
前面,我们已经学习了ArrayList,并了解了fail-fast机制。这一章我们接着学习List的实现类——LinkedList
和学习ArrayList一样,我们先对LinkedList有个整体认识,然后再学习它的源码;最后再通过实例来学会使用LinkedList
内容包括:
- LinkedList介绍
- LinkedList数据结构
- LinkedList源码解析(基于JDK11.0.4)
- LinkedList遍历方式(整表遍历, 字表遍历, 并发遍历)
一. LinkedList介绍
LinkedList介绍
LinkedList 是一个继承于AbstractSequentialList的双向链表。因此它也可以被当作堆栈、队列或双端队列进行操作
LinkedList 实现 List 接口,能对它进行队列操作
LinkedList 实现 Deque 接口,能将LinkedList当作双端队列使用
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输
LinkedList 是线程不安全的(非同步的)
LinkedList构造函数
// 默认构造函数
public LinkedList() {
}
// 创建一个LinkedList,包括Collection中的全部元素
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}LinkedList的API
LinkedList的API
// 来自于Deque接口
E getFirst()
E getLast()
E removeFirst()
E removeLast()
void addFirst(E object)
void addLast(E object)
E peek()
E element()
E poll()
E remove()
boolean offer(E o)
boolean offerFirst(E e)
boolean offerLast(E e)
E peekFirst()
E peekLast()
E pollFirst()
E pollLast()
E pop()
void push(E e)
boolean removeFirstOccurrence(Object o)
boolean removeLastOccurrence(Object o)
Iterator<E> descendingIterator()
// 来自于List接口
boolean contains(Object object)
int size()
boolean add(E object)
boolean remove(Object o)
void add(int location, E object)
boolean addAll(Collection<? extends E> collection)
boolean addAll(int location, Collection<? extends E> collection)
void clear()
E get(int location)
E set(int index, E element)
void add(int index, E element)
E remove(int index)
int indexOf(Object object)
int lastIndexOf(Object object)
ListIterator<E> listIterator(int location)
<T> T[] toArray(T[] contents)
Object[] toArray()
// 重写Object的clone()方法[Cloneable接口]
Object clone()
// 来自于Collection接口(JDK 8新加入)
Spliterator<E> spliterator()AbstractSequentialList简介
在介绍LinkedList的源码之前,先介绍一下AbstractSequentialList。毕竟,LinkedList是AbstractSequentialList的子类
AbstractSequentialList 实现了get(int index)、set(int index, E element)、add(int index, E element) 和 remove(int index)这些方法(这些接口都是随机访问List的)
LinkedList是双向链表;既然它继承于AbstractSequentialList,就相当于已经实现了get(int index)这些接口
备注:
若需要通过AbstractSequentialList自己实现一个列表,只需要扩展此类,并提供 listIterator() 和 size() 方法的实现即可
若要实现不可修改的列表,则需要实现列表迭代器的 hasNext、next、hasPrevious、previous 和 index 方法即可
二. LinkedList数据结构
LinkedList的继承关系
java.lang.Object
↳ java.util.AbstractCollection<E>
↳ java.util.AbstractList<E>
↳ java.util.AbstractSequentialList<E>
↳ java.util.LinkedList<E>
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {}LinkedList与Collection关系如图:
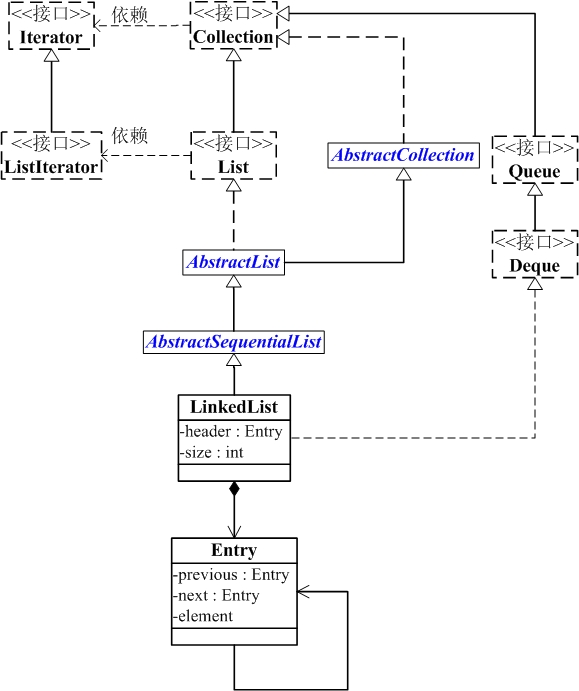
说明:
LinkedList的本质是双向链表:
- ① LinkedList继承于AbstractSequentialList,并且实现了Deque接口
② LinkedList包含两个重要的成员:header 和 size
header是双向链表的表头,它是双向链表节点所对应的类Node的实例。Node中包含成员变量: previous, next, element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值
size是双向链表中节点的个数
三. LinkedList源码解析(基于JDK11.0.4)
在阅读源码之前,我们先对LinkedList的整体实现进行大致说明:
LinkedList实际上是通过双向链表去实现的。既然是双向链表,那么它的顺序访问会非常高效,而随机访问效率比较低
既然LinkedList是通过双向链表的,但是它也实现了List接口(也就是说,它实现了get(int location)、remove(int location)等根据索引值来获取、删除节点的方法)
LinkedList是如何实现List的这些接口的,如何将双向链表和索引值联系起来的呢?
