
在上一篇Java集合一-Collection架构,学习了Collection的架构。
这一章开始,我们对Collection的具体实现类进行讲解;首先,讲解List,而List中ArrayList又最为常用。因此,本章我们讲解ArrayList。先对ArrayList有个整体认识,再学习它的源码,最后再通过例子来学习如何使用它。内容包括:
- ArrayList简介
- ArrayList数据结构
- ArrayList源码解析(基于JDK11.0.4)
- ArrayList遍历方式(完整遍历, 子列表遍历, 并发遍历)
- toArray()异常
一. ArrayList介绍
ArrayList 是一个数组队列,相当于 动态数组。与Java中的数组相比,它的容量能动态增长。它继承于AbstractList,实现了List, RandomAccess, Cloneable, java.io.Serializable这些接口, 并提供了相关的添加、删除、修改、遍历等功能
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {...}特性:
ArrayList实现了RandmoAccess接口: 提供了随机访问功能;
小贴士:
RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象, 这就是快速随机访问。
稍后,我们会比较List的“快速随机访问”和“通过Iterator迭代器访问”的效率。
ArrayList 实现了Cloneable接口: 即覆盖了函数clone(),能被克隆;
ArrayList 实现java.io.Serializable接口: 这意味着ArrayList支持序列化,能通过序列化去传输;
和Vector不同,ArrayList中的操作不是线程安全的!所以,建议在单线程中才使用ArrayList(效率更高), 而在多线程中可以选择Vector或者CopyOnWriteArrayList。
ArrayList构造函数
// 默认构造函数
ArrayList()
// capacity是ArrayList的默认容量大小。当由于增加数据导致容量不足时,容量会添加上一次容量大小的一半。
ArrayList(int capacity)
// 创建一个包含collection的ArrayList
ArrayList(Collection<? extends E> collection)
小贴士:
阿里巴巴Java规范规定了在创建底层是数组实现的容器时, 需要预估容量, 防止容器不断扩容, 影响性能!(默认大小才10!)
ArrayList的API
/* Collection中定义的API */
boolean add(E object)
boolean addAll(Collection<? extends E> collection)
void clear()
boolean contains(Object object)
boolean containsAll(Collection<?> collection)
boolean equals(Object object)
int hashCode()
boolean isEmpty()
Iterator<E> iterator()
boolean remove(Object object)
boolean removeAll(Collection<?> collection)
boolean retainAll(Collection<?> collection)
int size()
<T> T[] toArray(T[] array)
Object[] toArray()
/* AbstractCollection中定义的API */
void add(int location, E object)
boolean addAll(int location, Collection<? extends E> collection)
E get(int location)
int indexOf(Object object)
int lastIndexOf(Object object)
ListIterator<E> listIterator(int location)
ListIterator<E> listIterator()
E remove(int location)
E set(int location, E object)
List<E> subList(int start, int end)
/* Object中定义的方法 */
Object clone()
/* ArrayList中定义的方法 */
void ensureCapacity(int minimumCapacity)
void trimToSize()
/* JDK 8中Iterable接口中定义的新方法 */
void forEach(Consumer<? super E> action)
/* JDK 8中Collection新加入的方法 */
Spliterator<E> spliterator()
boolean removeIf(Predicate<? super E> filter)
/* JDK 8中List新加入的方法 */
void replaceAll(UnaryOperator<E> operator)
void sort(Comparator<? super E> c)二. ArrayList数据结构
java.lang.Object
↳ java.util.AbstractCollection<E>
↳ java.util.AbstractList<E>
↳ java.util.ArrayList<E>
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {}ArrayList与Collection关系如下图:
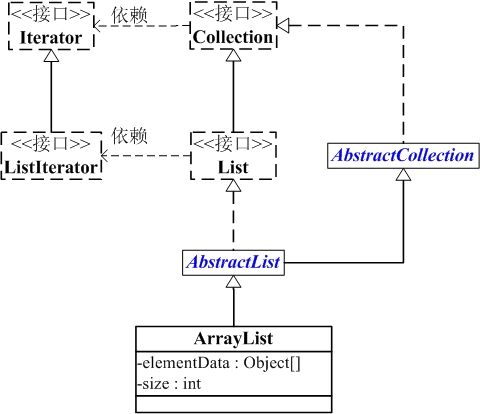
ArrayList包含了两个重要的对象:elementData 和 size, 如下:
transient Object[] elementData; // non-private to simplify nested class access
private int size; // The size of the ArrayList (the number of elements it contains).elementData 是
Object[]类型的数组,它保存了添加到ArrayList中的元素;
备注:
① 实际上,elementData是个动态数组,我们能通过构造函数 ArrayList(int initialCapacity)来执行它的初始容量为initialCapacity;
② 如果通过不含参数的构造函数ArrayList()来创建ArrayList,则elementData的容量默认是: 10
private static final int DEFAULT_CAPACITY = 10;
③ elementData数组的大小会根据ArrayList容量的增长而动态的增长,具体的自动增长方式,由private方法
newCapacity()决定;自动增长默认为增长50%, 源代码为:private int newCapacity(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity <= 0) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) return Math.max(DEFAULT_CAPACITY, minCapacity); if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return minCapacity; } return (newCapacity - MAX_ARRAY_SIZE <= 0) ? newCapacity : hugeCapacity(minCapacity); }即新的容量 = 旧容量 + 旧容量 / 2
④ ensureCapacity()方法是一个public方法, 所以理论上也可以手动通过该方法扩容
原注释:
Increases the capacity of this {@code ArrayList} instance, if necessary, to ensure that it can hold at least the number of elements specified by the minimum capacity argument.
