
对于想要学习ES的人来说, 集群是一个不得不谈的话题, 而且就目前的形式来说, 越来越要求开发人员会用分布式. 对于ES来说, 由于其本身对分布式集群已经支持的相当完善, 已经屏蔽了大多数的服务发现, fallover等. 但是学习集群首先要有一个集群, 对于大多数人来说, 还是希望在本地运行一个集群. 所以本篇是在笔者查阅了大量资料之后, 经过尝试总结的在ES 7.x版本下如何在单节点下运行ES集群.
阅读本文你将学会:
- 通过将ES复制多份实现单节点集群部署
- 通过使用启动参数(Options)部署单节点集群
- 使用Docker部署单节点集群
- Elasticsearch7目录详解
- Elasticsearch7配置详解
- 部署Elasticsearch7时需要修改的操作系统参数
- ……
在单台服务器部署多个ElasticSearch节点
在单台服务器上部署多个ES节点的方法不止一种, 如果在有docker的运行环境下使用docker来部署是最干净,快捷的. 而笔者想找到通过命令行在启动时读入配置文件启动的方法, 结果最后发现此功能在6.x版本已经被废除, 坑啊!
废话不多说了, 下面来看如何在单节点下部署多个ES节点.
一. 复制多份ES副本, 通过修改配置文件启动
这个方法是最为简单粗暴的, 在任何版本下都可以使用! 下面来详细介绍一下.
1. 首先将ES文件复制两份
我的ES安装在/opt/目录下, 你在使用时应该修改为自己的安装路径
# 复制
sudo cp -r elasticsearch-7.4.0/ elasticsearch-node-1
sudo cp -r elasticsearch-7.4.0/ elasticsearch-node-2
# 修改所属
sudo chown -R zk:zk elasticsearch-node-1
sudo chown -R zk:zk elasticsearch-node-22. 修改配置文件
配置文件默认在%ES_HOME/config下面, 我们要修改的是elasticsearch.yml文件, 配置如下:
# node-1的配置文件
cluster.name: zk-app # 集群名称, 相同集群必须相同
node.name: node-1 # 节点名, 不同节点必须不同
network.host: 127.0.0.1 # 服务器ip地址
http.port: 9200 # http访问端口
transport.tcp.port: 9300 # 集群内部通讯访问端口
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9301"] # 配置多节点
# node-2的配置文件
cluster.name: zk-app
node.name: node-2
network.host: 127.0.0.1 # 服务器ip地址
http.port: 9201 # http访问端口
transport.tcp.port: 9301 # 集群内部通讯访问端口
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9301"] # 配置多节点*注: *这个配置是很简单的配置, 生产环境中的配置文件更为复杂, 如果想要查看配置文件的全部参数, 可以查看官方文档或网上相关信息, 这里不再赘述!
3. 启动节点
分别在elasticSearch的根目录下执行
./bin/elasticsearch运行节点.