实际原理非常简单,它就是通过一个计数索引值来实现的, 例如:
当我们调用get(int location)时,链表节点所对应的类Entry的实例首先会比较location和双向链表长度的1/2;若前者大,则从链表头开始往后查找,直到location位置;否则,从链表末尾开始先前查找,直到location位置
好了,接下来开始阅读源码(只要理解双向链表,那么LinkedList的源码很容易理解的)
补充:
① 在JDK 11中链表节点所对应的类命名由Entry改为Node
② first和last这两个变量是LinkedList的成员变量,分别指向头结点和尾节点:
- 如果双端链表为空的时候,两个都必须为null
- 如果链表不为空,那么first的前驱节点一定是null,first的item一定不为null
- 同理,last的后继节点一定是null,last的item一定不为null
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
// LinkedList中元素个数
transient int size = 0;
// 双向链表的表头, 表头中也含有数据, 即不存在哨兵位(Pointer to first node)
// Node是个链表类数据结构(之前叫做Entry)
// Invariant: (first == null && last == null) || (first.prev == null && first.item != null)
transient Node<E> first;
// 双向链表的表尾(Pointer to last node)
// Invariant: (first == null && last == null) || (last.next == null && last.item != null)
transient Node<E> last;
// 默认构造函数:创建一个空的链表(Constructs an empty list)
public LinkedList() {}
// 包含集合的构造函数:创建一个包含集合内元素的LinkedList
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
// 在first节点的前面插入一个节点,插入完之后,更新first节点为新插入的节点,同时维持last节点的不变量(Links e as first element)
// 用于addFirst()方法
private void linkFirst(E e) {
// f来临时保存未插入前的first节点
final Node<E> f = first;
// 调用的node的构造函数新建一个值为e的新节点: 新节点的前驱节点为null,值为e,后继节点是f,也就是未插入前的first节点
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
// 如果f==null,那就说明插入之前,链表是空的, 则新插入的节点不仅是first节点还是last节点,所以我们要更新last节点的状态,也就是last现在要指向新插入的newNode
if (f == null)
last = newNode;
// 如果f!=null那么就说明last节点不变,但是要更新f的前驱节点为newNode,维持first节点的不变量
else
f.prev = newNode;
size++;
modCount++;
}
// 插入到last节点的后面(Links e as last element)
// 用于addLast(), add()等方法
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
// 在给定的节点前插入一个节点, 是linkFirst和linkLast方法的通用版
// 这里假设插入的这个节点的位置是非空的
// 用于add(int index, E element)方法
// Inserts element e before non-null Node succ
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
// 从头结点移除元素, 并返回移除节点的元素(Unlinks non-null first node f)
// 用于removeFirst(), poll()等方法
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // 将结点内部所有属性置null, 虽然Java用双向表辅助GC, 但这样更效率(help GC)
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
// 从尾结点移除元素, 并返回移除节点的元素(Unlinks non-null last node l)
// 用于removeLast(), pollLast()等方法
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // 将结点内部所有属性置null, 虽然Java用双向表辅助GC, 但这样更效率(help GC)
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
// 从链表中移除结点x, 是unlinkFirst()与unlinkLast()方法的通用版本(Unlinks non-null node x)
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
// 获取LinkedList的第一个元素
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
// 链表的表头header中即包含数据, 这里直接返回header中所包含的数据
return f.item;
}
// 获取LinkedList的最后一个元素
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
// 删除LinkedList的第一个元素
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
// 删除LinkedList的最后一个元素
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
// 将元素添加到LinkedList的起始位置
public void addFirst(E e) {
linkFirst(e);
}
// 将元素添加到LinkedList的结束位置
public void addLast(E e) {
linkLast(e);
}
// 判断LinkedList是否包含元素(o)
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
// 返回LinkedList的大小
public int size() {
return size;
}
// 将元素(E)添加到LinkedList中
public boolean add(E e) {
linkLast(e);
return true;
}
// 从LinkedList中删除元素(o), 使用equals()方法比较元素
// 从链表开始查找,如存在元素(o)则删除该元素并返回true, 否则,返回false
public boolean remove(Object o) {