size 则是动态数组的实际大小。
三. ArrayList源码解析(基于JDK11.0.4)
为了更了解ArrayList的原理,下面对ArrayList源码代码作出分析。ArrayList是通过数组实现的,源码比较容易理解。
/**
* 1)List 接口的可变数组实现,ArrayList 允许使用任何元素,包括 null。
* 2)ArrayList 和 Vector 基本类似,只不过 Vector 是线程安全的,ArrayList 是线程不安全的。
* 3)size、isEmpty、get、set、iterator 和 listIterator 以常量时间运行,其他的操作基本以线性时间运行。
* 4)每个 ArrayList 都有一个容量(elementData.length),表示该 ArrayList 当前能容纳的元素个数,随着元素的增加, ArrayList 会自动扩容。
* 5)在创建 ArrayList 时可以指定一个合适的初始化容量,以减少频繁扩容带来的性能损耗。
* 6)ArrayList 是线程不安全的,多线程并发访问 ArrayList 并且至少有一个线程修改了它的结构【增加、删除元素、扩容等】, 则 ArrayList 将抛出 ConcurrentModificationException 异常。
* 7)快速失败(fast-fall):iterator 和 listIterator 返回的迭代器是快速失败的,如果不是通过ListIterator#remove() 或 ListIterator#add(Object) 方法修改其结构,则 ArrayList 将尽最大努力抛出ConcurrentModificationException 异常。
* 8)ArrayList中存在一个很重要的变量: modCount(继承自AbstractList), 代表了当前对象版本号, 每次增/删/改, 都会修改版本号, 用于实现多线程并发时的fast-fall;
* 9)ArrayList 的缩容机制:通过 trimToSize 方法将 ArrayList 的容量缩小为当前元素的个数,以减少 ArrayList 的内存占用。
* 10)ArrayList 的扩容机制:默认为 1.5 倍向下取整(old + old >> 2)扩容,如果批量添加元素,则以 size+newNum 进行扩容。
*/
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandWrite out size as capacity for behavioral compatibility with clone()omAccess, Cloneable, java.io.Serializable {
// 序列版本号
private static final long serialVersionUID = 8683452581122892189L;
// 默认初始容量
private static final int DEFAULT_CAPACITY = 10;
// 空数组,当调用初始化参数且值为0的构造函数的时候默认给个空数组
private static final Object[] EMPTY_ELEMENTDATA = {};
// 空数组,当调用无参数构造函数的时候默认给个空数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 这才是真正保存数据的数组, 没有定义为private为了简化内部操作(non-private to simplify nested class access)
transient Object[] elementData;
// arrayList的实际元素数量
private int size;
// 构造方法传入默认的capacity 设置默认数组大小
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
// 无参数构造方法默认为空数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// 构造方法传入一个Collection, 则将Collection里面的值copy到arrayList
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// 调用toArray()使用错误的类型不会返回Object[]类型(defend against c.toArray (incorrectly) not returning Object[])
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
this.elementData = EMPTY_ELEMENTDATA;
}
}
// 将 ArrayList 的容量缩小为当前元素的个数,以减少 ArrayList 的内存占用
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
// 增加 ArrayList 的容量以满足最少能容纳 minCapacity 个元素
public void ensureCapacity(int minCapacity) {
if (minCapacity > elementData.length
&& !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
&& minCapacity <= DEFAULT_CAPACITY)) {
modCount++;
grow(minCapacity);
}
}
// 可分配的最大数组大小
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 增加 ArrayList 的容量以满足最少能容纳 minCapacity 个元素
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}
// 默认每次增加一个空间,触发 1.5 倍向下取整扩容
private Object[] grow() {
return grow(size + 1);
}
// 基于预期容量计算新的容量, 计算式为: newCapacity = oldCapacity + (oldCapacity >> 1)
private int newCapacity(int minCapacity) {
// 有可能计算会溢出(overflow-conscious code)
int oldCapacity = elementData.length;
// 1.5 倍向下取整扩容
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 默认扩容后的容量小于预期容量
if (newCapacity - minCapacity <= 0) {
// 第一次扩容时,取 10 和 minCapacity 的最大值
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // 预期容量发生溢出(overflow)
throw new OutOfMemoryError();
return minCapacity;
}
// 新的容量小于等于 Integer.MAX_VALUE - 8 则直接返回,否则基于预期容量返回 Integer.MAX_VALUE - 8 或 Integer.MAX_VALUE
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
// 基于预期容量返回 Integer.MAX_VALUE - 8 或 Integer.MAX_VALUE
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // 预期容量发生溢出(overflow)
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE)
? Integer.MAX_VALUE
: MAX_ARRAY_SIZE;
}
// 返回当前中数组元素的个数(不是容器大小!)
