
学完ArrayList和LinkedList之后,我们接着学习Vector. 学习方式还是和之前一样,先对Vector有个整体认识,然后再学习它的源码;最后再通过实例来学会使用它:
- Vector介绍
- Vector数据结构
- Vector源码解析(基于JDK11.0.4)
- Vector遍历方式
- Vector示例
一. Vector介绍
Vector介绍
Vector 是矢量队列,它是JDK1.0版本就添加的类(而实际上在JDK 1.2之后就被淘汰了)
Vector 继承于AbstractList,实现了List接口. 所以,它是一个队列,支持相关的添加、删除、修改、遍历等功能
Vector 实现了RandmoAccess接口,可以通过元素的序号快速获取元素对象, 即提供了随机访问功能(RandmoAccess是java中用来被List实现,为List提供快速访问功能的)
Vector 实现了Cloneable接口,即实现clone()函数。它能被克隆
和ArrayList不同,Vector中的操作是线程安全的
Vector的构造函数
Vector共有4个构造函数
// 默认构造函数, 可知默认大小与ArrayList相同, 都为10
public Vector() {
this(10);
}
// initialCapacity指定Vector初始化容量, 当由于增加数据导致容量增加时,默认每次容量会增加一倍
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
// initialCapacity指定Vector初始化容量, capacityIncrement是每次Vector容量增加时的增量值
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity]; // Vector内部由数组实现
this.capacityIncrement = capacityIncrement;
}
// 创建一个包含collection的Vector, 此时默认每次容量会增加一倍
public Vector(Collection<? extends E> c) {
elementData = c.toArray();
elementCount = elementData.length;
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}Vector的API
// 来自于List接口
synchronized int size()
synchronized boolean isEmpty()
boolean contains(Object object)
int indexOf(Object object)
synchronized int lastIndexOf(Object object)
synchronized Object[] toArray()
synchronized <T> T[] toArray(T[] contents)
synchronized E get(int index)
synchronized E set(int location, E object)
synchronized boolean add(E object)
boolean remove(Object object)
void add(int location, E object)
synchronized E remove(int location)
void clear()
synchronized boolean containsAll(Collection<?> collection)
boolean addAll(Collection<? extends E> collection)
boolean removeAll(Collection<?> collection)
boolean retainAll(Collection<?> collection)
synchronized boolean addAll(int location, Collection<? extends E> collection)
synchronized boolean equals(Object object)
synchronized int hashCode()
synchronized List<E> subList(int start, int end)
synchronized ListIterator<E> listIterator(int index)
synchronized ListIterator<E> listIterator()
synchronized Iterator<E> iterator()
// 重写Object的clone()
synchronized Object clone()
// 来自于Collection接口(JDK 8后加入)
boolean removeIf(Predicate<? super E> filter)
Spliterator<E> spliterator()
// 重写AbstractCollection的toString()
synchronized String toString()
// 重写Iterable的forEach()
synchronized void forEach(Consumer<? super E> action)
// 来自于List接口
synchronized void replaceAll(UnaryOperator<E> operator)
synchronized void sort(Comparator<? super E> c)
// Vector中定义的方法
synchronized void copyInto(Object[] elements)=
synchronized void trimToSize()
synchronized void ensureCapacity(int minimumCapacity)
synchronized void setSize(int length)
synchronized int capacity()
Enumeration<E> elements()
synchronized int indexOf(Object object, int location)
synchronized int lastIndexOf(Object object, int location)
synchronized E elementAt(int location)
synchronized E firstElement()
synchronized E lastElement()
synchronized void setElementAt(E object, int location)
synchronized void removeElementAt(int location)
synchronized void insertElementAt(E object, int location)
synchronized void addElement(E object)
synchronized boolean removeElement(Object object)
synchronized void removeAllElements()
总结:
在Vector中所有方法都被synchronized关键字同步了(即使某些方法没有在方法签名上标注, 但是其内部也都是调用的同步方法, 或者使用的是synchronized代码块)
这是一个在并发情况下效率相当低的行为, 因为synchronized是一个效率相当低的悲观锁, 所以才会在JDK 1.2就被淘汰了!
