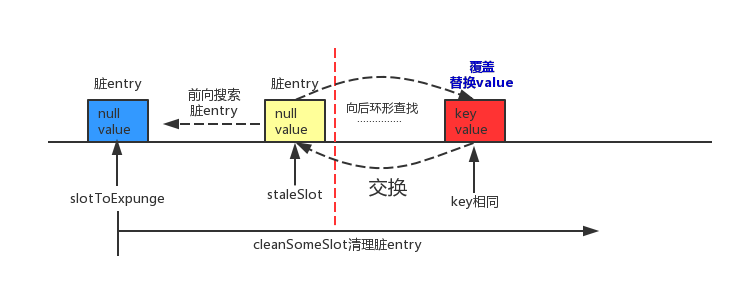
如图,slotToExpunge初始状态和staleSlot相同,当前向环形搜索遇到脏entry时,在第1行代码中slotToExpunge会更新为当前脏entry的索引i,直到遇到哈希桶(table[i])为null的时候,前向搜索过程结束。在接下来的for循环中进行后向环形查找,若查找到了可覆盖的entry,第2,3,4行代码先覆盖当前位置的entry,然后再与staleSlot位置上的脏entry进行交换。交换之后脏entry就更换到了i处,最后使用cleanSomeSlots方法从slotToExpunge为起点开始进行清理脏entry的过程
1.2 后向环形查找未找到可覆盖的entry
该情形如下图所示。
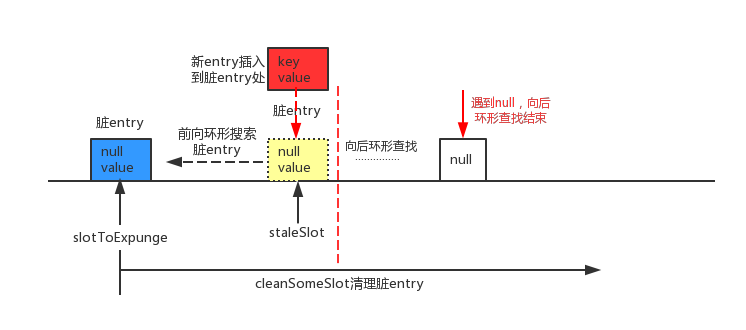
如图,slotToExpunge初始状态和staleSlot相同,当前向环形搜索遇到脏entry时,在第1行代码中slotToExpunge会更新为当前脏entry的索引i,直到遇到哈希桶(table[i])为null的时候,前向搜索过程结束。在接下来的for循环中进行后向环形查找,若没有查找到了可覆盖的entry,哈希桶(table[i])为null的时候,后向环形查找过程结束。那么接下来在8,9行代码中,将插入的新entry直接放在staleSlot处即可,最后使用cleanSomeSlots方法从slotToExpunge为起点开始进行清理脏entry的过程
② 前向没有脏entry
2.1 后向环形查找找到可覆盖的entry
该情形如下图所示。
如图,slotToExpunge初始状态和staleSlot相同,当前向环形搜索直到遇到哈希桶(table[i])为null的时候,前向搜索过程结束,若在整个过程未遇到脏entry,slotToExpunge初始状态依旧和staleSlot相同。在接下来的for循环中进行后向环形查找,若遇到了脏entry,在第7行代码中更新slotToExpunge为位置i。若查找到了可覆盖的entry,第2,3,4行代码先覆盖当前位置的entry,然后再与staleSlot位置上的脏entry进行交换,交换之后脏entry就更换到了i处。如果在整个查找过程中都还没有遇到脏entry的话,会通过第5行代码,将slotToExpunge更新当前i处,最后使用cleanSomeSlots方法从slotToExpunge为起点开始进行清理脏entry的过程
2.2 后向环形查找未找到可覆盖的entry
该情形如下图所示
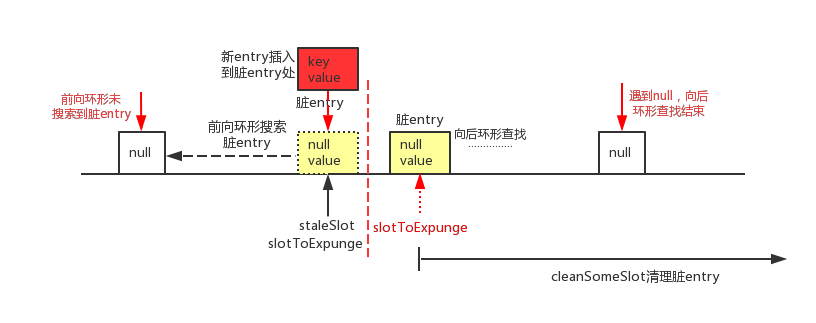
如图,slotToExpunge初始状态和staleSlot相同,当前向环形搜索直到遇到哈希桶(table[i])为null的时候,前向搜索过程结束,若在整个过程未遇到脏entry,slotToExpunge初始状态依旧和staleSlot相同。在接下来的for循环中进行后向环形查找,若遇到了脏entry,在第7行代码中更新slotToExpunge为位置i。若没有查找到了可覆盖的entry,哈希桶(table[i])为null的时候,后向环形查找过程结束。那么接下来在8,9行代码中,将插入的新entry直接放在staleSlot处即可。另外,如果发现slotToExpunge被重置,则第10行代码if判断为true,就使用cleanSomeSlots方法从slotToExpunge为起点开始进行清理脏entry的过程
下面用一个实例来有个直观的感受,示例代码就不给出了,代码debug时table状态如下图所示:
如图所示,当前的staleSolt为i=4,首先先进行前向搜索脏entry,当i=3的时候遇到脏entry,slotToExpung更新为3,当i=2的时候tabel[2]为null,因此前向搜索脏entry的过程结束。然后进行后向环形查找,知道i=7的时候遇到table[7]为null,结束后向查找过程,并且在该过程并没有找到可以覆盖的entry。最后只能在staleSlot(4)处插入新entry,然后从slotToExpunge(3)为起点进行cleanSomeSlots进行脏entry的清理
补充:
当我们调用threadLocal的get方法时,当table[i]不是和所要找的key相同的话,会继续通过threadLocalMap的 getEntryAfterMiss方法向后环形去找
