
最近在学习新的编程语言Scala了, 在Scala中变量分为val(不可变类型), 和var(可变类型). 突发奇想想到了在Java中的String都被声明为final, 也就相当于是Scala中都被声明为val了吧! 但是具体是为什么呢? 本篇文章带你探寻在Java中String被声明为不可变背后的秘密!
本篇文章主要内容:
- String源码简单分析
- String在JVM中的常量池的解析: 字面量, new, +连接, intern()
- String中的==和equals
- 什么是Java中的不可变? 不可变的好处与坏处?
- 证明回答String被设计成不可变和不能被继承的原因
- ……
示例代码: https://github.com/JasonkayZK/Java_Samples/tree/java-string
为什么在Java中String被设计为不可变
零. 窥探java.lang.String源码
下面是String在JDK11中的源码:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** The offset is the first index of the storage that is used. */
private final int offset;
/** The count is the number of characters in the String. */
private final int count;
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
.....
}接下来看看String类实现的接口:
java.io.Serializable: 这个序列化接口仅用于标识序列化的语意;Comparable<String>: 这个compareTo(T 0)接口用于对两个实例化对象比较大小;CharSequence: 这个接口是一个只读的字符序列. 包括length(), charAt(int index), subSequence(int start, int end)这几个API接口; 值得一提的是,StringBuffer和StringBuild也是实现了改接口;
最后看看String的成员属性:
value[] :char数组用于储存String的内容;
offset :存储的第一个索引;
count :字符串中的字符数;
hash :String实例化的hashcode的一个缓存,String的哈希码被频繁使用,将其缓存起来,每次使用就没必要再次去计算,这也是一种性能优化的手段。这也是String被设计为不可变的原因之一!
通过源码可以得出下面几个信息:
- String类是用final修饰的,这意味着String不能被继承,而且所有的成员方法都默认为final方法!
- String底层还是通过char数组构成的, 我们创建一个宇符串对象的时候, 其实是将字符串保存在char数组中;
- 由于数组是引用对象,为了防止数组可变, jdk加了final 修饰. 但是加了final修饰的数组只是代表了引用不可变,不代表数组的内容不可变!
- 因此, jdk为了真正防止不可变, 又加了一个private修饰符;
下面是一个String类的一个方法实现:
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
} else {
int subLen = this.length() - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
} else if (beginIndex == 0) {
return this;
} else {
return this.isLatin1() ? StringLatin1.newString(this.value, beginIndex, subLen) : StringUTF16.newString(this.value, beginIndex, subLen);
}
}
}可以发现,类似于Scala中定义的val集合. 最初传入的String并没有改变,其返回的是一个new String(),即新创建的String对象. 其实String类的其他方法也是如此,并不会改变原字符串. 这也是String的不可变性!
一. 分析JVM内存模型
说到 String不得不提字符串常量池, 字符串常量池主要存储在方法区中当一个字符串被创建的时候,首先会去常量池中查找,如果找到了就返回对改字符串的引用,如果没找到就创建这个字符串并塞到常量池中.
字符串常量池的存在使JVM提高了性能和减少了内存开销!
注:jdk7之前是常量池是在方法区(永久代)中,之后则移到了堆中!
使用字符串常量池,每当我们使用字面量String s="1";创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么就将此字符串对象的地址赋值给引用s(引用s在Java栈中)。如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中,并将此字符串对象的地址赋值给引用s(引用s在Java栈中)。
使用字符串常量池,每当我们使用关键字new String s = new String("1");创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么不再在字符串常量池创建该字符串对象,而直接堆中复制该对象的副本,然后将堆中对象的地址赋值给引用s,如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中,然后在堆中复制该对象的副本,然后将堆中对象的地址赋值给引用s.
例如: 下面的代码只会在堆中创建一个字符串:
String s1 = "abc";
String s2 = "abc";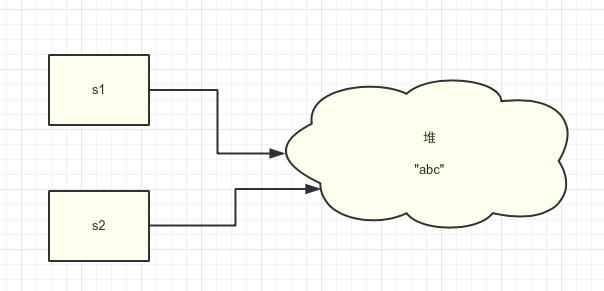
需要注意的是:
通过显式声明的字符常量会被保存在常量池中, 例如: 有String m = "abc", 之后在其之后拼写一个d, 即m = m + 'd', 拼接成一个新的字符串常量. 这时候就会在常量池中创建三个字符串常量,也就是说,这三个字符串常量就是adc、和我们拼接的d,和拼接之后adcd, 所以说非常消耗内存的!