二. Vector数据结构
Vector的继承关系
java.lang.Object
↳ java.util.AbstractCollection<E>
↳ java.util.AbstractList<E>
↳ java.util.Vector<E>
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {}Vector与Collection关系如下图:
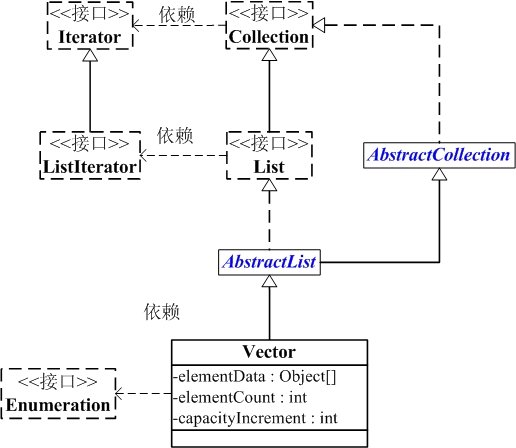
Vector的数据结构和ArrayList差不多,它包含了3个成员变量:elementData , elementCount, capacityIncrement
① elementData 是”Object[]类型的数组”,它保存了添加到Vector中的元素。elementData是个动态数组,如果初始化Vector时,没指定动态数组的大小,则使用默认大小10
② elementCount 是动态数组的实际大小(实际存储元素个数)
③ capacityIncrement 是动态数组的增长系数。如果在创建Vector时,指定了capacityIncrement的大小;则每次当Vector中动态数组容量增加时,增加的大小都是capacityIncrement(默认为增大一倍)
小贴士: 具体的增长方式,参考源码分析中的newCapacity()方法
三. Vector源码解析(基于JDK11.0.4)
为了更了解Vector的原理,下面对Vector源码代码作出分析
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// 保存Vector中数据的数组
protected Object[] elementData;
// 实际数据的数量
protected int elementCount;
// 容量增长系数
protected int capacityIncrement;
// Vector的序列版本号
private static final long serialVersionUID = -2767605614048989439L;
// 指定Vector"容量大小"和"增长系数"的构造函数
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
// 指定Vector容量大小的构造函数
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
// Vector构造函数。默认容量是10
public Vector() {
this(10);
}
// 指定集合的Vector构造函数
public Vector(Collection<? extends E> c) {
// 获取集合c的数组,并将其赋值给elementData
elementData = c.toArray();
// 设置数组长度
elementCount = elementData.length;
// defend against c.toArray (incorrectly) not returning Object[]
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
// 将数组Vector的全部元素都拷贝到数组anArray中
public synchronized void copyInto(Object[] anArray) {
System.arraycopy(elementData, 0, anArray, 0, elementCount);
}
// 将当前容量值设为 =实际元素个数
public synchronized void trimToSize() {
modCount++;
int oldCapacity = elementData.length;
if (elementCount < oldCapacity) {
elementData = Arrays.copyOf(elementData, elementCount);
}
}
// 检查并确保Vector的容量足够
public synchronized void ensureCapacity(int minCapacity) {
if (minCapacity > 0) {
modCount++;
// 当Vector的容量不足以容纳当前的全部元素,增加容量大小
if (minCapacity > elementData.length)
grow(minCapacity);
}
}
// 可分配的最大空间(The maximum size of array to allocate)
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 根据minCapacity给存储数组扩容
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}
// 给存储数组扩容一个单位
private Object[] grow() {
return grow(elementCount + 1);
}
// 根据minCapacity计算扩容后数组大小
private int newCapacity(int minCapacity) {
// 容易计算溢出的代码区(overflow-conscious code)
int oldCapacity = elementData.length;
// 若容量增量系数>0(即capacityIncrement>0),则将容量增大当capacityIncrement
// 否则,将容量增大一倍
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity <= 0) {
if (minCapacity < 0) // 发生了计算溢出(overflow)
throw new OutOfMemoryError();
return minCapacity;
}
// 新的容量小于等于 Integer.MAX_VALUE - 8 则直接返回,否则基于预期容量返回 Integer.MAX_VALUE - 8 或 Integer.MAX_VALUE
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
// 基于预期容量返回 Integer.MAX_VALUE - 8 或 Integer.MAX_VALUE
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
// 设置容量值为 newSize
public synchronized void setSize(int newSize) {
modCount++;
// 若 "newSize 大于 Vector容量",则调整Vector的大小
if (newSize > elementData.length)
grow(newSize);
final Object[] es = elementData;
// 若 "newSize 小于/等于 Vector容量",则将newSize位置开始的元素都设置为null
for (int to = elementCount, i = newSize; i < to; i++)
es[i] = null;
elementCount = newSize;
}
// 返回Vector的总的容量
public synchronized int capacity() {
return elementData.length;
}
// 返回Vector的实际大小,即Vector中元素个数
public synchronized int size() {
return elementCount;
}
// 判断Vector是否为空
public synchronized boolean isEmpty() {
return elementCount == 0;
}
// 返回Vector中与全部元素对应的Enumeration
public Enumeration<E> elements() {
// 通过匿名类实现Enumeration
return new Enumeration<E>() {
int count = 0;
// 是否存在下一个元素
public boolean hasMoreElements() {
return count < elementCount;
}
// 获取下一个元素
public E nextElement() {
synchronized (Vector.this) {
if (count < elementCount) {
return elementData(count++);
}
}
throw new NoSuchElementException("Vector Enumeration");
}
};
}
// 返回Vector中是否包含对象o(使用equals()方法判断)
public boolean contains(Object o) {
return indexOf(o, 0) >= 0;
}
// 从开始位置开始向后查找对象o(使用equals()方法判断)
// 若找到,则返回元素的索引值;否则,返回-1
public int indexOf(Object o) {
return indexOf(o, 0);
}
// 从index位置开始向后查找对象o(使用equals()方法判断)
// 若找到,则返回元素的索引值;否则,返回-1
public synchronized int indexOf(Object o, int index) {