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
// 通过 {@link Object#equals(Object)} 方法判断相等元素是否存在
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
// 从头开始遍历,如果不存在相等元素,则返回 -1
public int indexOf(Object o) {
return indexOfRange(o, 0, size);
}
// 从start -> end遍历,如果不存在相等元素,则返回 -1
int indexOfRange(Object o, int start, int end) {
Object[] es = elementData;
if (o == null) {
for (int i = start; i < end; i++) {
if (es[i] == null) {
return i;
}
}
} else {
for (int i = start; i < end; i++) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}
// 从尾部开始遍历,如果不存在相等元素,则返回 -1
public int lastIndexOf(Object o) {
return lastIndexOfRange(o, 0, size);
}
// 从尾部开始遍历end -> start,如果不存在相等元素,则返回 -1
int lastIndexOfRange(Object o, int start, int end) {
Object[] es = elementData;
if (o == null) {
for (int i = end - 1; i >= start; i--) {
if (es[i] == null) {
return i;
}
}
} else {
for (int i = end - 1; i >= start; i--) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}
// 获取 ArrayList 的浅拷贝对象
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// 当对象是实现了Cloneable接口, 则不会错误(this shouldn't happen, since we are Cloneable)
throw new InternalError(e);
}
}
// 返回包含 ArrayList 所有元素的对象数组
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
// 返回包含 ArrayList 所有元素的对象数组, 返回值为T类型(返回时已经强制转换!)
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size)
// 返回值为运行时类型(Make a new array of a's runtime type, but my contents:)
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
// 位置访问操作
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
// 位置访问操作
@SuppressWarnings("unchecked")
static <E> E elementAt(Object[] es, int index) {
return (E) es[index];
}
// 获取指定索引处的元素
public E get(int index) {
Objects.checkIndex(index, size);
return elementData(index);
}
// 替换指定索引处的元素,并返回旧值
public E set(int index, E element) {
Objects.checkIndex(index, size);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
// 将方法字节码控制在 35(the -XX:MaxInlineSize default value) 个之内,以实现预编译和内联
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
// 在 ArrayList 尾部新增元素
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
// 在指定的位置插入元素
public void add(int index, E element) {
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if ((s = size) == (elementData = this.elementData).length)
elementData = grow();
// 将目标索引处的元素集体右移一个位置
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
// 将新元素更新到目标索引处
elementData[index] = element;
size = s + 1;
}
// 移除指定索引处的元素
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}
// 通过元素的 {@link Object#equals(Object)} 方法比较两个List中元素是否相等(另一个只要是List接口的实现类即可!)
public boolean equals(Object o) {
if (o == this) {
return true;
}
if (!(o instanceof List)) {
return false;
}
final int expectedModCount = modCount;
// 另一个只要是List接口的实现类即可, 当然可以很好地处理是ArrayList类型的情况(ArrayList can be subclassed and given arbitrary behavior, but we can still deal with the common case where o is ArrayList precisely)
boolean equal = (o.getClass() == ArrayList.class)
? equalsArrayList((ArrayList<?>) o)
: equalsRange((List<?>) o, 0, size);
checkForComodification(expectedModCount);
return equal;
}
// 用在equals中, 当另一个不是ArrayList(但是仍然是List接口的实现类时)通过元素的 {@link Object#equals(Object)} 方法比较两个List是否相同
// 使用迭代器遍历, 所以效率较低
boolean equalsRange(List<?> other, int from, int to) {
final Object[] es = elementData;
if (to > es.length) {
throw new ConcurrentModificationException();
}
var oit = other.iterator();
for (; from < to; from++) {
if (!oit.hasNext() || !Objects.equals(es[from], oit.next())) {
return false;
}
}
return !oit.hasNext();
}
// 用在equals方法中, 当比较的另一个List是ArrayList类型时比较
// 由于底层都是数组, 所以效率更高!
private boolean equalsArrayList(ArrayList<?> other) {
final int otherModCount = other.modCount;
final int s = size;
boolean equal;
if (equal = (s == other.size)) {
final Object[] otherEs = other.elementData;
final Object[] es = elementData;
if (s > es.length || s > otherEs.length) {
throw new ConcurrentModificationException();
}
for (int i = 0; i < s; i++) {
if (!Objects.equals(es[i], otherEs[i])) {
equal = false;
break;
}
}
}
other.checkForComodification(otherModCount);
return equal;
}
// 通过比较modCount(类似于版本号), 判断在并发操作时, 是否同时修改了数组值
// 如一个线程在遍历时, 另一个线程修改了ArrayList, 则版本号最终不同, 会抛出ConcurrentModificationException
private void checkForComodification(final int expectedModCount) {
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
// ArrayList重写的hashCode()方法, 通过遍历数组的元素生成!