if (o == null) {
// 若o为null的删除情况(LinkedList中允许包括null元素, 即node.element为null)
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
// 若o不为null的删除情况
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
// 从双向链表的末尾开始,将集合c中全部元素添加到双向链表中
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
// 从双向链表的index开始,将集合c中全部元素添加到双向链表中
public boolean addAll(int index, Collection<? extends E> c) {
// 检查index传参合法性
checkPositionIndex(index);
// 集合转为Object数组
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
// 设置当前要插入节点的后一个节点与前一个结点
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
// 将集合c全部插入双向链表末尾
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
// 清空双向链表
public void clear() {
// 从表头开始,逐个向后遍历;对遍历到的节点执行一下操作:
// ① 设置前一个节点为null
// ② 设置当前节点的内容为null
// ③ 设置后一个节点为新的当前节点
// 将结点全部的属性全部置为null虽然"没有特别必要", 但是:
// 主动将元素置null可以确保GC对结点数据的回收, 即使存在一个可达的迭代器
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
// 位置访问操作
// 返回LinkedList指定位置的元素
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 设置index位置对应的节点的值为element
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
// 在index前添加节点,且节点的值为element
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
// 删除index位置的节点
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
// 检查index合法性
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
// 检查index合法性
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
// 抛出IndexOutOfBoundsException异常时的错误信息(帮助调试)
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
// 检查index合法性, 不合法则抛出异常
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// 检查index合法性, 不合法则抛出异常
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// 获取双向链表中指定位置的节点
Node<E> node(int index) {
// assert isElementIndex(index);
// 若index < 双向链表长度的1/2,则从前先后查找;
// 否则,从后向前查找
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// 查找操作
// 从前向后查找,返回首个值为对象o(使用equals()方法)的节点对应的"索引"
// 不存在就返回-1
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
// 从后向前查找,返回最后一个值为对象o(使用equals()方法)的节点对应的"索引"
// 不存在就返回-1
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
// 队列操作
// 返回第一个节点中的元素(但不移除)
// 若LinkedList的大小为0,则返回null
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
// 返回第一个节点中的元素(不移除)
// 若LinkedList的大小为0,则抛出异常
public E element() {
return getFirst();
}
// 删除并返回第一个节点
// 若LinkedList的大小为0,则返回null
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
// 删除并返回第一个节点
// 若LinkedList的大小为0,则抛出异常
public E remove() {
return removeFirst();
}
// 将e添加双向链表末尾
public boolean offer(E e) {
return add(e);
}
// 将e添加双向链表开头
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
// 将e添加双向链表末尾
public boolean offerLast(E e) {
addLast(e);
return true;
}
// 返回第一个节点
// 若LinkedList的大小为0,则返回null
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
// 返回最后一个节点
// 若LinkedList的大小为0,则返回null
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
// 删除并返回第一个节点
// 若LinkedList的大小为0,则返回null
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
// 删除并返回最后一个节点
// 若LinkedList的大小为0,则返回null
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
// 将e插入到双向链表开头
public void push(E e) {
addFirst(e);
}
// 删除并返回第一个节点
public E pop() {
return removeFirst();
}
// 从LinkedList开始向后查找,删除第一个值为元素o(使用equals()方法)的节点
// 从链表开始查找,如存在节点的值为元素(o)的节点,则删除该节点
public boolean removeFirstOccurrence(Object o) {
return remove(o);
}
// 从LinkedList末尾向前查找,删除第一个值为元素o(使用equals()方法)的节点