而new 出来的String对象则存在于堆中,比如: String str = new String("abc");. 这里的adc存在于常量池里,而new String(“adc”);则存在于堆中,如果说再创建一个String str2 = new String(“abc”); 因为adc存在于常量池里,所以不会再创建一个新的abc,而new String (“adc”)对象则会在堆中重新创建一个!
如下面的例子:
package string.memoryStructure;
public class StringCompare {
public static void main(String[] args) {
// 这里的abc是显式字符串常量,存在于常量池里
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2);
// 这里的abc是常量,存在于常量池,而new String(“abc”)是对象存在于堆中!!!
String s3 = new String("abc");
System.out.println(s1 == s3);
}
}
最终程序输出的结果是:
true
false总结: 不管是创建String 对象还是创建字符串常量,只要你在后面拼接都会在常量池中创建新的字符串常量!所以说使用String进行拼接的话是很消耗内存的,String则适合少量数据的展示, 要频繁拼接字符串请使用StringBuilder(非线程安全)或者StringBuffer(线程安全)
二. Srtring在JVM层解析详述
1. 创建字符串形式
首先形如声明为S ss是一个类S的引用变量ss(我们常常称之为句柄), 而对象一般通过new创建。所以这里的ss仅仅是引用变量,并不是对象!
创建字符串的两种基本形式:
String s1 = "1";
String s2 = new String("1");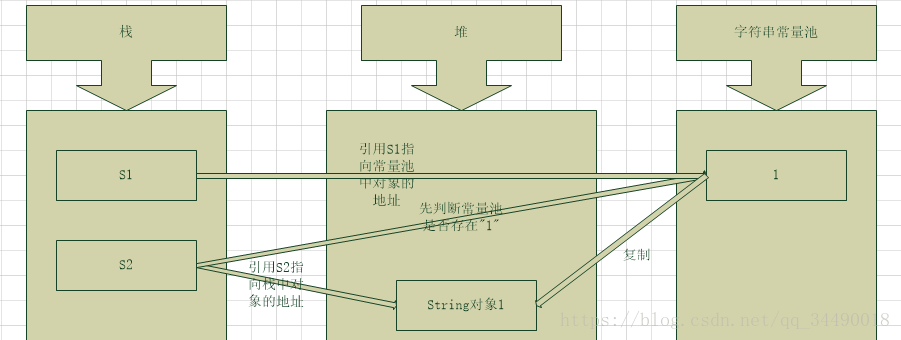
从图中可以看出,s1使用" "引号(也是平时所说的字面量)创建字符串. 在编译期的时候就对常量池进行判断是否存在该字符串,如果存在则不创建直接返回对象的引用;如果不存在,则先在常量池中创建该字符串实例再返回实例的引用给s1. 注意:编译期的常量池是静态常量池!
再来看看s2,s2使用关键词new创建字符串,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么不再在字符串常量池创建该字符串对象,而直接堆中复制该对象的副本,然后将堆中对象的地址赋值给引用s2,如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中,然后在堆中复制该对象的副本,然后将堆中对象的地址赋值给引用s2. 注意:此时是运行期,那么字符串常量池是在运行时常量池中的!
2. + 连接形式创建字符串
String s1 = "1" + "2" + "3":
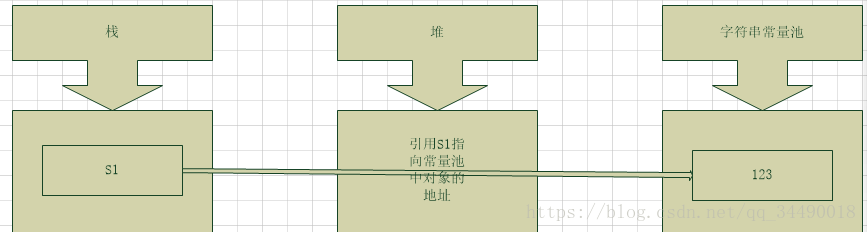
使用包含常量的字符串连接创建是也是常量,编译期就能确定了,直接入字符串常量池,当然同样需要判断是否已经存在该字符串!