public int hashCode() {
int expectedModCount = modCount;
int hash = hashCodeRange(0, size);
checkForComodification(expectedModCount);
return hash;
}
// 遍历from -> to索引的元素生成hashCode
int hashCodeRange(int from, int to) {
final Object[] es = elementData;
if (to > es.length) {
throw new ConcurrentModificationException();
}
int hashCode = 1;
for (int i = from; i < to; i++) {
Object e = es[i];
hashCode = 31 * hashCode + (e == null ? 0 : e.hashCode());
}
return hashCode;
}
// 通过 {@link Object#equals(Object)} 方法获取第一个匹配的元素并移除
public boolean remove(Object o) {
final Object[] es = elementData;
final int size = this.size;
int i = 0;
found: {
if (o == null) {
for (; i < size; i++)
if (es[i] == null)
break found;
} else {
for (; i < size; i++)
if (o.equals(es[i]))
break found;
}
return false;
}
fastRemove(es, i);
return true;
}
// 移除元素时,跳过索引校验并且不返回旧元素的值
// 使用System.arraycopy()方法直接复制
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
// 如果移除索引在数组中间,则目标索引处右侧的元素集体左移一个单位
System.arraycopy(es, i + 1, es, i, newSize - i);
// 将最后一个元素置为 null, 并修改新长度
es[size = newSize] = null;
}
// 清空数组元素和 size
public void clear() {
modCount++;
final Object[] es = elementData;
for (int to = size, i = size = 0; i < to; i++)
es[i] = null;
}
// 将集合中的元素依次加入到 ArrayList 尾部
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
Object[] elementData;
final int s;
// 新增元素个数大于 ArrayList 的剩余容量,则执行扩容,预期容量为 size+newNum
if (numNew > (elementData = this.elementData).length - (s = size))
elementData = grow(s + numNew);
System.arraycopy(a, 0, elementData, s, numNew);
size = s + numNew;
return true;
}
// 在指定的索引处新增集合中的元素
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
Object[] elementData;
final int s;
if (numNew > (elementData = this.elementData).length - (s = size))
elementData = grow(s + numNew);
// 计算需要右移的元素个数
int numMoved = s - index;
if (numMoved > 0)
// 将目标索引处及其右侧的元素集体右移 numNew 个位置,移动的元素个数为 numMoved
System.arraycopy(elementData, index,
elementData, index + numNew,
numMoved);
// 将集合中的元素拷贝到 ArrayList 缓冲数组中
System.arraycopy(a, 0, elementData, index, numNew);
size = s + numNew;
return true;
}
// 移除指定索引范围内的所有元素,包括开始索引,不包括结束索引
protected void removeRange(int fromIndex, int toIndex) {
if (fromIndex > toIndex) {
throw new IndexOutOfBoundsException(
outOfBoundsMsg(fromIndex, toIndex));
}
modCount++;
shiftTailOverGap(elementData, fromIndex, toIndex);
}
// 将lo -> hi移到末尾并置为null, 后面的元素前移并填补上(Erases the gap from lo to hi, by sliding down following elements)
// 主要用在removeRange(), batchRemove()等大范围删除方法中
private void shiftTailOverGap(Object[] es, int lo, int hi) {
System.arraycopy(es, hi, es, lo, size - hi);
for (int to = size, i = (size -= hi - lo); i < to; i++)
es[i] = null;
}
// 另一个rangeCheck方法()用在add和addAll方法中(A version of rangeCheck used by add and addAll)
// 主要完成添加前的index检查
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// IndexOutOfBoundsException异常内部消息, 用于错误处理(毕竟IndexOutOfBoundsException太常见了!)
// (Constructs an IndexOutOfBoundsException detail message. Of the many possible refactorings of the error handling code, this "outlining" performs best with both server and client VMs.)