// 若查找元素为null,则正向找出null元素,并返回它对应的序号
if (o == null) {
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null)
return i;
} else {
// 若查找元素不为null,则正向找出该元素,并返回它对应的序号
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
// 从后向前查找元素o, 并返回元素的索引
public synchronized int lastIndexOf(Object o) {
return lastIndexOf(o, elementCount-1);
}
// 从后向前查找元素o, 开始位置是"从前向后的第index个数"
// 若找到,则返回元素的“索引值”;否则,返回-1
public synchronized int lastIndexOf(Object o, int index) {
if (index >= elementCount)
throw new IndexOutOfBoundsException(index + " >= "+ elementCount);
if (o == null) {
// 若查找元素为null,则反向找出null元素,并返回它对应的序号
for (int i = index; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
// 若查找元素不为null,则反向找出该元素,并返回它对应的序号
for (int i = index; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
// 返回Vector中index位置的元素, 若index越界,则抛出异常
public synchronized E elementAt(int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
return elementData(index);
}
// 获取Vector中的第一个元素
// 若失败,则抛出异常
public synchronized E firstElement() {
if (elementCount == 0) {
throw new NoSuchElementException();
}
return elementData(0);
}
// 获取Vector中的最后一个元素
// 若失败,则抛出异常
public synchronized E lastElement() {
if (elementCount == 0) {
throw new NoSuchElementException();
}
return elementData(elementCount - 1);
}
// 设置index位置的元素值为obj
public synchronized void setElementAt(E obj, int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
elementData[index] = obj;
}
// 删除index位置的元素
public synchronized void removeElementAt(int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
int j = elementCount - index - 1;
if (j > 0) {
System.arraycopy(elementData, index + 1, elementData, index, j);
}
modCount++;
elementCount--;
elementData[elementCount] = null; // GC优化(to let gc do its work)
}
// 在index位置处插入元素(obj)
public synchronized void insertElementAt(E obj, int index) {
if (index > elementCount) {
throw new ArrayIndexOutOfBoundsException(index
+ " > " + elementCount);
}
modCount++;
final int s = elementCount;
Object[] elementData = this.elementData;
if (s == elementData.length)
elementData = grow();
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
elementData[index] = obj;
elementCount = s + 1;
}
// 将“元素obj”添加到Vector末尾
public synchronized void addElement(E obj) {
modCount++;
add(obj, elementData, elementCount);
}
// 在Vector中查找并删除元素obj
// 成功,返回true;否则,返回false
public synchronized boolean removeElement(Object obj) {
modCount++;
int i = indexOf(obj);
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
// 删除Vector中的全部元素
public synchronized void removeAllElements() {
final Object[] es = elementData;
// 将Vector中的全部元素设为null
for (int to = elementCount, i = elementCount = 0; i < to; i++)
es[i] = null;
modCount++;
}
// 克隆函数
public synchronized Object clone() {
try {
@SuppressWarnings("unchecked")
Vector<E> v = (Vector<E>) super.clone();
v.elementData = Arrays.copyOf(elementData, elementCount);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
// 返回Object数组
public synchronized Object[] toArray() {
return Arrays.copyOf(elementData, elementCount);
}
// 返回Vector的模板数组。所谓模板数组,即可以将T设为任意的数据类型
@SuppressWarnings("unchecked")
public synchronized <T> T[] toArray(T[] a) {
// 若数组a的大小 < Vector的元素个数;
// 则新建一个T[]数组,数组大小是“Vector的元素个数”,并将“Vector”全部拷贝到新数组中
if (a.length < elementCount)
return (T[]) Arrays.copyOf(elementData, elementCount, a.getClass());
// 若数组a的大小 >= Vector的元素个数;
// 则将Vector的全部元素都拷贝到数组a中
System.arraycopy(elementData, 0, a, 0, elementCount);
// 数组a中多余元素置null
if (a.length > elementCount)
a[elementCount] = null;
return a;
}
// 位置获取操作
// 获取elementData数组中第index个元素
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
// 静态方法: 获取数组es中第index个元素
@SuppressWarnings("unchecked")
static <E> E elementAt(Object[] es, int index) {
return (E) es[index];
}
// 获取index位置的元素
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
// 设置index位置的值为element。并返回index位置的原始值
public synchronized E set(int index, E element) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
// 本工具方法是从add(E)方法中拆分出来的,旨在保持方法的字节码小于35字节
// (-XX:MaxInlineSize默认值), 此举有助于帮助C1编译器循环调用add(E)方法时做热点代码的内联优化
// This helper method split out from add(E) to keep method
// bytecode size under 35 (the -XX:MaxInlineSize default value),
// which helps when add(E) is called in a C1-compiled loop.