String s2 = "1" + "3" + new String("1") + "4"
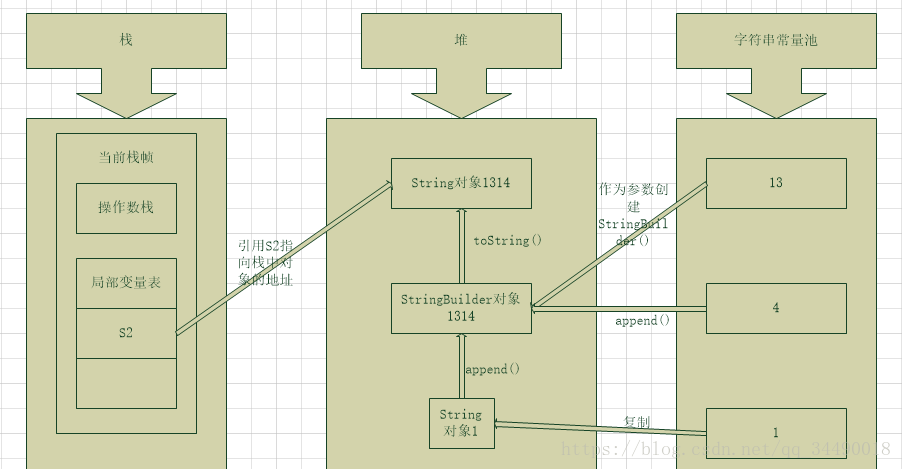
当使用+连接字符串中含有变量时,也是在运行期才能确定的!
首先连接操作最开始时如果都是字符串常量,编译后将尽可能多的字符串常量连接在一起,形成新的字符串常量参与后续的连接(可通过反编译工具jd-gui进行查看)
接下来的字符串连接是从左向右依次进行,对于不同的字符串,首先以最左边的字符串为参数创建StringBuilder对象(可变字符串对象),然后依次对右边进行append操作,最后将StringBuilder对象通过toString()方法转换成String对象(注意: 中间的多个字符串常量不会自动拼接)
实际上的实现过程为:String s2=new StringBuilder(“13”).append(new String(“1”)).append(“4”).toString();
当使用+进行多个字符串连接时,实际上是产生了一个StringBulder对象和一个String对象!
String s3 = new String("1") + new String("1");
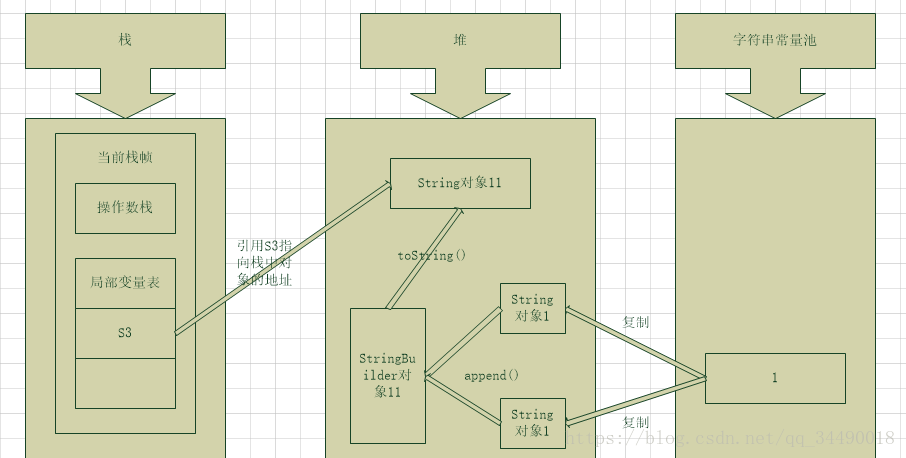
这个过程跟上一例类似.
3. String.intern()解析
String.intern()是一个Native方法, 底层调用C++的 StringTable::intern 方法.