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
// 另一个版本的outOfBoundsMsg()方法, 用在检查(fromIndex > toIndex)的情况(A version used in checking (fromIndex > toIndex) condition)
private static String outOfBoundsMsg(int fromIndex, int toIndex) {
return "From Index: " + fromIndex + " > To Index: " + toIndex;
}
// 移除 ArrayList 中包含在目标集合中的所有元素,通过 {@link Object#equals(Object)} 进行相等性判断
public boolean removeAll(Collection<?> c) {
return batchRemove(c, false, 0, size);
}
// 保留 ArrayList 中包含在目标集合中的所有元素,通过 {@link Object#equals(Object)} 进行相等性判断
public boolean retainAll(Collection<?> c) {
return batchRemove(c, true, 0, size);
}
// 删除fromIndex到toIndex(不包括)的元素
boolean batchRemove(Collection<?> c, boolean complement,
final int from, final int end) {
Objects.requireNonNull(c);
final Object[] es = elementData;
int r;
// 跳过数组前不需要操作的元素(Optimize for initial run of survivors)
for (r = from;; r++) {
if (r == end)
return false;
if (c.contains(es[r]) != complement)
break;
}
// 添加数组指针
int w = r++;
// 下面的算法思路是: 使用w记录下一个保存的位置, 如果鉴定元素满足complement条件, 则插入w位置, 最后通过shiftTailOverGap()方法,将末尾元素清空
try {
for (Object e; r < end; r++)
if (c.contains(e = es[r]) == complement)
es[w++] = e;
} catch (Throwable ex) {
// 即使c.contains()抛出异常,也要保持与AbstractCollection的行为兼容性(Preserve behavioral compatibility with AbstractCollection, even if c.contains() throws)
System.arraycopy(es, r, es, w, end - r);
w += end - r;
throw ex;
} finally {
modCount += end - w;
shiftTailOverGap(es, w, end);
}
return true;
}
// 序列化当前ArrayList对象
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// 保留写入时的modCount(版本号), 防止多线程操作在序列化时修改
// 第二个方法写入ArrayList对象和对象内的成员变量(不是内部存储的元素!)
// 原文: Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// 使用clone()方法序列化数组元素个数(Write out size as capacity for behavioral compatibility with clone())
s.writeInt(size);
// 按照元素顺序序列化(Write out all elements in the proper order)
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
// 序列化完成比较版本号, 防止多线程时序列化时被修改
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
// 反序列化ArrayList[与序列化时相同的顺序](Reconstitutes the {@code ArrayList} instance from a stream (that is, deserializes it))
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// 读入size和成员变量(Read in size, and any hidden stuff)
s.defaultReadObject();
// 读入数组开出的大小(Read in capacity, ignored)
// 没什么用, 因为下面在反序列化元素时开的数组大小只是元素个数大小而已(但是为了保证读入的格式)
s.readInt();
if (size > 0) {
// 和clone()方法类似, 但是分配的空间为实际元素个数, 而不是容量!(like clone(), allocate array based upon size not capacity)
SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Object[].class, size);
Object[] elements = new Object[size];
// 按顺序反序列化元素(Read in all elements in the proper order)
for (int i = 0; i < size; i++) {
elements[i] = s.readObject();
}
elementData = elements;
} else if (size == 0) {
elementData = EMPTY_ELEMENTDATA;
} else {
throw new java.io.InvalidObjectException("Invalid size: " + size);
}
}
// 返回 ArrayList 指定索引及其之后元素的列表迭代器, 使用了ListItr(实现了ListIterator接口)
public ListIterator<E> listIterator(int index) {
rangeCheckForAdd(index);
return new ListItr(index);
}
// 返回 ArrayList 的列表迭代器
public ListIterator<E> listIterator() {
return new ListItr(0);
}
// 返回 ArrayList 的迭代器
public Iterator<E> iterator() {
return new Itr();
}
// 内部类Itr: 优化的AbstractList.Itr, 只能往后遍历,支持移除元素(An optimized version of AbstractList.Itr)
private class Itr implements Iterator<E> {
int cursor; // 下一个返回元素的索引
int lastRet = -1; // 最后一次返回元素的索引
int expectedModCount = modCount;
// 防止直接从外部new一个对象(prevent creating a synthetic constructor)
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
// 只能向后一次的forEach, 下一次遍历则为空!
@OverrideforEachRemaining
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int size = ArrayList.this.size;
int i = cursor;
if (i < size) {
final Object[] es = elementData;
if (i >= es.length)
throw new ConcurrentModificationException();
for (; i < size && modCount == expectedModCount; i++)
action.accept(elementAt(es, i));
// update once at end to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
}
// 判断是否存在多线程并发修改 ArrayList 实例
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
// 内部类ListItr: 支持向前或向后遍历,支持在迭代过程中增加、移除、修改元素
// An optimized version of AbstractList.ListItr
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
// 获取 ArrayList 指定索引之间的元素视图,返回值和 ArrayList 共享底层对象数组, 即修改这个对象, 原数组也会变更!
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList<>(this, fromIndex, toIndex);
}
// 内部类SubList, 方法与ArrayList类似, 这里不再赘述
private static class SubList<E> extends AbstractList<E> implements RandomAccess {
private final ArrayList<E> root;
private final SubList<E> parent;
private final int offset;
private int size;
...