// 从链表开始查找,如存在节点的值为元素(o)的节点,则删除该节点
public boolean removeLastOccurrence(Object o) {
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
// 返回index到末尾的全部节点对应的ListIterator对象(List迭代器)
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
// List迭代器
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned; // 上一次返回的节点
private Node<E> next; // 下一个节点
private int nextIndex; // 下一个节点对应的索引值
private int expectedModCount = modCount; // 期望的改变计数。用来实现fail-fast机制
// 构造函数, 从index位置开始进行迭代
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
// 是否存在下一个元素
public boolean hasNext() {
// 通过元素索引是否小于双向链表大小来判断是否达到最后
return nextIndex < size;
}
// 获取下一个元素
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
// next指向链表的下一个元素
next = next.next;
nextIndex++;
return lastReturned.item;
}
// 是否存在上一个元素
public boolean hasPrevious() {
// 通过元素索引是否大于0,来判断是否达到开头
return nextIndex > 0;
}
// 获取上一个元素
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
// next指向链表的上一个元素
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
// 获取下一个元素的索引
public int nextIndex() {
return nextIndex;
}
// 获取上一个元素的索引
public int previousIndex() {
return nextIndex - 1;
}
// 删除当前元素, 同时删除双向链表中的当前节点
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
// 设置当前节点为e
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
// 将e添加到当前节点的前面
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
// JDK 8后加入方法, 用于操作单次遍历(经常和Spliterator搭配使用)
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (modCount == expectedModCount && nextIndex < size) {
action.accept(next.item);
lastReturned = next;
next = next.next;
nextIndex++;
}
checkForComodification();
}
// 判断modCount和expectedModCount是否相等,来实现fail-fast机制
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
// 双向链表的节点所对应的数据结构
// 包含3部分:上一节点,下一节点,当前节点值
private static class Node<E> {
E item; // 当前节点所包含的值
Node<E> next; // 下一个节点
Node<E> prev; // 上一个节点
/**
* 链表节点的构造函数。
* 参数说明:
* element —— 节点所包含的数据
* next —— 下一个节点
* previous —— 上一个节点
*/
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
// JDK 6加入的: 返回以逆向顺序在此双端队列的元素上进行迭代的迭代器
public Iterator<E> descendingIterator() {
return new DescendingIterator();
}
// 通过listir.previous提供的降序迭代器
// Adapter to provide descending iterators via ListItr.previous
private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}
}
// 调用了super.clone()方法
@SuppressWarnings("unchecked")
private LinkedList<E> superClone() {
try {
return (LinkedList<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
// 克隆函数: 返回LinkedList的克隆对象
public Object clone() {
// 克隆一个LinkedList克隆对象
LinkedList<E> clone = superClone();
// // 新建LinkedList表头节点(初始化)
// Put clone into "virgin" state
clone.first = clone.last = null;
clone.size = 0;
clone.modCount = 0;
// 将链表中所有节点的数据都添加到克隆对象中
// (注意: 此处装填的是源集合中的元素, 并未拷贝!)
// Initialize clone with our elements
for (Node<E> x = first; x != null; x = x.next)
clone.add(x.item);
return clone;
}
// 返回LinkedList的Object[]数组
public Object[] toArray() {
// 新建Object[]数组
Object[] result = new Object[size];
int i = 0;
// 将链表中所有节点的数据都添加到Object[]数组中
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
return result;
}
// 返回LinkedList的模板数组
// 所谓模板数组,即可以将T设为任意的数据类型
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
// 若数组a的大小 < LinkedList的元素个数(意味着数组a不能容纳LinkedList中全部元素)
// 则新建一个T[]数组,T[]的大小为LinkedList大小,并将该T[]赋值给a
// 这也是为什么调用时可以直接使用a = list.toArray(new T[0])的原因!