当调用 intern 方法时,如果常量池中已经该字符串,则返回池中的字符串;否则将此字符串添加到常量池中,并返回字符串的引用。
下面举一个例子:
package string.intern;
public class InternDemo {
public static void main(String[] args) {
String s = new String("1") + new String("1");
System.out.println(s == s.intern());
}
}
JDK6的执行结果为:false
而JDK7和JDK8的执行结果为:true
JDK6的内存模型如下:
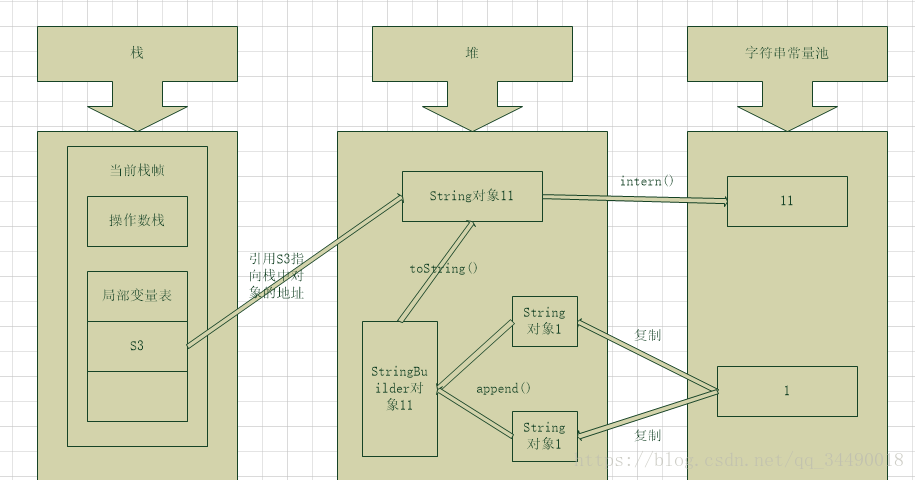
我们都知道JDK6中的常量池是放在永久代的,永久代和Java堆是两个完全分开的区域。而使用+连接而来的的对象会存在Java堆中,且并未将对象存于常量池中,当调用 intern 方法时,如果常量池中已经该字符串,则返回池中的字符串;否则将此字符串添加到常量池中,并返回字符串的引用。所以结果为false。
JDK7JDK8的内存模型如下:
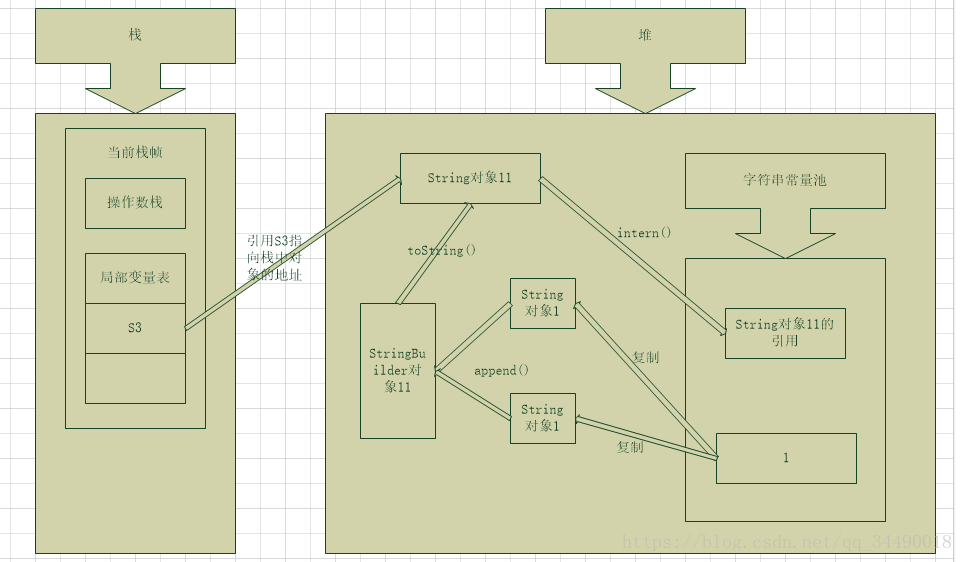
JDK7中,字符串常量池已经被转移至Java堆中,开发人员也对intern方法做了一些修改。因为字符串常量池和new的对象都存于Java堆中,为了优化性能和减少内存开销,当调用 intern 方法时,如果常量池中已经存在该字符串,则返回池中字符串;否则直接存储堆中的引用,也就是字符串常量池中存储的是指向堆里的对象。所以结果为true。
三. String典型案例: equals和==
- 对于
==: 如果作用于基本数据类型的变量byte,short,char,int,long,float,double,boolean,则直接比较其存储的”值”是否相等;如果作用于引用类型的变量(String),则比较的是所指向的对象的地址(即是否指向同一个对象); - equals方法是基类Object中的方法,因此对于所有的继承于Object的类都会有该方法。在Object类中,equals方法是用来比较两个对象的引用是否相等
注意: equals方法不能作用于基本数据类型的变量。如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;而String类对equals方法进行了重写,用来比较指向的字符串对象所存储的字符串是否相等。其他的一些类诸如Double,Date,Integer等,都对equals方法进行了重写用来比较指向的对象所存储的内容是否相等。
小技巧: 在阿里的Java规范中提出使用
"Content".equals(str)来比较两个字符串, 即常量.equals(str)的方式. 这样可以避免NPE!