以笔者为例, 我先启动了node-1服务, 然后启动了node-2服务. 之后通过命令:
GET /_cluster/health查看集群健康状况则返回:
{
"cluster_name": "zk-app",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 8,
"active_shards": 16,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}或者使用kibana打开浏览器进入Stack Monitoring中查看, 如下图所示:
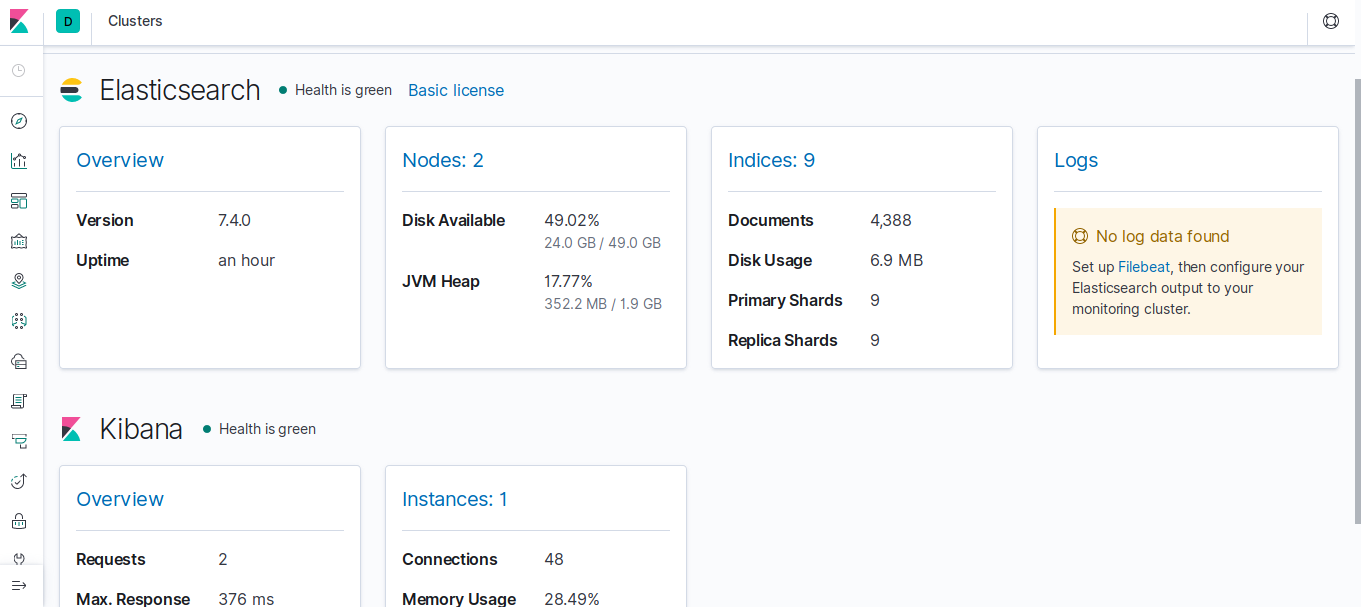
可以看到的确有两个节点在工作, 集群启动成功!
4. 启动时可能出现的问题
Error: with the same id but is a different node instance
如果之前在复制时的文件目录中以及存在data数据了, 则在从节点启动时, 可能会发生节点冲突的错误! 因为之前节点的信息已经被保存在data文件夹中了
*解决方法: *删除data目录即可!
二. 使用启动参数(Options)启动
由于每次启动一个节点都要复制所有的ES文件, 可以说相当的麻烦, 所以有没有更为简单的方法, 可以通过多个配置文件分别启动一个节点.
对于这种情况, 笔者在网上搜集了很多信息, 答案是: 分版本!
对于5.x以下版本: 可通过对Java添加
-Des.default.path.conf=/etc/elasticsearch启动参数根据指定的配置文件目录启动, 其中/etc/elasticsearch即为你实际的配置文件目录. 如:${JAVA_HOME}/bin/java \ -Des.pidfile=/path/xxx.pid \ -Des.default.path.home=/path/xxx \ -Des.default.path.logs=/path/logs \ -Des.default.path.data=/path/data \ -Des.default.path.work=/path/work \ -Des.default.path.conf=/path/config \ -Des.path.home=/path/xxx \ -cp :/path/xxx.jar \ org.elasticsearch.bootstrap.Elasticsearchelasticsearch启动类有两个,分别是Elasticsearch和ElasticsearchF,其中F代表foreground,区别是在前台进程运行还是后台进程运行,以及日志是存储在日志文件中还是显示在控制台中,System.setProperty(“es.foreground”,
“yes”)用来指定foreground。
两个启动类最终都是调用Bootstrap的静态main方法来启动elasticsearch对于5.x版本, 可以使用elasticsearch的启动参数启动, 添加
-- default.path.conf=/etc/elasticsearch. 如:./bin/elasticsearch --default.path.conf=/etc/elasticsearch或使用elasticsearch的
-E参数修改配置启动. 如:./bin/elasticsearch -E path.conf=/etc/elasticsearch对于上面这两种方法, 笔者不确定是哪个, 因为在笔者7.x版本下, 都启动失败!
对于6.x版本及以上, 恭喜你, 你再也无法使用配置文件直接启动啦!(丢!)