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
elementCount = s + 1;
}
// 将“元素e”添加到Vector最后
public synchronized boolean add(E e) {
modCount++;
add(e, elementData, elementCount);
return true;
}
// 删除Vector中的元素o
public boolean remove(Object o) {
return removeElement(o);
}
// 在index位置添加元素element
public void add(int index, E element) {
insertElementAt(element, index);
}
// 删除index位置的元素,并返回index位置的原始值
public synchronized E remove(int index) {
modCount++;
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
int numMoved = elementCount - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--elementCount] = null; // 优化GC(Let gc do its work)
return oldValue;
}
// 清空Vector
public void clear() {
removeAllElements();
}
// 块操作(Bulk Operations)
// 返回Vector是否包含集合c
public synchronized boolean containsAll(Collection<?> c) {
return super.containsAll(c);
}
// 将集合c添加到Vector中
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
// Vector对此方法做了优化, JDK 8之前的方法整个被标注为synchronized
synchronized (this) {
Object[] elementData = this.elementData;
final int s = elementCount;
if (numNew > elementData.length - s)
elementData = grow(s + numNew);
// 将集合c的全部元素拷贝到数组elementData中
System.arraycopy(a, 0, elementData, s, numNew);
elementCount = s + numNew;
return true;
}
}
// 删除集合c的全部元素
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
return bulkRemove(e -> c.contains(e));
}
// 删除非集合c中的元素
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return bulkRemove(e -> !c.contains(e));
}
// JDK 8中添加的方法, 根据Predicate(Lambda表达式)给出的boolean条件, 删除满足条件的元素
// 多用在Stream操作中
@Override
public boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
return bulkRemove(filter);
}
/* 一些位操作实现(A tiny bit set implementation) */
// 用在了removeIf()方法中, 作用是初始化一个数组, 数组长度是按照 (n - 1) >> 6 + 1 的逻辑来得到的
// >> 是算术位移,简单的来说就是将数字除以 2 的 n 次方,>> 6 就是除以 2 的 6 次方,即除以 64, 因此 nBits 方法会以 64 为单位来收缩,并返回收缩后长度的数组
private static long[] nBits(int n) {
return new long[((n - 1) >> 6) + 1];
}
// 同样用在removeIf()方法中, 作用就是将 i 转换为 2 的 i 次方数字后,进行合并,而合并的结果其实是将第 i 位置为 1, 其余位为零(位图索引)
// 在removeIf()方法中: deathRow 是一个「位图」(Bitmap) 的数据结构
private static void setBit(long[] bits, int i) {
bits[i >> 6] |= 1L << i;
}
// 同样用在removeIf()方法中: isClear 会按照输入去看数组中元素的第 i 位是否被置为 1,如果 没有 被置为 1 ,则返回 true(判断位图索引)
private static boolean isClear(long[] bits, int i) {
return (bits[i >> 6] & (1L << i)) == 0;
}
// JDK 8后新加入, 用于传入给定的Predicate(正则表达式), 来删除满足条件的元素
private synchronized boolean bulkRemove(Predicate<? super E> filter) {
int expectedModCount = modCount;
final Object[] es = elementData;
final int end = elementCount;
int i;
// 从头开始略过不满足断言的元素,找到第一个需要移除的元素索引(Optimize for initial run of survivors)
for (i = 0; i < end && !filter.test(elementAt(es, i)); i++)
;
// 遍历的同时, 仍然允许以可重入方式访问集合for、read(但写入程序仍然获得CME);
// 第一次遍历查找要删除的元素,第二次遍历以物理方式删除[整个过程记录使用deathRow位图的形式存放匹配成功的元素的偏移量]
// 原文: Tolerate predicates that reentrantly access the collection for, read (but writers still get CME), so traverse once to find elements to delete, a second pass to physically expunge
if (i < end) {
final int beg = i;
final long[] deathRow = nBits(end - beg);
deathRow[0] = 1L; // 初始化位图
for (i = beg + 1; i < end; i++) // 第一次遍历查找要删除的元素
if (filter.test(elementAt(es, i)))
setBit(deathRow, i - beg);
if (modCount != expectedModCount) // 判断多线程是否修改
throw new ConcurrentModificationException();
modCount++;
int w = beg;
for (i = beg; i < end; i++) // 第二次遍历以物理方式删除
if (isClear(deathRow, i - beg))
es[w++] = es[i];
for (i = elementCount = w; i < end; i++)
es[i] = null;
return true;
} else {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return false;
}
}
// 从index位置开始,将集合c添加到Vector中
public synchronized boolean addAll(int index, Collection<? extends E> c) {
if (index < 0 || index > elementCount)
throw new ArrayIndexOutOfBoundsException(index);
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
Object[] elementData = this.elementData;
final int s = elementCount;
if (numNew > elementData.length - s)
elementData = grow(s + numNew);
int numMoved = s - index;
if (numMoved > 0)
System.arraycopy(elementData, index,
elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
elementCount = s + numNew;
return true;
}
// 返回两个Vector对象是否相等(直接比较的是内存地址!)