一些关于String的例子:
package string.examples;
public class StringDemo {
public static void main(String[] args) {
/**
* 情景一:字符串池
* JAVA虚拟机(JVM)中存在着一个字符串池,其中保存着很多String对象;
* 并且可以被共享使用,因此它提高了效率。
* 由于String类是final的,它的值一经创建就不可改变。
* 字符串池由String类维护,我们可以调用intern()方法来访问字符串池。
*/
String s1 = "abc";
//↑ 在字符串池创建了一个对象
String s2 = "abc";
//↑ 字符串pool已经存在对象“abc”(共享),所以创建0个对象,累计创建一个对象
System.out.println("s1 == s2 : "+(s1 == s2));
//↑ true 指向同一个对象,
System.out.println("s1.equals(s2) : " + (s1.equals(s2)));
//↑ true 值相等
//↑------------------------------------------------------over
/**
* 情景二:关于new String("")
*
*/
String s3 = new String("abc");
//↑ 创建了两个对象,一个存放在字符串池中,一个存在与堆区中;
//↑ 还有一个对象引用s3存放在栈中
String s4 = new String("abc");
//↑ 字符串池中已经存在“abc”对象,所以只在堆中创建了一个对象
System.out.println("s3 == s4 : "+(s3 == s4));
//↑false s3和s4栈区的地址不同,指向堆区的不同地址;
System.out.println("s3.equals(s4) : " + (s3.equals(s4)));
//↑true s3和s4的值相同
System.out.println("s1 == s3 : " + (s1 == s3));
//↑false 存放的地区多不同,一个栈区,一个堆区
System.out.println("s1.equals(s3) : " + (s1.equals(s3)));
//↑true 值相同
/**
* 情景三:
* 由于常量的值在编译的时候就被确定(优化)了。
* 在这里,"ab"和"cd"都是常量,因此变量str3的值在编译时就可以确定。
* 这行代码编译后的效果等同于: String str3 = "abcd";
*/
String str1 = "ab" + "cd"; // 1个对象
String str11 = "abcd";
System.out.println("str1 = str11 : "+ (str1 == str11));
/**
* 情景四:
* 局部变量str2,str3存储的是存储两个拘留字符串对象(intern字符串对象)的地址。
*
* 第三行代码原理(str2+str3):
* 运行期JVM首先会在堆中创建一个StringBuilder类,
* 同时用str2指向的拘留字符串对象完成初始化,
* 然后调用append方法完成对str3所指向的拘留字符串的合并,
* 接着调用StringBuilder的toString()方法在堆中创建一个String对象,
* 最后将刚生成的String对象的堆地址存放在局部变量str4中。
*
* 而str5存储的是字符串池中"abcd"所对应的拘留字符串对象的地址。
* str4与str5地址当然不一样了。
*
* 内存中实际上有五个字符串对象:
* 三个拘留字符串对象、一个String对象和一个StringBuilder对象。
*/
String str2 = "ab"; //1个对象
String str3 = "cd"; //1个对象
String str4 = str2 + str3;
String str5 = "abcd";
System.out.println("str4 = str5 : " + (str4 == str5)); // false
/**
* 情景五:
* JAVA编译器对string + 基本类型/常量 是当成常量表达式直接求值来优化的。
* 运行期的两个string相加,会产生新的对象的,存储在堆(heap)中
*/
String str6 = "b";
String str7 = "a" + str6;
String str67 = "ab";
System.out.println("str7 = str67 : "+ (str7 == str67));
//↑str6为变量,在运行期才会被解析
final String str8 = "b";
String str9 = "a" + str8;
String str89 = "ab";
System.out.println("str9 = str89 : "+ (str9 == str89));
//↑str8为常量变量,编译期会被优化
}
}
输出为:
s1 == s2 : true
s1.equals(s2) : true
s3 == s4 : false
s3.equals(s4) : true
s1 == s3 : false
s1.equals(s3) : true
str1 = str11 : true
str4 = str5 : false
str7 = str67 : false
str9 = str89 : true四. 什么是不可变?