if (a.length < size)
a = (T[])java.lang.reflect.Array.newInstance(
a.getClass().getComponentType(), size);
int i = 0;
Object[] result = a;
// 将链表中所有节点的数据都添加到数组a中
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
if (a.length > size)
a[size] = null;
return a;
}
// 序列化ID
private static final long serialVersionUID = 876323262645176354L;
// java.io.Serializable的写入函数
// 将LinkedList的"容量,所有的元素值"都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// 写入容量
s.writeInt(size);
// 将链表中所有节点的数据都写入到输出流中
for (Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item);
}
// java.io.Serializable的读取函数:根据写入方式反向读出
// 先将LinkedList的"容量"读出,然后将"所有的元素值"读出
@SuppressWarnings("unchecked")
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// 从输入流中读取容量
int size = s.readInt();
// 从输入流中将“所有的元素值”并逐个添加到链表中
for (int i = 0; i < size; i++)
linkLast((E)s.readObject());
}
// JDK 8添加的为了并行遍历元素而设计的一个迭代器Spliterator在LinkedList中的实现类LLSpliterator的实例
@Override
public Spliterator<E> spliterator() {
return new LLSpliterator<>(this, -1, 0);
}
// JDK 8添加的为了并行遍历元素而设计的一个迭代器Spliterator在LinkedList中的实现类
static final class LLSpliterator<E> implements Spliterator<E> {
static final int BATCH_UNIT = 1 << 10; // 批处理数组大小增量, 1024
static final int MAX_BATCH = 1 << 25; // 最大批处理数组大小, 33554432
final LinkedList<E> list; //不遍历情况下可以为null (null OK unless traversed)
Node<E> current; // 当前遍历节点, 未初始化时为null(current node; null until initialized)
int est; // size估计(尾节点索引),初始值为-1(size estimate; -1 until first needed)
int expectedModCount; // 期望的改变计数。用来实现fail-fast机制
int batch; // 拆分的批量大小
LLSpliterator(LinkedList<E> list, int est, int expectedModCount) {
this.list = list;
this.est = est; //尾节点,通常初始值为-1
this.expectedModCount = expectedModCount;
}
// 估算还剩下多少个元素需要遍历(size), 如果未初始化, 则强制初始化该类
final int getEst() {
int s; // 强制初始化(force initialization)
final LinkedList<E> lst;
if ((s = est) < 0) { // 如果est为-1
if ((lst = list) == null)
// 强制初始化est为0
s = est = 0;
else {
// 强制初始化expectedModCount, current, est等
expectedModCount = lst.modCount;
current = lst.first;
s = est = lst.size;
}
}
return s;
}
// 用于估算还剩下多少个元素需要遍历
public long estimateSize() { return (long) getEst(); }
// 对任务分割,返回一个新的Spliterator迭代器
public Spliterator<E> trySplit() {
Node<E> p;
int s = getEst();
if (s > 1 && (p = current) != null) {
int n = batch + BATCH_UNIT;
if (n > s)
n = s;
if (n > MAX_BATCH)
n = MAX_BATCH;
Object[] a = new Object[n];
int j = 0;
do { a[j++] = p.item; } while ((p = p.next) != null && j < n);
current = p;
batch = j;
est = s - j;
return Spliterators.spliterator(a, 0, j, Spliterator.ORDERED);
}
return null;
}
// 对每个剩余元素执行给定的动作,依次处理,直到所有元素已被处理或被异常终止
public void forEachRemaining(Consumer<? super E> action) {
Node<E> p; int n;
if (action == null) throw new NullPointerException();
if ((n = getEst()) > 0 && (p = current) != null) {
current = null;
est = 0;
do {
E e = p.item;
p = p.next;
action.accept(e);
} while (p != null && --n > 0);
}
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
}
// 单个对元素执行给定的动作,如果有剩下元素未处理返回true,否则返回false
public boolean tryAdvance(Consumer<? super E> action) {
Node<E> p;
if (action == null) throw new NullPointerException();
if (getEst() > 0 && (p = current) != null) {
--est;
E e = p.item;
current = p.next;
action.accept(e);
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
// 返回当前对象有哪些特征值
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}
}
总结:
① LinkedList 实际上是通过双向链表去实现的
- 它包含一个非常重要的内部类:Node(JDK 8之前命名为Entry): Entry是双向链表节点所对应的数据结构,它包括的属性有:当前节点所包含的值(element),上一个节点(prev),下一个节点(next)
- ② 从LinkedList的实现方式中可以发现,它不存在容量不足的问题
③ LinkedList的克隆函数clone(),通过源码可知是将全部元素克隆到一个新的LinkedList对象中(对于对象本身来说是浅复制)
例如:
public class Test { public static void main(String[] args) { Test test = new Test(); LinkedList<Student> list = new LinkedList<>(); list.add(test.new Student("Test", 5)); list.add(test.new Student("Test2", 10)); List<Student> clonedList = (List<Student>) list.clone(); clonedList.get(0).setAge(100); System.out.println(list); // [Student{name='Test', age=100}, Student{name='Test2', age=10}] System.out.println(clonedList); // [Student{name='Test', age=100}, Student{name='Test2', age=10}] } class Student { private String name; private int age; public Student(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}'; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } }在list中创建两个Student元素, 克隆list为clonedList, 并在clonedList中修改元素, 则原list中元素也被修改
所以想要深复制一个LinkedList还是写代码一个一个复制加入吧!