}
// 消费 ArrayList 中的每个元素
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
final Object[] es = elementData;
final int size = this.size;
for (int i = 0; modCount == expectedModCount && i < size; i++)
action.accept(elementAt(es, i));
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
// 返回一个JDK 8后加入的Spliterator类, 用于并行遍历元素而设计的一个迭代器
@Override
public Spliterator<E> spliterator() {
return new ArrayListSpliterator(0, -1, 0);
}
// 内部类ArrayListSpliterator: Spliterator接口的实现类, 一个可以并行遍历数组的基于索引的二分裂的懒加载的迭代器(Index-based split-by-two, lazily initialized Spliterator)
final class ArrayListSpliterator implements Spliterator<E> {
private int index; // 当前位置(包含),advance/spilt操作时会被修改(current index, modified on advance/split)
private int fence; // 结束位置(不包含),-1表示到最后一个元素(-1 until used; then one past last index)
private int expectedModCount; // 用于存放list的modCount(initialized when fence set)
// 从origin -> fence范围创建一个Spliterator(Creates new spliterator covering the given range)
ArrayListSpliterator(int origin, int fence, int expectedModCount) {
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
// 第一次使用时实例化结束位置
private int getFence() {
int hi; // (a specialized variant appears in method forEach)
// 第一次初始化时,fence才会小于0
if ((hi = fence) < 0) {
expectedModCount = modCount;
hi = fence = size;
}
return hi;
}
// 分割list,返回一个返回一个新分割出的spilterator实例(相当于二分法,这个方法会递归)
// 1. ArrayListSpilterator本质还是对原list进行操作,只是通过index和fence来控制每次处理的范围
public ArrayListSpliterator trySplit() {
// hi结束位置(不包括) lo:开始位置 mid中间位置
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
// 当lo >= mid, 表示不能再分割
// 当lo < mid时,表示可以分割,切割(lo, mid)出去,同时更新index = mid
return (lo >= mid) ? null :
new ArrayListSpliterator(lo, index = mid, expectedModCount);
}
// 返回true时,表示可能还有元素未处理, 返回falsa时,没有剩余元素处理了
public boolean tryAdvance(Consumer<? super E> action) {
if (action == null)
throw new NullPointerException();
int hi = getFence(), i = index;
if (i < hi) {
index = i + 1;
@SuppressWarnings("unchecked") E e = (E)elementData[i];
action.accept(e);
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
// 顺序遍历处理所有剩下的元素
public void forEachRemaining(Consumer<? super E> action) {
int i, hi, mc; // hoist accesses and checks from loop
Object[] a;
if (action == null)
throw new NullPointerException();
// 如果list中的元素不为空
if ((a = elementData) != null) {
if ((hi = fence) < 0) {
mc = modCount;
hi = size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
// 估算大小
public long estimateSize() {
return getFence() - index;
}
// 返回特征值
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}
/* 一些位操作实现(A tiny bit set implementation) */
// 用在了removeIf()方法中, 作用是初始化一个数组, 数组长度是按照 (n - 1) >> 6 + 1 的逻辑来得到的
// >> 是算术位移,简单的来说就是将数字除以 2 的 n 次方,>> 6 就是除以 2 的 6 次方,即除以 64, 因此 nBits 方法会以 64 为单位来收缩,并返回收缩后长度的数组
private static long[] nBits(int n) {
return new long[((n - 1) >> 6) + 1];
}
// 同样用在removeIf()方法中, 作用就是将 i 转换为 2 的 i 次方数字后,进行合并,而合并的结果其实是将第 i 位置为 1, 其余位为零(位图索引)
// 在removeIf()方法中: deathRow 是一个「位图」(Bitmap) 的数据结构
private static void setBit(long[] bits, int i) {
bits[i >> 6] |= 1L << i;
}
// 同样用在removeIf()方法中: isClear 会按照输入去看数组中元素的第 i 位是否被置为 1,如果 没有 被置为 1 ,则返回 true(判断位图索引)
private static boolean isClear(long[] bits, int i) {
return (bits[i >> 6] & (1L << i)) == 0;
}
// JDK1.8 开始引入的,接受参数一个 Predicatie 对象(即一个 lambda 表达式),对于 ArrayList 中的每个元素都会作为参数调用这个 lambda 表达式: 移除 ArrayList 中满足指定函数式断言的所有元素
@Override
public boolean removeIf(Predicate<? super E> filter) {
return removeIf(filter, 0, size);
}
// JDK1.8 开始引入的, 移除所有满足指定断言的元素,包括起始索引,不包括结束索引
boolean removeIf(Predicate<? super E> filter, int i, final int end) {
Objects.requireNonNull(filter);
int expectedModCount = modCount;
final Object[] es = elementData;
// 从头开始略过不满足断言的元素,找到第一个需要移除的元素索引(Optimize for initial run of survivors)
for (; i < end && !filter.test(elementAt(es, i)); i++)
;
// 遍历的同时, 仍然允许以可重入方式访问集合for、read(但写入程序仍然获得CME);
// 第一次遍历查找要删除的元素,第二次遍历以物理方式删除[整个过程记录使用deathRow位图的形式存放匹配成功的元素的偏移量]
// 原文: Tolerate predicates that reentrantly access the collection for, read (but writers still get CME), so traverse once to find elements to delete, a second pass to physically expunge
if (i < end) {
final int beg = i;