对于删除
path.conf参数官方给出的解释:
path.confis no longer a configurable settingeditPrevious versions of Elasticsearch enabled setting
path.confas a setting. This was rather convoluted as it meant that you could start Elasticsearch with a config file that specified viapath.confthat Elasticsearch should use another config file. Instead, to configure a custom config directory, use theES_PATH_CONFenvironment variable.官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/6.2/breaking_60_packaging_changes.html
中文翻译ES6.0变化: Elasticsearch 6.0 重大变化
简单翻译过来就是: 之前版本可以通过path.conf来指定配置文件启动, 这相当复制?! 所以在新的版本中你丫的就别用了. 你可以通过配置ES_PATH_CONF环境变量启动.
而在官方的配置文档中, 也确实推荐通过配置ES_PATH_CONF环境变量来配置ElasticSearch, 并且提供了在ES运行时替换配置的API.
ES 7.4官方文档Configuring Elasticsearch
那就真的没有办法在启动时通过命令行指定参数启动了吗? 答案是: 有, 但是非常不推荐!
可以简单通过下面的命令启动一个master节点:
bin/elasticsearch -E node.data=false -E node.master=true -E node.name=NoData即通过-E <key=value>指定启动参数, 所以理论上可以通过这种方式修改启动参数来启动集群.
但是笔者强烈不推荐这种方式, 因为: 首先,通过命令行构建所有启动参数的方法很不直观, 而且容易产生错误; 其次, 启动多个集群要敲多个命令行, 很是麻烦; 最后, 这是一个相当不优雅的解决方法!
在官方文档也提到了: 提供
-E <key=value>启动参数的目的是用来修改一些和集群配置无关的配置项, 不推荐使用-E来修改和集群相关的配置!
所以还是最好还是使用docker进行单节点启动, 既优雅也方便!
三. 使用docker
使用docker创建集群的方法相当的简单.
1. 拉取镜像
sudo docker pull elasticsearch:7.4.0
sudo docker pull kibana:7.4.02. 分别启动es1和es2
docker run --name=es1 -p 9200:9200 -p 9300:9300 -v /home/zk/workspace/ElasticSearch_Learn/cluster_config/node-1.yml:/usr/share/elasticsearch/config/elasticsearch.yml elasticsearch:7.4.0docker run --name=es2 -p 9201:9201 -p 9301:9301 -v /home/zk/workspace/ElasticSearch_Learn/cluster_config/node-2.yml:/usr/share/elasticsearch/config/elasticsearch.yml elasticsearch:7.4.0注意: 和启动单节点少了个参数
-e "discovery.type=single-node", 但是多了一个参数-v /path/to/custom_conf.yml:/usr/share/elasticsearch/config/elasticsearch.yml具体启动参数及如何启动可查看官方文档: Install Elasticsearch with Docker
通过docker的-v参数可以指定通过本地配置的方式来启动容器! 同时, 在容器中对映射文件/usr/share/elasticsearch/config/elasticsearch.yml做出的修改同时也会修改镜像外的文件!!!
所以在docker中可以通过使用配置文件来启动elasticSearch集群, 但前提是要知道集群IP等信息!
*启动后出现容器自动关闭问题: *
查看容器日志信息,看最后面发现一个error:
docker logs -f 容器id
# 错误显示max_map_count的值太小了,需要设大到262144
ERROR: [1] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least首先检查内存问题: 尤其如果是在虚拟机环境下运行, 由于elasticsearch5.x后版本默认配置会创建一个2g的内存, 所以可能会导致内存不足导致无法启动!
修改系统的内存分配:
# 查看max_map_count : cat /proc/sys/vm/max_map_count 65530 # 设置max_map_count: sysctl -w vm.max_map_count=262144 vm.max_map_count = 262144
(删除之前不能运行的容器)重新创建容器的时候加上:
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m"给elasticsearch分配2g的内存即完整的命令为:
docker run -di --name=自定义名字 -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -p 9200:9200 -p 9300:9300 elasticsearch:版本号最后重启容器:docker start 容器id或名字
通常docker启动数秒钟之后就关闭往往都是因为服务在容器中出现了某些异常而导致启动失败!