- ④ LinkedList实现了java.io.Serializable: 当写入到输出流时,先写入容量,再依次写入每一个节点保护的值;当读出输入流时,先读取容量,再依次读取每一个元素
由于LinkedList实现了Deque,而Deque接口定义了在双端队列两端访问元素的方法: 提供插入、移除和检查元素的方法
每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)
总结起来如下表格:
抛出异常(头部操作) null值(头部操作) 抛出异常(尾部操作) null值(尾部操作) 插入 addFirst(e) offerFirst(e) addLast(e) offerLast(e) 移除 removeFirst() pollFirst() removeLast() pollLast() 检查 getFirst() peekFirst() getLast() peekLast()
LinkedList可以作为FIFO(先进先出)的队列,作为FIFO的队列时,下表的方法等价:
队列方法 等效方法 add(e) addLast(e) offer(e) offerLast(e) remove() removeFirst() poll() pollFirst() element() getFirst() peek() peekFirst()
LinkedList可以作为LIFO(后进先出)的栈,作为LIFO的栈时,下表的方法等价:
栈方法 等效方法 push(e) addFirst(e) pop() removeFirst() peek() peekFirst()
四. LinkedList遍历方式
LinkedList整表遍历
LinkedList支持多种整表遍历方式, 但不建议采用随机访问的方式去遍历LinkedList,而采用逐个遍历的方式
① 通过迭代器遍历, 即通过Iterator去遍历
for (Iterator iter = list.iterator(); iter.hasNext();)
iter.next();② 通过快速随机访问遍历LinkedList
for (int i = 0, size = list.size(); i < size; i++) {
list.get(i);
}③ 通过forEach语法(内部还是迭代器)来遍历LinkedList
for (Integer integ:list)
;④ 通过pollFirst()来遍历
while(list.pollFirst() != null)
;⑤ 通过pollLast()来遍历
while(list.pollLast() != null)
;⑥ 通过removeFirst()来遍历
try {
while(list.removeFirst() != null)
;
} catch (NoSuchElementException e) {
}⑦ 通过removeLast()来遍历
try {
while(list.removeLast() != null)
;
} catch (NoSuchElementException e) {
}测试这些遍历方式效率的代码如下:
/**
* 测试LinkedList的几种遍历方式和效率
*
* @author zk
*/
public class Test {
public static void main(String[] args) {
LinkedList<Integer> list = getLinkedList();
// 通过Iterator遍历LinkedList
iteratorLinkedListThruIterator(list);
// 通过快速随机访问遍历LinkedList
iteratorLinkedListThruForeach(list);
// 通过for循环的变种来访问遍历LinkedList
iteratorThroughFor2(list);
// 通过PollFirst()遍历LinkedList
iteratorThroughPollFirst(list);
// 通过PollLast()遍历LinkedList
iteratorThroughPollLast(list);
// 通过removeFirst()遍历LinkedList
iteratorThroughRemoveFirst(list);
// 通过removeLast()遍历LinkedList
iteratorThroughRemoveLast(list);
}
private static LinkedList<Integer> getLinkedList() {
LinkedList<Integer> list = new LinkedList<>();
for (int i = 0; i < 100000; i++) {
list.addLast(i);
}
return list;
}
/**
* 通过快迭代器遍历LinkedList
*/
private static void iteratorLinkedListThruIterator(LinkedList<Integer> list) {
if (list == null) {
return;
}
// 记录开始时间
long start = System.currentTimeMillis();
for (Iterator iter = list.iterator(); iter.hasNext(); ) {
iter.next();
}
// 记录结束时间
long end = System.currentTimeMillis();
long interval = end - start;
System.out.println("iterator LinkedList by Iterator:" + interval + " ms");
}
/**
* 通过快速随机访问遍历LinkedList
*/
private static void iteratorLinkedListThruForeach(LinkedList<Integer> list) {
if (list == null) {
return;
}
// 记录开始时间
long start = System.currentTimeMillis();
int size = list.size();
for (int i = 0; i < size; i++) {
list.get(i);
}
// 记录结束时间
long end = System.currentTimeMillis();
long interval = end - start;
System.out.println("iterator LinkedList by forEach:" + interval + " ms");
}
/**
* 通过forEach循环来遍历LinkedList