public synchronized boolean equals(Object o) {
return super.equals(o);
}
// 计算Vector的哈希值
public synchronized int hashCode() {
return super.hashCode();
}
// 调用父类的toString()
public synchronized String toString() {
return super.toString();
}
// 获取Vector中fromIndex(包括)到toIndex(不包括)的子集
public synchronized List<E> subList(int fromIndex, int toIndex) {
return Collections.synchronizedList(super.subList(fromIndex, toIndex),
this);
}
// 删除Vector中fromIndex到toIndex(不包括)的元素
protected synchronized void removeRange(int fromIndex, int toIndex) {
modCount++;
shiftTailOverGap(elementData, fromIndex, toIndex);
}
// 将lo -> hi移到末尾并置为null, 后面的元素前移并填补上(Erases the gap from lo to hi, by sliding down following elements)
// 主要用在removeRange(), batchRemove()等大范围删除方法中
private void shiftTailOverGap(Object[] es, int lo, int hi) {
System.arraycopy(es, hi, es, lo, elementCount - hi);Vector
for (int to = elementCount, i = (elementCount -= hi - lo); i < to; i++)
es[i] = null;
}
// 反序列化
private void readObject(ObjectInputStream in)
throws IOException, ClassNotFoundException {
ObjectInputStream.GetField gfields = in.readFields();
int count = gfields.get("elementCount", 0);
Object[] data = (Object[])gfields.get("elementData", null);
if (count < 0 || data == null || count > data.length) {
throw new StreamCorruptedException("Inconsistent vector internals");
}
elementCount = count;
elementData = data.clone();
}
// 序列化当前对象
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
final java.io.ObjectOutputStream.PutField fields = s.putFields();
final Object[] data;
synchronized (this) {
fields.put("capacityIncrement", capacityIncrement);
fields.put("elementCount", elementCount);
data = elementData.clone();
}
fields.put("elementData", data);
s.writeFields();
}
// 返回 Vector 指定索引及其之后元素的列表迭代器, 使用了ListItr(实现了ListIterator接口)
public synchronized ListIterator<E> listIterator(int index) {
if (index < 0 || index > elementCount)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
// 返回 Vector 的列表迭代器
public synchronized ListIterator<E> listIterator() {
return new ListItr(0);
}
// 返回 Vector 的迭代器
public synchronized Iterator<E> iterator() {
return new Itr();
}
// 内部类Itr: 优化的AbstractList.Itr, 只能往后遍历,支持移除元素(An optimized version of AbstractList.Itr)
private class Itr implements Iterator<E> {
int cursor; // 下一个返回元素的索引
int lastRet = -1; // 最后一次返回元素的索引
int expectedModCount = modCount;
public boolean hasNext() {
// 此方法虽然没有被同步, 但是对他的修改都是在同步内或者同步后的, 所以还是可以使用
// (活泼,但在规范内,因为修改是在同步内或同步后检查的)Racy but within spec, since modifications are checked, within or after synchronization in next/previous
return cursor != elementCount;
}
public E next() {
synchronized (Vector.this) {
checkForComodification();
int i = cursor;
if (i >= elementCount)
throw new NoSuchElementException();
cursor = i + 1;
return elementData(lastRet = i);
}
}
public void remove() {
if (lastRet == -1)
throw new IllegalStateException();
synchronized (Vector.this) {
checkForComodification();
Vector.this.remove(lastRet);
expectedModCount = modCount;
}
cursor = lastRet;
lastRet = -1;
}
// 只能向后一次的forEach, 下一次遍历则为空!