当我们调用threadLocal.remove方法时候,实际上会调用threadLocalMap的remove方法
从以上set,getEntry,remove方法看出,在threadLocal的生命周期里,针对threadLocal存在的内存泄漏的问题,都会通过expungeStaleEntry,cleanSomeSlots,replaceStaleEntry这三个方法清理掉key为null的脏entry
使用弱引用
从文章开头通过threadLocal,threadLocalMap,entry的引用关系看起来threadLocal存在内存泄漏的问题似乎是因为threadLocal是被弱引用修饰的。那为什么要使用弱引用呢?
假设threadLocal使用的是强引用,在业务代码中执行threadLocalInstance==null操作,以清理掉threadLocal实例的目的,但是因为threadLocalMap的Entry强引用threadLocal,因此在gc的时候进行可达性分析,threadLocal依然可达,对threadLocal并不会进行垃圾回收,这样就无法真正达到业务逻辑的目的,出现逻辑错误
假设Entry弱引用threadLocal,尽管会出现内存泄漏的问题,但是在threadLocal的生命周期里(set,getEntry,remove)里,都会针对key为null的脏entry进行处理。
从以上的分析可以看出,使用弱引用的话在threadLocal生命周期里会尽可能的保证不出现内存泄漏的问题,达到安全的状态。
Thread.exit()方法
当线程退出时会执行exit方法:
private void exit() {
if (group != null) {
group.threadTerminated(this);
group = null;
}
/* Aggressively null out all reference fields: see bug 4006245 */
target = null;
/* Speed the release of some of these resources */
threadLocals = null;
inheritableThreadLocals = null;
inheritedAccessControlContext = null;
blocker = null;
uncaughtExceptionHandler = null;
}从源码可以看出当线程结束时,会令threadLocals=null,也就意味着GC的时候就可以将threadLocalMap进行垃圾回收,换句话说threadLocalMap生命周期实际上thread的生命周期相同
在使用ThreadLocal时防止内存泄漏你应该做出的努力
之所以有关于内存泄露的讨论是因为在有线程复用如线程池的场景中,一个线程的寿命很长,大对象长期不被回收影响系统运行效率与安全。如果线程不会复用,用完即销毁了也不会有ThreadLocal引发内存泄露的问题
当我们仔细读过ThreadLocalMap的源码,我们可以推断,如果在使用的ThreadLocal的过程中,显式地进行remove是个很好的编码习惯,这样是不会引起内存泄漏
如果必须使用ThreadLocal,请确保在完成该操作后立即删除该值,并且最好在将线程返回到线程池之前
最佳做法是使用remove()而不是set(null),因为使用remove()将会使WeakReference立即被删除,并与值一起被删除
综上:
- 每次使用完ThreadLocal,都调用它的remove()方法,清除数据
- 在使用线程池的情况下,没有及时清理ThreadLocal,不仅是内存泄漏的问题,更严重的是可能导致业务逻辑出现问题。所以,使用ThreadLocal就跟加锁完要解锁一样,用完就清理
四. ThreadLocal实例
用ThreadLocal解决SimpleDateFormat的线程不安全的问题
SimpleDateFormat是一个线程不安全的格式化日期类, 创建一个SimpleDateFormat实例的开销比较昂贵,解析字符串时间时频繁创建生命周期短暂的实例导致性能低下
即使将SimpleDateFormat定义为静态类变量,貌似能解决这个问题,但是SimpleDateFormat是非线程安全的,同样存在问题,如果用synchronized线程同步同样面临问题,同步导致性能下降(线程之间序列化的获取SimpleDateFormat实例)