*/
private static void iteratorThroughFor2(LinkedList<Integer> list) {
if (list == null) {
return;
}
// 记录开始时间
long start = System.currentTimeMillis();
for (Integer integ : list) {
;
}
// 记录结束时间
long end = System.currentTimeMillis();
long interval = end - start;
System.out.println("iteratorThroughFor2:" + interval + " ms");
}
/**
* 通过pollFirst()来遍历LinkedList
*/
private static void iteratorThroughPollFirst(LinkedList<Integer> list) {
if (list == null) {
return;
}
// 记录开始时间
long start = System.currentTimeMillis();
while (list.pollFirst() != null) {
;
}
// 记录结束时间
long end = System.currentTimeMillis();
long interval = end - start;
System.out.println("iterator by PollFirst:" + interval + " ms");
}
/**
* 通过pollLast()来遍历LinkedList
*/
private static void iteratorThroughPollLast(LinkedList<Integer> list) {
if (list == null) {
return;
}
// 记录开始时间
long start = System.currentTimeMillis();
while (list.pollLast() != null) {
;
}
// 记录结束时间
long end = System.currentTimeMillis();
long interval = end - start;
System.out.println("iterator by PollLast:" + interval + " ms");
}
/**
* 通过removeFirst()来遍历LinkedList
*/
private static void iteratorThroughRemoveFirst(LinkedList<Integer> list) {
if (list == null) {
return;
}
// 记录开始时间
long start = System.currentTimeMillis();
try {
while (list.removeFirst() != null) {
;
}
} catch (NoSuchElementException e) {
}
// 记录结束时间
long end = System.currentTimeMillis();
long interval = end - start;
System.out.println("iterator by RemoveFirst:" + interval + " ms");
}
/**
* 通过removeLast()来遍历LinkedList
*/
private static void iteratorThroughRemoveLast(LinkedList<Integer> list) {
if (list == null) {
return;
}
// 记录开始时间
long start = System.currentTimeMillis();
try {
while (list.removeLast() != null) {
;
}
} catch (NoSuchElementException e) {
}
// 记录结束时间
long end = System.currentTimeMillis();
long interval = end - start;
System.out.println("iterator by RemoveLast:" + interval + " ms");
}
}执行结果:
iterator LinkedList by Iterator:6 ms
iterator LinkedList by forEach:3333 ms
iteratorThroughFor2:5 ms
iterator by PollFirst:3 ms
iterator by PollLast:0 ms
iterator by RemoveFirst:0 ms
iterator by RemoveLast:0 ms
结论:
- 使用removeFist()或removeLast()效率最高, 但它们会删除原始数据;
- 若单纯只读取,而不删除,应该使用forEach语法(Iterator)遍历方式;
无论如何,千万不要通过随机访问去遍历LinkedList
遍历子列表
① 正序遍历子列表
LinkedList中提供了public ListIterator<E> listIterator(int index)方法, 可以指定返回从某个index开始的迭代器:
LinkedList<Integer> list = new LinkedList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
Iterator<Integer> subList = list.listIterator(5);
while (subList.hasNext()) {
System.out.println(subList.next());
}
补充:
① 也可以使用List接口中定义的
public List<E> subList(int fromIndex, int toIndex)方法:LinkedList<Integer> list = new LinkedList<>(); for (int i = 0; i < 10; i++) { list.add(i); } List<Integer> subList = list.subList(5, 8); subList.set(2, 100); System.out.println(subList); // [5, 6, 100] System.out.println(list); // [0, 1, 2, 3, 4, 5, 6, 100, 8, 9]但是这个方法实际上继承自AbstractList的实现, LinkedList中并未重写, 且对于subList的修改会影响原list!