此时可以通过:
docker logs -f 容器id来打印相关日志获取异常信息. 修改之后再重新启动即可!
3. 分别查询es1和es2容器的IP
$ docker inspect es1
"SandboxKey": "/var/run/docker/netns/3997bc1d03d2",
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "ea88a5c7a61b54bb6753d2c1d721d2bf2ce1228324ff504c2eb3093bbf0ca30d",
"Gateway": "172.17.0.1",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "172.17.0.2",
......
$ dokcer inspect es2
"SandboxKey": "/var/run/docker/netns/df535135e7db",
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "7b42fe28fec92ab94f7db4f3f4e65b647887874c490a240271df549e6079f7c4",
"Gateway": "172.17.0.1",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "172.17.0.3",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"MacAddress": "02:42:ac:11:00:03",
可以获取到在集群内部的两个节点的虚拟IP信息: 172.17.0.2和172.17.0.3!
4. 进入es1和es2容器中,修改配置文件
# 节点一
$ docker exec -it fe6b5d8c96c0c98aac37b6fbf10af8fea61fee1b273edbdd9eb3c74128ffe1a8 /bin/sh -c "[ -e /bin/bash ] && /bin/bash || /bin/sh"
[root@fe6b5d8c96c0 elasticsearch]# vi /usr/share/elasticsearch/config/elasticsearch.yml
# 修改文件内容如下
# node-1
cluster.name: "zk-app"
network.host: 0.0.0.0
node.name: "node-1"
discovery.seed_hosts: ["127.0.0.1", "172.17.0.2", "172.17.0.3"]
cluster.initial_master_nodes: ["node-1"]
http.cors.enabled: true
http.cors.allow-origin: /.*/$ docker exec -it 24b4802a5952a9c53d352ed3f011c8cf16d6cd442997c5705ac43bcedc2d9b71 /bin/sh -c "[ -e /bin/bash ] && /bin/bash || /bin/sh"
[root@24b4802a5952 elasticsearch]# vi /usr/share/elasticsearch/config/elasticsearch.yml
# 修改文件内容如下
# node-2
cluster.name: "zk-app"
network.host: 0.0.0.0
node.name: "node-2"
discovery.seed_hosts: ["127.0.0.1", "172.17.0.2", "172.17.0.3"]
cluster.initial_master_nodes: ["node-1"]
http.cors.enabled: true
http.cors.allow-origin: /.*/本次集群配置文件采用的是最新版本的(7.x版本)配置方法, 具体集群配置方法在以后会讲解.
此外需要注意的是, 这里的IP是docker容器自己的IP,而不是宿主机的IP!
如果不使用上面的配置方式, 在7.x版本中, 有可能会无法选举主节点. (笔者也是折腾了好久才让集群跑起来!)
常见的错误有:
[cluster.initial master nodes] is empty on this node;the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured等.
需要注意的是其中的一些参数,
- cluster.name: 集群名称, 在一个集群中的节点配置必须相同!
- network.host: 主机地址
- node.name: 本节点名称
- discovery.seed_hosts: Elasticsearch7新增参数,写入候选主节点的设备地址,来开启服务时就可以被选为主节点,由discovery.zen.ping.unicast.hosts:参数改变而来
- cluster.initial_master_nodes: Elasticsearch7新增参数,写入候选主节点的设备地址,来开启服务时就可以被选为主节点
- http.cors.enabled: 开启跨域访问支持,默认为false
- http.cors.allow-origin: 跨域访问允许的域名地址,(允许所有域名)以上使用正则
5. 重启es1和es2容器
修改容器内部的配置文件后, 可通过restart命令重新启动
docker restart es1 es26. 查看集群健康状态
等待两个集群启动完毕之后, 可以通过curl命令查看集群情况:
zk@jasonkay:~$ curl 172.17.0.2:9200/_cat/health
1570184626 10:23:46 zk-app green 2 2 0 0 0 0 0 0 - 100.0%
zk@jasonkay:~$ curl 172.17.0.2:9200/_cat/nodes
172.17.0.2 16 92 7 0.42 0.53 0.56 dilm * node-1
172.17.0.3 10 92 7 0.42 0.53 0.56 dilm - node-2即集群部署成功!