ThreadLocal解决了此问题,对于每个线程SimpleDateFormat不存在影响他们之间协作的状态,为每个线程创建一个SimpleDateFormat变量的拷贝:
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @author zk
*/
public class DateUtil {
private static final String DATE_FORMAT = "yyyy-MM-dd HH:mm:ss";
private static SimpleDateFormat notConcurrentSafeSDF = new SimpleDateFormat(DATE_FORMAT);
private static ThreadLocal<SimpleDateFormat> concurrentSafeSDF = ThreadLocal.withInitial(() -> new SimpleDateFormat(DATE_FORMAT));
public static DateFormat getDateFormat() {
return concurrentSafeSDF.get();
}
public static Date parse(String textDate) throws ParseException {
return getDateFormat().parse(textDate);
}
}使用ThreadLocal实现数字自增
/**
* @author zk
*/
public class AutoAddNumber {
private static ThreadLocal<Integer> seqNum = ThreadLocal.withInitial(() -> 0);
public static void main(String[] args) {
AutoAddNumber number = new AutoAddNumber();
for (int i = 0; i < 4; i++) {
new ThreadLocalThreadTest(number).start();
}
}
public int getNextNum() {
seqNum.set(seqNum.get() + 1);
return seqNum.get();
}
static class ThreadLocalThreadTest extends Thread {
private AutoAddNumber number;
public ThreadLocalThreadTest(AutoAddNumber number) {
this.number = number;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println("当前线程是:" + Thread.currentThread().getName() + "对应的编号是:" + number.getNextNum());
}
}
}
}
------- Output -------
当前线程是:Thread-0对应的编号是:1
当前线程是:Thread-0对应的编号是:2
当前线程是:Thread-0对应的编号是:3
当前线程是:Thread-0对应的编号是:4
当前线程是:Thread-0对应的编号是:5
当前线程是:Thread-1对应的编号是:1
当前线程是:Thread-3对应的编号是:1
当前线程是:Thread-3对应的编号是:2
当前线程是:Thread-1对应的编号是:2
当前线程是:Thread-3对应的编号是:3
当前线程是:Thread-1对应的编号是:3
当前线程是:Thread-1对应的编号是:4
当前线程是:Thread-1对应的编号是:5
当前线程是:Thread-3对应的编号是:4
当前线程是:Thread-3对应的编号是:5
当前线程是:Thread-2对应的编号是:1
当前线程是:Thread-2对应的编号是:2
当前线程是:Thread-2对应的编号是:3
当前线程是:Thread-2对应的编号是:4
当前线程是:Thread-2对应的编号是:5可以看出每个线程都产生出了5个数字。他们互不影响,线程运行的顺序可能有会不同,但是每个都是独立的,以当前线程作为键,值作为value,每个数字产生器都生成了独立的数字,达到了线程独立的效果