② 反序遍历子列表
LinkedList中还提供了DescendingIterator类, 用于反序遍历列表(但不可指定从某个index开始)
使用descendingIterator()方法返回一个反序遍历的Iterator:
LinkedList<Integer> list = new LinkedList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
Iterator<Integer> subList = list.descendingIterator();
while (subList.hasNext()) {
System.out.println(subList.next()); // 9, 8, 7, ..., 0
}使用Spliterator并发遍历
与ArrayList类似, 在LinkedList中也存在一个实现了Spliterator接口的内部类: LLSpliterator 用于并发遍历整个表以提高性能, 使用方法与ArrayList类似
例如: 创建一个长度为100的list,如果下标能被10整除,则该位置数值跟下标相同,否则值为aaaa。然后多线程遍历list,取出list中的数值(字符串aaaa不要)进行累加求和
package top.jasonkayzk;
import java.util.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.regex.Pattern;
public class Test {
static List<String> list;
static AtomicInteger count;
public static void main(String[] args) throws InterruptedException {
// 初始化List, 并获得spliterator
list = new LinkedList<>();
for (int i = 1; i <= 100; i++) {
if (i % 10 == 0) {
list.add(Integer.toString(i));
} else {
list.add("aaaa");
}
}
Spliterator<String> spliterator = list.spliterator();
// 求和结果
count = new AtomicInteger(0);
Spliterator<String> s1 = spliterator.trySplit();
Spliterator<String> s2 = spliterator.trySplit();
Thread main = new Thread(new Task(spliterator));
Thread t1 = new Thread(new Task(s1));
Thread t2 = new Thread(new Task(s2));
main.start();
t1.start();
t2.start();
t1.join();
t2.join();
main.join();
System.out.println(count);
}
// 判断字符串是数字
public static boolean isInteger(String str) {
Pattern pattern = Pattern.compile("^[-+]?[\\d]*$");
return pattern.matcher(str).matches();
}
static class Task implements Runnable {
private Spliterator<String> spliterator;
public Task(Spliterator<String> spliterator) {
this.spliterator = spliterator;
}
@Override
public void run() {
String threadName = Thread.currentThread().getName();
System.out.println("线程" + threadName + "开始运行-----");
spliterator.forEachRemaining(x -> {
if (isInteger(x)) {
count.addAndGet(Integer.parseInt(x));
System.out.println("数值:" + x + "------" + threadName);
}
});
System.out.println("线程" + threadName + "运行结束-----");
}
}
}以上代码与之前ArrayList中的代码几乎相同(只是在创建List时使用的是new LinkedList<>()而已)
执行结果如下:
线程Thread-1开始运行-----
线程Thread-2开始运行-----
线程Thread-0开始运行-----
线程Thread-0运行结束-----
Exception in thread "Thread-2" java.lang.NullPointerException
at top.jasonkayzk.Test$Task.run(Test.java:65)
at java.base/java.lang.Thread.run(Thread.java:834)
数值:10------Thread-1
数值:20------Thread-1
数值:30------Thread-1
数值:40------Thread-1
数值:50------Thread-1
数值:60------Thread-1
数值:70------Thread-1
数值:80------Thread-1
数值:90------Thread-1
数值:100------Thread-1
线程Thread-1运行结束-----
550结果是正确的, 但是爆出了NPE的错误!
但是将100增大, 比如到10000, 则不会报错了!
原因在于:
LLSpliterator和在ArrayList中实现的ArrayListSpliterator的实现方式还是有所区别的
在LLSpliterator中定义了BATCH_UNIT和batch变量:
static final int BATCH_UNIT = 1 << 10; // 批处理数组大小增量, 1024
static final int MAX_BATCH = 1 << 25; // 最大批处理数组大小, 33554432
int est; // size估计(尾节点索引),初始值为-1(size estimate; -1 until first needed)
int expectedModCount; // 期望的改变计数。用来实现fail-fast机制
int batch; // 拆分的批量大小而在源码的trySplit()方法中可以看到在LLSpliterator中是以batch(或者说是j)来进行拆分的:
public Spliterator<E> trySplit() {
Node<E> p;
int s = getEst();
if (s > 1 && (p = current) != null) {
int n = batch + BATCH_UNIT;
if (n > s)
n = s;
if (n > MAX_BATCH)
n = MAX_BATCH;
Object[] a = new Object[n];
int j = 0;
do { a[j++] = p.item; } while ((p = p.next) != null && j < n);
current = p;
batch = j;
est = s - j;
return Spliterators.spliterator(a, 0, j, Spliterator.ORDERED);
}
return null;
}并且这个batch固定等于: batch + BATCH_UNIT, 而batch只能被初始化为0(没找到setter方法), 所以batch只能固定为1024!
说明: 在LLSpliterator中
① batch限定了每次差分的大小, 而batch并未通过构造函数或者Setter暴露, 所以只能为: BATCH_UNIT(1024), 即每一批次固定为1024个元素
② MAX_BATCH规定了可处理的总批数, 所以LLSpliterator可处理的最多元素是: MAX_BATCH x BATCH_UNIT
综上, 也就不难得出, 为什么当list长度为100时会报错了: 因为开了四个线程, 但是因为每一批固定为1024个, 所以其实另外三个线程都被分为了null, 所以报出NPE
总结: ArrayListSpliterator和LLSpliterator的底层实现还是不同的
我个人觉得主要是因为LinkedList的随机访问能力远不如ArrayList, 所以差分多个其实性能远远不如ArrayList好, 所以Java官方才这样设计的, 毕竟你拆分LinkedList时, 基本上已经遍历了整个链表了
所以使用Spliterator多线程并发操作List的时候, 一定要选择ArrayList!