四. Elasticsearch7配置详解
1. 目录介绍
ElasticSearch压缩文件解压后的目录结构如下所示
zk@jasonkay:/opt$ ls /opt/elasticsearch-7.3.2/
bin data lib logs NOTICE.txt README.textile
config jdk LICENSE.txt modules plugins- bin目录:二进制脚本启动es程序文件以及启动es插件目录
- config目录:elasticsearch配置文件
- data目录:默认Elasticsearch生成的索引/切片数据文件存放目录,可以指定多个位置来存储数据
- lib目录:一些开发的jar包
- logs目录:elasticsearch日志目录
- modules目录:模块目录
- plugins目录:elasticsearch插件目录,此版本tar包装后默认无插件
下面对这些目录做一一介绍.
bin目录
zk@jasonkay:/opt/elasticsearch-7.3.2/bin$ ll
总用量 18472
drwxr-xr-x 2 zk zk 4096 9月 6 22:45 ./
drwxr-xr-x 10 zk zk 4096 10月 1 16:42 ../
-rwxr-xr-x 1 zk zk 1954 9月 6 22:38 elasticsearch* # elasticsearch二进制启动脚本
-rwxr-xr-x 1 zk zk 491 9月 6 22:45 elasticsearch-certgen*
-rwxr-xr-x 1 zk zk 483 9月 6 22:45 elasticsearch-certutil*
-rwxr-xr-x 1 zk zk 982 9月 6 22:38 elasticsearch-cli*
-rwxr-xr-x 1 zk zk 433 9月 6 22:45 elasticsearch-croneval*
-rwxr-xr-x 1 zk zk 2180 9月 6 22:38 elasticsearch-env*
-rwxr-xr-x 1 zk zk 121 9月 6 22:38 elasticsearch-keystore* #elasticsearch安全设置,详细用法请看官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.0/secure-settings.html
-rwxr-xr-x 1 zk zk 440 9月 6 22:45 elasticsearch-migrate*
-rwxr-xr-x 1 zk zk 126 9月 6 22:38 elasticsearch-node*
-rwxr-xr-x 1 zk zk 172 9月 6 22:38 elasticsearch-plugin* # 集成插件启动脚本
-rwxr-xr-x 1 zk zk 431 9月 6 22:45 elasticsearch-saml-metadata*
-rwxr-xr-x 1 zk zk 438 9月 6 22:45 elasticsearch-setup-passwords*
-rwxr-xr-x 1 zk zk 118 9月 6 22:38 elasticsearch-shard*
-rwxr-xr-x 1 zk zk 427 9月 6 22:45 elasticsearch-sql-cli*
-rwxr-xr-x 1 zk zk 18828739 9月 6 22:45 elasticsearch-sql-cli-7.3.2.jar*
-rwxr-xr-x 1 zk zk 426 9月 6 22:45 elasticsearch-syskeygen*
-rwxr-xr-x 1 zk zk 426 9月 6 22:45 elasticsearch-users* # 如果es要基于文件的用户身份验证,那么此脚本可以添加、删除、管理用户角色,具体用法看官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/users-command.html
-rwxr-xr-x 1 zk zk 346 9月 6 22:45 x-pack-env*
-rwxr-xr-x 1 zk zk 354 9月 6 22:45 x-pack-security-env*
-rwxr-xr-x 1 zk zk 353 9月 6 22:45 x-pack-watcher-env*config目录
zk@jasonkay:/opt/elasticsearch-7.3.2$ ll config/
总用量 48
drwxr-xr-x 2 zk zk 4096 10月 1 21:45 ./
drwxr-xr-x 10 zk zk 4096 10月 1 16:42 ../
-rw-rw---- 1 zk zk 199 10月 1 16:42 elasticsearch.keystore
-rw-rw---- 1 zk zk 2831 9月 6 22:38 elasticsearch.yml # ES节点集群等相关配置
-rw-rw---- 1 zk zk 3524 9月 6 22:38 jvm.options # JVM堆内存及GC相关配置