@Override
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
synchronized (Vector.this) {
final int size = elementCount;
int i = cursor;
if (i >= size) {
return;
}
final Object[] es = elementData;
if (i >= es.length)
throw new ConcurrentModificationException();
while (i < size && modCount == expectedModCount)
action.accept(elementAt(es, i++));
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
}
// 判断是否存在多线程并发修改 Vector 实例
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
// 内部类ListItr: 支持向前或向后遍历,支持在迭代过程中增加、移除、修改元素
// An optimized version of AbstractList.ListItr
final class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
public E previous() {
synchronized (Vector.this) {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
cursor = i;
return elementData(lastRet = i);
}
}
public void set(E e) {
if (lastRet == -1)
throw new IllegalStateException();
synchronized (Vector.this) {
checkForComodification();
Vector.this.set(lastRet, e);
}
}
public void add(E e) {
int i = cursor;
synchronized (Vector.this) {
checkForComodification();
Vector.this.add(i, e);
expectedModCount = modCount;
}
cursor = i + 1;
lastRet = -1;
}
}
// 消费 Vector 中的每个元素
@Override
public synchronized void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
final Object[] es = elementData;
final int size = elementCount;
for (int i = 0; modCount == expectedModCount && i < size; i++)
action.accept(elementAt(es, i));
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
// 在i -> end中: 通过函数式接口变换目标元素的值,并替换它
@Override
public synchronized void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final int expectedModCount = modCount;
final Object[] es = elementData;
final int size = elementCount;
for (int i = 0; modCount == expectedModCount && i < size; i++)
es[i] = operator.apply(elementAt(es, i));
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
modCount++;
}
// Vector 进行排序, 还是使用的Arrays.sort()方法
@SuppressWarnings("unchecked")
@Override
public synchronized void sort(Comparator<? super E> c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, elementCount, c);
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
modCount++;
}
// 返回一个JDK 8后加入的Spliterator类, 用于并行遍历元素而设计的一个迭代器
@Override
public Spliterator<E> spliterator() {
return new VectorSpliterator(null, 0, -1, 0);
}
// 内部类VectorSpliterator: Spliterator接口的实现类, 一个可以并行遍历数组的基于索引的二分裂的懒加载的迭代器(与ArrayList类似)
final class VectorSpliterator implements Spliterator<E> {
private Object[] array; // 与ArrayList不同在于加入了一个array引用
private int index; // 当前位置(包含),advance/spilt操作时会被修改(current index, modified on advance/split)
private int fence; // 结束位置(不包含),-1表示到最后一个元素(-1 until used; then one past last index)
private int expectedModCount; // 用于存放list的modCount(initialized when fence set)
// 从origin -> fence范围创建一个Spliterator(Creates new spliterator covering the given range)
VectorSpliterator(Object[] array, int origin, int fence,
int expectedModCount) {
this.array = array;
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
// 第一次使用时实例化结束位置(initialize on first use)
private int getFence() {
int hi;
// 第一次初始化时,fence才会小于0
if ((hi = fence) < 0) {
synchronized (Vector.this) {
array = elementData;
expectedModCount = modCount;
hi = fence = elementCount;
}
}
return hi;
}
// 分割list,返回一个返回一个新分割出的spilterator实例(相当于二分法,这个方法会递归)
// 1. VectorSpliterator本质还是对原list进行操作,只是通过index和fence来控制每次处理的范围
public Spliterator<E> trySplit() {
// hi结束位置(不包括) lo:开始位置 mid中间位置
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
// 当lo >= mid, 表示不能再分割
// 当lo < mid时,表示可以分割,切割(lo, mid)出去,同时更新index = mid
return (lo >= mid) ? null :
new VectorSpliterator(array, lo, index = mid, expectedModCount);
}
// 返回true时,表示可能还有元素未处理, 返回falsa时,没有剩余元素处理了
@SuppressWarnings("unchecked")
public boolean tryAdvance(Consumer<? super E> action) {
Objects.requireNonNull(action);
int i;
if (getFence() > (i = index)) {
index = i + 1;
action.accept((E)array[i]);
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