final long[] deathRow = nBits(end - beg);
deathRow[0] = 1L; // 初始化位图
for (i = beg + 1; i < end; i++) // 第一次遍历查找要删除的元素
if (filter.test(elementAt(es, i)))
setBit(deathRow, i - beg);
if (modCount != expectedModCount) // 判断多线程是否修改
throw new ConcurrentModificationException();
modCount++;
int w = beg;
for (i = beg; i < end; i++) // 第二次遍历以物理方式删除
if (isClear(deathRow, i - beg))
es[w++] = es[i];
shiftTailOverGap(es, w, end);
return true;
} else {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return false;
}
}
// 在整个ArrayList中: 通过函数式接口变换目标元素的值,并替换它
@Override
public void replaceAll(UnaryOperator<E> operator) {
replaceAllRange(operator, 0, size);
modCount++;
}
// 在i -> end中: 通过函数式接口变换目标元素的值,并替换它
private void replaceAllRange(UnaryOperator<E> operator, int i, int end) {
Objects.requireNonNull(operator);
final int expectedModCount = modCount;
final Object[] es = elementData;
for (; modCount == expectedModCount && i < end; i++)
es[i] = operator.apply(elementAt(es, i));
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
// ArrayList 进行排序, 还是使用的Arrays.sort()方法
@Override
@SuppressWarnings("unchecked")
public void sort(Comparator<? super E> c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, size, c);
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
modCount++;
}
}
更多关于fail-fast机制见: Java集合三-Iterator的Fail-Fast机制总结
四. ArrayList遍历方式(完整遍历, 子列表遍历, 并发遍历)
遍历整个数组的方式
ArrayList支持3种遍历整个数组的方式
① 通过迭代器遍历。即通过Iterator去遍历
List<Integer> list = new ArrayList<>(Arrays.asList(1,2,3,4));
Iterator<Integer> iter = list.iterator();
while (iter.hasNext()) {
System.out.println(iter.next());
}② 随机访问, 通过索引值去遍历
List<Integer> list = new ArrayList<>(Arrays.asList(1,2,3,4));
for (int i = 0, size = list.size(); i < size; i++) {
System.out.println(list.get(i));
}③ 通过forEach语法遍历
List<Integer> list = new ArrayList<>(Arrays.asList(1,2,3,4));
for (Integer ele : list) {
System.out.println(ele);
}
小贴士: 此方法将会丢失循环索引!
下面通过一个实例,比较这3种方式的效率,实例代码如下:
package top.jasonkayzk;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* ArrayList遍历方式和效率的测试程序
*
* @author zk
*/
public class ArrayListRandomAccessTest {
public static void main(String[] args) {
final List<Integer> list = new ArrayList<>();
for (int i = 0; i < 1000000; i++) {
list.add(i);
}
iteratorThroughRandomAccess(list) ;
iteratorThroughIterator(list) ;
iteratorThroughFor(list) ;
}
public static void iteratorThroughRandomAccess(List list) {
long startTime;
long endTime;
startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
endTime = System.currentTimeMillis();
long interval = endTime - startTime;
System.out.println("iterator through RandomAccess:" + interval + " ms");
}
public static void iteratorThroughIterator(List list) {
long startTime;
long endTime;
startTime = System.currentTimeMillis();
for (Iterator iter = list.iterator(); iter.hasNext(); ) {
iter.next();
}
endTime = System.currentTimeMillis();
long interval = endTime - startTime;
System.out.println("iterator through Iterator:" + interval + " ms");
}
public static void iteratorThroughFor(List list) {
long startTime;
long endTime;
startTime = System.currentTimeMillis();
for (Object obj : list) {
;
}
endTime = System.currentTimeMillis();
long interval = endTime - startTime;
System.out.println("iterator ThroughFor:" + interval + " ms");
}
}
遍历一百万个数运行结果:
iterator through RandomAccess:5 ms
iterator through Iterator:7 ms
iterator ThroughFor:6 ms
得出结论: 遍历ArrayList时,使用随机访问(即,通过索引序号访问)效率最高,而使用迭代器的效率和for相差不大!
遍历SubList
ArrayList中存在一个subList()方法, 用于返回ArrayList的一个子视图, 示例如下:
List<Integer> list = new ArrayList<>(100);
for (int i = 0; i < 20; i++) {
list.add(i);
}
List<Integer> subList = list.subList(10, 15);
System.out.println(subList.getClass().getName() + ": " + subList); // java.util.ArrayList$SubList: [10, 11, 12, 13, 14]
subList.add(100);
System.out.println(subList); // [10, 11, 12, 13, 14, 100]
System.out.println(list); // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 100, 15, 16, 17, 18, 19]
注意:
① subList()方法返回的也是一个List类型(ArrayList中的叫做SubList的内部类), 所以他拥有所有List接口中的方法;
② 对subList的操作最终也会影响到原数组, 这一点要注意;
使用Spliterator并发遍历
在JDK 8之后添加了Spliterator接口, 用于并发操作List以提高性能.