-rw-rw---- 1 zk zk 17222 9月 6 22:45 log4j2.properties # log4j2框架日志输出相关配置
-rw-rw---- 1 zk zk 473 9月 6 22:45 role_mapping.yml # 配置身份验证,角色映射文件,其中将elasticsearch角色作为键映射到一个或多个用户或组专有名称,具体用法见官网:https://www.elastic.co/cn/search?q=role_mapping.yml&size=20
-rw-rw---- 1 zk zk 197 9月 6 22:45 roles.yml # 定义身份角色相关配置
-rw-rw---- 1 zk zk 0 9月 6 22:45 users
-rw-rw---- 1 zk zk 0 9月 6 22:45 users_rolesjdk目录
此目录里面就像是我们解压过的JDK一样,官网给出,es集成的JDK默认只为es服务,如果我们系统想要使用es所集成的jdk版本,我们需要添加环境变量至此目录。当然我们也可以自己安装我们系统中所需的JDK版本。
zk@jasonkay:/opt/elasticsearch-7.3.2$ ll jdk/
总用量 36
drwxr-xr-x 8 zk zk 4096 9月 6 22:45 ./
drwxr-xr-x 10 zk zk 4096 10月 1 16:42 ../
drwxr-xr-x 2 zk zk 4096 9月 6 22:44 bin/
drwxr-xr-x 5 zk zk 4096 9月 6 22:44 conf/
drwxr-xr-x 3 zk zk 4096 9月 6 22:44 include/
drwxr-xr-x 2 zk zk 4096 9月 6 22:44 jmods/
drwxr-xr-x 72 zk zk 4096 9月 6 22:44 legal/
drwxr-xr-x 5 zk zk 4096 9月 6 22:44 lib/
-rw-r--r-- 1 zk zk 1190 9月 6 22:44 release
zk@jasonkay:/opt/elasticsearch-7.3.2$ ./jdk/bin/java -version
openjdk version "12.0.2" 2019-07-16
OpenJDK Runtime Environment (build 12.0.2+10)
OpenJDK 64-Bit Server VM (build 12.0.2+10, mixed mode, sharing)由上可见, ElasticSearch所带有的为OpenJDK12!
2. elasticsearch.yml配置文件详解
r/local/elasticsearch-7.0.0/config/elasticsearch.yml
cluster.name: ES-Cluster
#ES集群名称,同一个集群内的所有节点集群名称必须保持一致
node.name: ES-master-10.150.55.94
#ES集群内的节点名称,同一个集群内的节点名称要具备唯一性
node.master: true
#允许节点是否可以成为一个master节点,ES是默认集群中的第一台机器成为master,如果这台机器停止就会重新选举
node.data: false
#允许该节点存储索引数据(默认开启)
#关于Elasticsearch节点的角色功能详解,请看:https://www.dockerc.com/elasticsearch-master-or-data/
path.data: /data/ES-Cluster/master/ES-master-10.150.55.94/data1,/data/ES-Cluster/master/ES-master-10.150.55.94/data2
#ES是搜索引擎,会创建文档,建立索引,此路径是索引的存放目录,如果我们的日志数据较为庞大,那么索引所占用的磁盘空间也是不可小觑的
#这个路径建议是专门的存储系统,如果不是存储系统,最好也要有冗余能力的磁盘,此目录还要对elasticsearch的运行用户有写入权限
#path可以指定多个存储位置,分散存储,有助于性能提升,以至于怎么分散存储请看详解https://www.dockerc.com/elk-theory-elasticsearch/
path.logs: /data/ES-Cluster/master/ES-master-10.150.55.94/logs
#elasticsearch专门的日志存储位置,生产环境中建议elasticsearch配置文件与elasticsearch日志分开存储
bootstrap.memory_lock: true
#在ES运行起来后锁定ES所能使用的堆内存大小,锁定内存大小一般为可用内存的一半左右;锁定内存后就不会使用交换分区
#如果不打开此项,当系统物理内存空间不足,ES将使用交换分区,ES如果使用交换分区,那么ES的性能将会变得很差
network.host: 10.150.55.94
#es绑定地址,支持IPv4及IPv6,默认绑定127.0.0.1;es的HTTP端口和集群通信端口就会监听在此地址上
network.tcp.no_delay: true
#是否启用tcp无延迟,true为启用tcp不延迟,默认为false启用tcp延迟