// 顺序遍历处理所有剩下的元素
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int hi = getFence();
final Object[] a = array;
int i;
for (i = index, index = hi; i < hi; i++)
action.accept((E) a[i]);
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
// 估算大小
public long estimateSize() {
return getFence() - index;
}
// 返回特征值
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}
}
总结:
① Vector实际上是通过一个数组去保存数据的。当我们构造Vecotr时;若使用默认构造函数,则Vector的默认容量大小是10
② 当Vector容量不足以容纳全部元素时,Vector的容量会增加。若容量增加系数 >0,则将容量的值增加“容量增加系数”;否则,将容量大小增加一倍
③ Vector的克隆函数,即是将全部元素克隆到一个数组中**
其实Vector基本上就是将全部方法都synchronized的ArrayList, 所以效率相当的低
四. Vector遍历方式
整表遍历
Vector支持4种整表遍历方式
① 通过迭代器遍历, 即通过Iterator去遍历
Integer value = null;
Iterator<Integer> iterator = vector.iterator();
while (iterator.hasNext()) {
value = iterator.next();
}② 随机访问,通过索引值去遍历
Integer value = null;
for (int i=0, size = vec.size(); i<size; i++) {
value = (Integer)vec.get(i);
}③ forEach语法遍历
Integer value = null;
for (Integer integ:vec) {
value = integ;
}④ Enumeration遍历
Integer value = null;
Enumeration<Integer> enumeration = vector.elements();
while (enumeration.hasMoreElements()) {
value = enumeration.nextElement();
}测试这些遍历方式效率的代码如下:
/**
* @author zk
*/
public class VectorRandomAccessTest {
public static void main(String[] args) {
Vector vec = new Vector();
for (int i = 0; i < 100000; i++) {
vec.add(i);
}
iteratorThroughRandomAccess(vec);
iteratorThroughIterator(vec);
iteratorThroughFor2(vec);
iteratorThroughEnumeration(vec);
}
private static void isRandomAccessSupported(List list) {
if (list instanceof RandomAccess) {
System.out.println("RandomAccess implemented!");
} else {
System.out.println("RandomAccess not implemented!");
}
}
public static void iteratorThroughRandomAccess(List list) {
long startTime;
long endTime;
startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
endTime = System.currentTimeMillis();
long interval = endTime - startTime;
System.out.println("iteratorThroughRandomAccess:" + interval + " ms");
}
public static void iteratorThroughIterator(List list) {
long startTime;
long endTime;
startTime = System.currentTimeMillis();
for (Iterator iter = list.iterator(); iter.hasNext(); ) {
iter.next();
}
endTime = System.currentTimeMillis();
long interval = endTime - startTime;
System.out.println("iteratorThroughIterator:" + interval + " ms");
}
public static void iteratorThroughFor2(List list) {
long startTime;
long endTime;
startTime = System.currentTimeMillis();
for (Object obj : list)
;
endTime = System.currentTimeMillis();
long interval = endTime - startTime;
System.out.println("iteratorThroughFor2:" + interval + " ms");
}
public static void iteratorThroughEnumeration(Vector vec) {
long startTime;
long endTime;
startTime = System.currentTimeMillis();
for (Enumeration enu = vec.elements(); enu.hasMoreElements(); ) {
enu.nextElement();
}
endTime = System.currentTimeMillis();
long interval = endTime - startTime;
System.out.println("iteratorThroughEnumeration:" + interval + " ms");
}
}
------- Output --------
iteratorThroughRandomAccess:6 ms
iteratorThroughIterator:7 ms
iteratorThroughFor2:6 ms
iteratorThroughEnumeration:6 ms
总结: 遍历Vector,使用索引的随机访问方式最快,使用迭代器最慢
建议使用随机访问去遍历Vector
遍历SubList
与ArrayList相似, Vector中也存在一个subList()方法, 用于返回Vector的一个子视图, 示例如下:
List<Integer> vector = new Vector<>(20);
for (int i = 0; i < 20; i++) {
vector.add(i);
}
List<Integer> subList = vector.subList(10, 15);
System.out.println(subList.getClass().getName() + ": " + subList); // java.util.Collections$SynchronizedRandomAccessList: [10, 11, 12, 13, 14]
subList.add(100);
System.out.println(subList); // [10, 11, 12, 13, 14, 100]
System.out.println(vector); // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 100, 15, 16, 17, 18, 19]
注意:
① subList()方法返回的也是一个List类型(ArrayList中的叫做SubList的内部类), 所以他拥有所有List接口中的方法;
② 对subList的操作最终也会影响到原数组, 这一点要注意;
使用Spliterator并发遍历
在JDK 8之后添加了Spliterator接口, 用于并发操作List以提高性能