Spliterator迭代器的主要作用就是把集合分成了好几段,每个线程执行一段,因此是线程安全的。基于这个原理,以及modCount的快速失败机制,如果迭代过程中集合元素被修改,会抛出异常, 下面这个例子展示了Spliterator的原理:
List<String> arr = new ArrayList<>();
arr.add("a");
arr.add("b");
arr.add("c");
arr.add("d");
arr.add("e");
arr.add("f");
arr.add("g");
arr.add("h");
arr.add("i");
// 此时结果:a:0-9(index-fence)
Spliterator<String> a = arr.spliterator();
// 此时结果:b:4-9,a:0-4
Spliterator<String> b = a.trySplit();
// 此时结果:c:4-6,b:4-9,a:6-9
Spliterator<String> c = a.trySplit();
// 此时结果:d:6-7,c:4-6,b:4-9,a:7-9
Spliterator<String> d = a.trySplit();下面这个例子展示了Spliterator的实际使用: 创建一个长度为100的list,如果下标能被10整除,则该位置数值跟下标相同,否则值为aaaa。然后多线程遍历list,取出list中的数值(字符串aaaa不要)进行累加求和
public class Test {
static List<String> list;
static AtomicInteger count;
public static void main(String[] args) throws InterruptedException {
// 初始化List, 并获得spliterator
list = new ArrayList<>();
for (int i = 1; i <= 100; i++) {
if (i % 10 == 0) {
list.add(Integer.toString(i));
} else {
list.add("aaaa");
}
}
Spliterator<String> spliterator = list.spliterator();
// 求和结果
count = new AtomicInteger(0);
Spliterator<String> s1 = spliterator.trySplit();
Spliterator<String> s2 = spliterator.trySplit();
Thread main = new Thread(new Task(spliterator));
Thread t1 = new Thread(new Task(s1));
Thread t2 = new Thread(new Task(s2));
main.start();
t1.start();
t2.start();
t1.join();
t2.join();
main.join();
System.out.println(count);
}
// 判断字符串是数字
public static boolean isInteger(String str) {
Pattern pattern = Pattern.compile("^[-+]?[\\d]*$");
return pattern.matcher(str).matches();
}
static class Task implements Runnable {
private Spliterator<String> spliterator;
public Task(Spliterator<String> spliterator) {
this.spliterator = spliterator;
}
@Override
public void run() {
String threadName = Thread.currentThread().getName();
System.out.println("线程" + threadName + "开始运行-----");
spliterator.forEachRemaining(x -> {
if (isInteger(x)) {
count.addAndGet(Integer.parseInt(x));
System.out.println("数值:" + x + "------" + threadName);
}
});
System.out.println("线程" + threadName + "运行结束-----");
}
}
}
------- Output -------
线程Thread-0开始运行-----
线程Thread-1开始运行-----
线程Thread-2开始运行-----
数值:60------Thread-2
数值:70------Thread-2
线程Thread-2运行结束-----
数值:80------Thread-0
数值:90------Thread-0
数值:10------Thread-1
数值:100------Thread-0
线程Thread-0运行结束-----
数值:20------Thread-1
数值:30------Thread-1
数值:40------Thread-1
数值:50------Thread-1
线程Thread-1运行结束-----
550
代码说明:
① 由于求和需要并发访问求和结果, 所以采用了AtomicInteger存储结果;
② 结果的输出应该等待所有线程全部执行完毕, 这里使用了CountDownLatch, 当然也可以使用join()方法;
③ forEachRemaining()方法也确保了某个任务不会被重复分配;
④ 其实Stream中可以大量使用这种方式, 所以处理速度可以很快
整个代码运行很快, 即使是处理一百万条的数据!
五. toArray()异常
当我们调用ArrayList中的 toArray(),可能遇到过抛出java.lang.ClassCastException异常的情况。下面我们说说这是怎么回事。
ArrayList提供了2个toArray()函数:
Object[] toArray()<T> T[] toArray(T[] contents)
一般情况下, 调用 toArray() 函数会抛出java.lang.ClassCastException异常,但是调用 toArray(T[] contents) 能正常返回 T[]
toArray()会抛出异常是因为: toArray() 返回的是 Object[] 数组,将 Object[] 转换为其它类型(如,将Object[]转换为的Integer[])就会抛出java.lang.ClassCastException异常,因为Java不支持向下转型, 具体可以参考前面ArrayList.java的源码介绍部分的toArray()
解决该问题的办法是: 调用
调用 toArray(T[] contents) 返回T[]的可以通过以下两种方式实现:
① toArray(T[] contents)调用方式一
List<Integer> list = new ArrayList<>(Arrays.asList(1,2,3,4,5));
Integer[] arr = new Integer[list.size()];
list.toArray(arr);
System.out.println(Arrays.toString(arr));② toArray(T[] contents)调用方式二[常用]
List<Integer> list = new ArrayList<>(Arrays.asList(1,2,3,4,5));
Integer[] arr = list.toArray(new Integer[0]);
System.out.println(Arrays.toString(arr));