network.tcp.keep_alive: true
#是否启用TCP保持活动状态,默认为true
network.tcp.reuse_address: true
#是否应该重复使用地址。默认true,在Windows机器上默认为false
network.tcp.send_buffer_size: 128mb
#tcp发送缓冲区大小,默认不设置
network.tcp.receive_buffer_size: 128mb
#tcp接收缓冲区大小,默认不设置
transport.tcp.port: 9301
#设置集群节点通信的TCP端口,默认就是9300
transport.tcp.compress: true
#设置是否压缩TCP传输时的数据,默认为false
http.max_content_length: 200mb
#设置http请求内容的最大容量,默认是100mb
http.cors.enabled: true
#是否开启跨域访问
http.cors.allow-origin: "*"
#开启跨域访问后的地址限制,*表示无限制
http.port: 9201
#定义ES对外调用的http端口,默认是9200
discovery.zen.ping.unicast.hosts: ["10.150.55.94:9301", "10.150.55.95:9301","10.150.30.246:9301"] #在Elasticsearch7.0版本已被移除,配置错误
#写入候选主节点的设备地址,来开启服务时就可以被选为主节点
#默认主机列表只有127.0.0.1和IPV6的本机回环地址
#上面是书写格式,discover意思为发现,zen是判定集群成员的协议,unicast是单播的意思,ES5.0版本之后只支持单播的方式来进行集群间的通信,hosts为主机
#总结下来就是:使用zen协议通过单播方式去发现集群成员主机,在此建议将所有成员的节点名称都写进来,这样就不用仅靠集群名称cluster.name来判别集群关系了
discovery.zen.minimum_master_nodes: 2 #在Elasticsearch7.0版本已被移除,配置无效
#为了避免脑裂,集群的最少节点数量为,集群的总节点数量除以2加一
discovery.zen.fd.ping_timeout: 120s #在Elasticsearch7.0版本已被移除,配置无效
#探测超时时间,默认是3秒,我们这里填120秒是为了防止网络不好的时候ES集群发生脑裂现象
discovery.zen.fd.ping_retries: 6 #在Elasticsearch7.0版本已被移除,配置无效
#探测次数,如果每次探测90秒,连续探测超过六次,则认为节点该节点已脱离集群,默认为3次
discovery.zen.fd.ping_interval: 15s #在Elasticsearch7.0版本已被移除,配置无效
#节点每隔15秒向master发送一次心跳,证明自己和master还存活,默认为1秒太频繁,
discovery.seed_hosts: ["10.150.55.94:9301", "10.150.55.95:9301","10.150.30.246:9301"]
#Elasticsearch7新增参数,写入候选主节点的设备地址,来开启服务时就可以被选为主节点,由discovery.zen.ping.unicast.hosts:参数改变而来
cluster.initial_master_nodes: ["10.150.55.94:9301", "10.150.55.95:9301","10.150.30.246:9301"]
#Elasticsearch7新增参数,写入候选主节点的设备地址,来开启服务时就可以被选为主节点
cluster.fault_detection.leader_check.interval: 15s
#Elasticsearch7新增参数,设置每个节点在选中的主节点的检查之间等待的时间。默认为1秒
discovery.cluster_formation_warning_timeout: 30s
#Elasticsearch7新增参数,启动后30秒内,如果集群未形成,那么将会记录一条警告信息,警告信息未master not fount开始,默认为10秒
cluster.join.timeout: 30s
#Elasticsearch7新增参数,节点发送请求加入集群后,在认为请求失败后,再次发送请求的等待时间,默认为60秒
cluster.publish.timeout: 90s
#Elasticsearch7新增参数,设置主节点等待每个集群状态完全更新后发布到所有节点的时间,默认为30秒
cluster.routing.allocation.cluster_concurrent_rebalance: 32
#集群内同时启动的数据任务个数,默认是2个
cluster.routing.allocation.node_concurrent_recoveries: 32
#添加或删除节点及负载均衡时并发恢复的线程个数,默认4个
cluster.routing.allocation.node_initial_primaries_recoveries: 32
#初始化数据恢复时,并发恢复线程的个数,默认4个