Vector中也有一个实现了Spliterator接口的内部类: VectorSpliterator
与ArrayList相同, 下面这个例子展示了Spliterator的实际使用: 创建一个长度为100的list,如果下标能被10整除,则该位置数值跟下标相同,否则值为aaaa。然后多线程遍历list,取出list中的数值(字符串aaaa不要)进行累加求和
public class Test {
static List<String> list;
static AtomicInteger count;
public static void main(String[] args) throws InterruptedException {
// 初始化List, 并获得spliterator
list = new Vector<>();
for (int i = 1; i <= 100; i++) {
if (i % 10 == 0) {
list.add(Integer.toString(i));
} else {
list.add("aaaa");
}
}
Spliterator<String> spliterator = list.spliterator();
// 求和结果
count = new AtomicInteger(0);
Spliterator<String> s1 = spliterator.trySplit();
Spliterator<String> s2 = spliterator.trySplit();
Thread main = new Thread(new Task(spliterator));
Thread t1 = new Thread(new Task(s1));
Thread t2 = new Thread(new Task(s2));
main.start();
t1.start();
t2.start();
t1.join();
t2.join();
main.join();
System.out.println(count);
}
// 判断字符串是数字
public static boolean isInteger(String str) {
Pattern pattern = Pattern.compile("^[-+]?[\\d]*$");
return pattern.matcher(str).matches();
}
static class Task implements Runnable {
private Spliterator<String> spliterator;
public Task(Spliterator<String> spliterator) {
this.spliterator = spliterator;
}
@Override
public void run() {
String threadName = Thread.currentThread().getName();
System.out.println("线程" + threadName + "开始运行-----");
spliterator.forEachRemaining(x -> {
if (isInteger(x)) {
count.addAndGet(Integer.parseInt(x));
System.out.println("数值:" + x + "------" + threadName);
}
});
System.out.println("线程" + threadName + "运行结束-----");
}
}
}
------- Output -------
线程Thread-2开始运行-----
线程Thread-0开始运行-----
线程Thread-1开始运行-----
数值:80------Thread-0
数值:90------Thread-0
数值:100------Thread-0
线程Thread-0运行结束-----
数值:10------Thread-1
数值:20------Thread-1
数值:60------Thread-2
数值:70------Thread-2
线程Thread-2运行结束-----
数值:30------Thread-1
数值:40------Thread-1
数值:50------Thread-1
线程Thread-1运行结束-----
550
代码说明:
与ArrayList相似, 只是将
new ArrayList<>()换为了new Vector<>()而已
五. Vector示例
下面通过示例学习如何使用Vector
/**
* @desc Vector测试函数:遍历Vector和常用API
*
* @author zk
*/
public class VectorTest {
public static void main(String[] args) {
// 新建Vector
Vector vec = new Vector();
// 添加元素
vec.add("1");
vec.add("2");
vec.add("3");
vec.add("4");
vec.add("5");
// 设置第一个元素为100
vec.set(0, "100");
// 将“500”插入到第3个位置
vec.add(2, "300");
System.out.println("vec:"+vec);
// (顺序查找)获取100的索引
System.out.println("vec.indexOf(100):"+vec.indexOf("100"));
// (倒序查找)获取100的索引
System.out.println("vec.lastIndexOf(100):"+vec.lastIndexOf("100"));
// 获取第一个元素
System.out.println("vec.firstElement():"+vec.firstElement());
// 获取第3个元素
System.out.println("vec.elementAt(2):"+vec.elementAt(2));
// 获取最后一个元素
System.out.println("vec.lastElement():"+vec.lastElement());
// 获取Vector的大小
System.out.println("size:"+vec.size());
// 获取Vector的总的容量
System.out.println("capacity:"+vec.capacity());
// 获取vector的“第2”到“第4”个元素
System.out.println("vec 2 to 4:"+vec.subList(1, 4));
// 通过Enumeration遍历Vector
Enumeration enu = vec.elements();
while(enu.hasMoreElements()) {
System.out.println("nextElement():"+enu.nextElement());
}
Vector retainVec = new Vector();
retainVec.add("100");
retainVec.add("300");
// 获取“vec”中包含在“retainVec中的元素”的集合
System.out.println("vec.retain():"+vec.retainAll(retainVec));
System.out.println("vec:"+vec);
// 获取vec对应的String数组
String[] arr = (String[]) vec.toArray(new String[0]);
for (String str:arr) {
System.out.println("str:"+str);
}
// 清空Vector。clear()和removeAllElements()一样!
vec.clear();
// vec.removeAllElements();
// 判断Vector是否为空
System.out.println("vec.isEmpty():"+vec.isEmpty());
}
}
------- Output --------
vec:[100, 2, 300, 3, 4, 5]
vec.indexOf(100):0
vec.lastIndexOf(100):0
vec.firstElement():100
vec.elementAt(2):300
vec.lastElement():5
size:6
capacity:10
vec 2 to 4:[2, 300, 3]
nextElement():100
nextElement():2
nextElement():300
nextElement():3
nextElement():4
nextElement():5
vec.retain():true
vec:[100, 300]
str:100
str:300
vec.isEmpty():true