对于Java而言,除了基本类型(即int, long, double等),其余的都是对象。对于何为不可变对象,《java concurrency in practice》一书给出了一个粗略的定义:对象一旦创建后,其状态不可修改,则该对象为不可变对象。
一般一个对象满足以下三点,则可以称为是不可变对象:
- 其状态不能在创建后再修改;
- 所有域都是final类型;
- 其构造函数构造对象期间,this引用没有泄露;
这里重点说明一下第2点, 一个对象其所有域都是final类型,该对象也可能是可变对象! 因为final关键字只是限制对象的域的引用不可变,但无法限制通过该引用去修改其对应域的内部状态。因此,严格意义上的不可变对象,其final关键字修饰的域应该也是不可变对象和primitive type值。
从技术上讲,不可变对象内部域并不一定全都声明为final类型,String类型即是如此。在String对象的内部我们可以看到有一个名为hash的域并不是final类型,这是因为String类型惰性计算hashcode并存储在hash域中(这是通过其他final类型域来保证每次的hashcode计算结果必定是相同的)
除此之外,String对象的不可变是由于对String类型的所有改变内部存储结构的操作都会new出一个新的String对象
不可变带来的好处
变量设计成不可变,带来的好处有以下几点:
安全性
多线程安全性: 因为String是不可变的,因此在多线程操作下,它是安全的,我们看下如下代码:
public String get (String str) { str = "aaa"; return str; }试想一下如果String是可变的,那么get方法内部改变了str的值,方法外部str也会随之改变!
类加载中体现的安全性: 类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载。譬如你想加载
java.sql.Connection类,而这个值被改成了hacked.Connection,那么会对你的数据库造成不可知的破坏!
使用常量池节省空间
只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。但如果字符串是可变的,那么String interning将不能实现(String interning是指对不同的字符串仅仅只保存一个,即不会保存多个相同的字符串),因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。
缓存hashcode
因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
我们可以看到String中有如下代码:
private int hash;以上代码中hash变量中就保存了一个String对象的hashcode,因为String类不可变,所以一旦对象被创建,该hash值也无法改变。所以,每次想要使用该对象的hashcode的时候,直接返回即可。
不可变带来的缺点
不可变对象也有一个缺点就是会制造大量垃圾,由于他们不能被重用而且对于它们的使用就是”用”然后”扔”,字符串就是一个典型的例子,它会创造很多的垃圾,给垃圾收集带来很大的麻烦。当然这只是个极端的例子,合理的使用不可变对象会创造很大的价值。
注意: 密码应该存放在字符数组中而不是String中
由于String在Java中是不可变的,如果你将密码以明文的形式保存成字符串,那么它将一直留在内存中,直到垃圾收集器把它清除。而由于字符串被放在字符串缓冲池中以方便重复使用,所以它就可能在内存中被保留很长时间,而这将导致安全隐患,因为任何能够访问内存(memory dump内存转储)的人都能清晰的看到文本中的密码,这也是为什么你应该总是使用加密的形式而不是明文来保存密码。
由于字符串是不可变的,所以没有任何方式可以修改字符串的值,因为每次修改都将产生新的字符串,然而如果你使用char[]来保存密码,你仍然可以将其中所有的元素都设置为空或者零。所以将密码保存到字符数组中很明显的降低了密码被窃取的风险。
当然只使用字符数组也是不够的,为了更安全你需要将数组内容进行转化。 建议使用哈希的或者是加密过的密码而不是明文,然后一旦完成验证,就将它从内存中清除掉。
五. String被设计成不可变和不能被继承的原因
经过了以上关于String知识的积累, 下面来总结性的回答String在Java中被设计为不可变和不能被继承的原因.
String是不可变和不能被继承的(final修饰),这样设计的原因主要是为了设计考虑、效率和安全性
1. 字符串常量池的需要
只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。假若字符串对象允许改变,那么将会导致各种逻辑错误,比如改变一个对象会影响到另一个独立对象. 严格来说,这种常量池的思想,是一种优化手段。
2. String对象缓存HashCode
上面解析String类的源码的时候已经提到了HashCode。Java中的String对象的哈希码被频繁地使用,字符串的不可变性保证了hash码的唯一性。
3. 安全性
首先String被许多Java类用来当参数,如果字符串可变,那么会引起各种严重错误和安全漏洞。
再者String作为核心类,很多的内部方法的实现都是本地调用的,即调用操作系统本地API,其和操作系统交流频繁,假如这个类被继承重写的话,难免会是操作系统造成巨大的隐患。
最后字符串的不可变性使得同一字符串实例被多个线程共享,所以保障了多线程的安全性。而且类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载。
附录
文章参考:
示例代码: https://github.com/JasonkayZK/Java_Samples/tree/java-string