注意:关于Elasticsearch7更多配置参数请看官网:https://www.elastic.co/guide/en/elasticsearch/reference/master/modules-discovery-settings.html
关于Elasticsearch6到Elasticsearch7的区别请看:https://www.dockerc.com/elasticsearch7-coordination/
3. jvm.options配置文件详解
#堆内存配置
-Xms16g #Xms表示ES堆内存初始大小
-Xmx16g #Xmx表示ES堆内存的最大可用空间
#GC配置
-XX:+UseConcMarkSweepGC
#使用CMS内存收集
-XX:CMSInitiatingOccupancyFraction=75
#使用CMS作为垃圾回收使用,75%后开始CMS收集
-XX:+UseCMSInitiatingOccupancyOnly
#使用手动定义初始化开始CMS收集
......五. 其他配置
1. 创建elasticsearch用户组
elasticsearch默认是不能以root身份去运行的,否则启动会报错误信息为can not run elasticsearch as root Elasticsearch,所以我们要创建一个普通用户来管理elasticsearch!当然这也是elasticsearch为安全着想的一种方式
# 创建elasticsearch用户组
groupadd elasticsearch
useradd elasticsearch -g elasticsearch
echo '3edc#EDC' | passwd --stdin elasticsearch
Changing password for user elasticsearch.
passwd: all authentication tokens updated successfully.
# 更改elasticsearch属性
chown -Rf elasticsearch /usr/local/elasticsearch-7.0.0/2. 改文件描述符数量
因为elasticsearch对文件描述符的限制至少为65536,所以我们必须要修改系统的文件描述符数量
echo '* soft nofile 65536' >> /etc/security/limits.conf
echo '* hard nofile 65536' >> /etc/security/limits.conf
ulimit -n
65535
ulimit -n如果未生效,请重新登录设备,让用户重载环境变量3. 修改max_map_count值
在linux系统上,elasticsearch默认使用hybrid mmapfs / niofs来存储索引文件,因此操作系统主要会通过mmap来限制存储的空间,因此如果存储空间满了,那么会抛出异常,我们可以使用如下命令来更改设置。
# 临时设置:
sysctl -w vm.max_map_count=655360
vm.max_map_count = 655360
# 永久设置:
echo 'vm.max_map_count=655360' >> /etc/sysctl.conf
sysctl -p
vm.max_map_count = 6553604. 添加内存分配字段
当我们启动ES时,有可能会报错为无法分配内存字段
echo '* soft memlock unlimited' >> /etc/security/limits.conf
echo '* hard memlock unlimited' >> /etc/security/limits.conf
tail -2 /etc/security/limits.conf
* soft memlock unlimited
* hard memlock unlimited附录
文章参考:
- ElasticSearch学习–单机如何启动多节点集群
- ElasticSearch5.5.1 单台服务器部署多个节点
- ElasticSearch多节点模式的搭建
- 搭建elsticsearch集群 报错with the same id but is a different node instance解决办法
- Elasticsearch 6.0 命令行Option -E启动报错,求大佬指导,感谢
- Elasticsearch源码分析-启动过程浅析
- Elasticsearch 6.0 重大变化
- 官方文档6.2版本更新
- ES 7.4官方文档Configuring Elasticsearch
- 如何在ElasticSearch中有多个节点?
- 使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
- Elasticsearch 集群启动多节点 + 解决ES节点集群状态为yellow
- elasticsearch 7 单机配置
- curl命令操作ElasticSearch总结
- Install Elasticsearch with Docker
- docker安装elasticsearch5.0和6.0容器自动关闭问题–解决
- Elasticsearch7.x版本集群部署-疲惫的后生-51CTO博客